 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUI-Mem: Self-Evolving Experience Memory for Online Reinforcement Learning in Mobile GUI Agents
Feb 05, 2026Online Reinforcement Learning (RL) offers a promising paradigm for enhancing GUI agents through direct environment interaction. However, its effectiveness is severely hindered by inefficient credit assignment in long-horizon tasks and repetitive errors across tasks due to the lack of experience transfer. To address these challenges, we propose UI-Mem, a novel framework that enhances GUI online RL with a Hierarchical Experience Memory. Unlike traditional replay buffers, our memory accumulates structured knowledge, including high-level workflows, subtask skills, and failure patterns. These experiences are stored as parameterized templates that enable cross-task and cross-application transfer. To effectively integrate memory guidance into online RL, we introduce Stratified Group Sampling, which injects varying levels of guidance across trajectories within each rollout group to maintain outcome diversity, driving the unguided policy toward internalizing guided behaviors. Furthermore, a Self-Evolving Loop continuously abstracts novel strategies and errors to keep the memory aligned with the agent's evolving policy. Experiments on online GUI benchmarks demonstrate that UI-Mem significantly outperforms traditional RL baselines and static reuse strategies, with strong generalization to unseen applications. Project page: https://ui-mem.github.io
ContextBench: A Benchmark for Context Retrieval in Coding Agents
Feb 05, 2026LLM-based coding agents have shown strong performance on automated issue resolution benchmarks, yet existing evaluations largely focus on final task success, providing limited insight into how agents retrieve and use code context during problem solving. We introduce ContextBench, a process-oriented evaluation of context retrieval in coding agents. ContextBench consists of 1,136 issue-resolution tasks from 66 repositories across eight programming languages, each augmented with human-annotated gold contexts. We further implement an automated evaluation framework that tracks agent trajectories and measures context recall, precision, and efficiency throughout issue resolution. Using ContextBench, we evaluate four frontier LLMs and five coding agents. Our results show that sophisticated agent scaffolding yields only marginal gains in context retrieval ("The Bitter Lesson" of coding agents), LLMs consistently favor recall over precision, and substantial gaps exist between explored and utilized context. ContextBench augments existing end-to-end benchmarks with intermediate gold-context metrics that unbox the issue-resolution process. These contexts offer valuable intermediate signals for guiding LLM reasoning in software tasks. Data and code are available at: https://cioutn.github.io/context-bench/.
CodeDelegator: Mitigating Context Pollution via Role Separation in Code-as-Action Agents
Jan 21, 2026Recent advances in large language models (LLMs) allow agents to represent actions as executable code, offering greater expressivity than traditional tool-calling. However, real-world tasks often demand both strategic planning and detailed implementation. Using a single agent for both leads to context pollution from debugging traces and intermediate failures, impairing long-horizon performance. We propose CodeDelegator, a multi-agent framework that separates planning from implementation via role specialization. A persistent Delegator maintains strategic oversight by decomposing tasks, writing specifications, and monitoring progress without executing code. For each sub-task, a new Coder agent is instantiated with a clean context containing only its specification, shielding it from prior failures. To coordinate between agents, we introduce Ephemeral-Persistent State Separation (EPSS), which isolates each Coder's execution state while preserving global coherence, preventing debugging traces from polluting the Delegator's context. Experiments on various benchmarks demonstrate the effectiveness of CodeDelegator across diverse scenarios.
An Intention-driven Lane Change Framework Considering Heterogeneous Dynamic Cooperation in Mixed-traffic Environment
Sep 26, 2025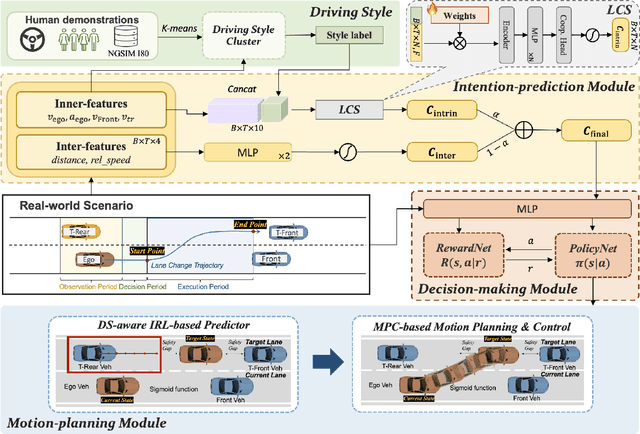
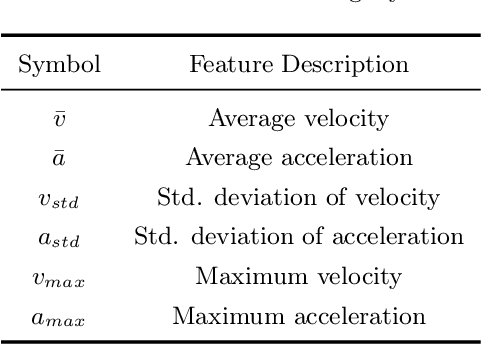
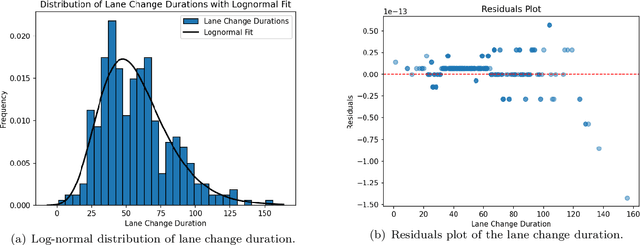
In mixed-traffic environments, where autonomous vehicles (AVs) interact with diverse human-driven vehicles (HVs), unpredictable intentions and heterogeneous behaviors make safe and efficient lane change maneuvers highly challenging. Existing methods often oversimplify these interactions by assuming uniform patterns. We propose an intention-driven lane change framework that integrates driving-style recognition, cooperation-aware decision-making, and coordinated motion planning. A deep learning classifier trained on the NGSIM dataset identifies human driving styles in real time. A cooperation score with intrinsic and interactive components estimates surrounding drivers' intentions and quantifies their willingness to cooperate with the ego vehicle. Decision-making combines behavior cloning with inverse reinforcement learning to determine whether a lane change should be initiated. For trajectory generation, model predictive control is integrated with IRL-based intention inference to produce collision-free and socially compliant maneuvers. Experiments show that the proposed model achieves 94.2\% accuracy and 94.3\% F1-score, outperforming rule-based and learning-based baselines by 4-15\% in lane change recognition. These results highlight the benefit of modeling inter-driver heterogeneity and demonstrate the potential of the framework to advance context-aware and human-like autonomous driving in complex traffic environments.
VPGS-SLAM: Voxel-based Progressive 3D Gaussian SLAM in Large-Scale Scenes
May 25, 2025



3D Gaussian Splatting has recently shown promising results in dense visual SLAM. However, existing 3DGS-based SLAM methods are all constrained to small-room scenarios and struggle with memory explosion in large-scale scenes and long sequences. To this end, we propose VPGS-SLAM, the first 3DGS-based large-scale RGBD SLAM framework for both indoor and outdoor scenarios. We design a novel voxel-based progressive 3D Gaussian mapping method with multiple submaps for compact and accurate scene representation in large-scale and long-sequence scenes. This allows us to scale up to arbitrary scenes and improves robustness (even under pose drifts). In addition, we propose a 2D-3D fusion camera tracking method to achieve robust and accurate camera tracking in both indoor and outdoor large-scale scenes. Furthermore, we design a 2D-3D Gaussian loop closure method to eliminate pose drift. We further propose a submap fusion method with online distillation to achieve global consistency in large-scale scenes when detecting a loop. Experiments on various indoor and outdoor datasets demonstrate the superiority and generalizability of the proposed framework. The code will be open source on https://github.com/dtc111111/vpgs-slam.
Improving Indoor Localization Accuracy by Using an Efficient Implicit Neural Map Representation
Mar 30, 2025Globally localizing a mobile robot in a known map is often a foundation for enabling robots to navigate and operate autonomously. In indoor environments, traditional Monte Carlo localization based on occupancy grid maps is considered the gold standard, but its accuracy is limited by the representation capabilities of the occupancy grid map. In this paper, we address the problem of building an effective map representation that allows to accurately perform probabilistic global localization. To this end, we propose an implicit neural map representation that is able to capture positional and directional geometric features from 2D LiDAR scans to efficiently represent the environment and learn a neural network that is able to predict both, the non-projective signed distance and a direction-aware projective distance for an arbitrary point in the mapped environment. This combination of neural map representation with a light-weight neural network allows us to design an efficient observation model within a conventional Monte Carlo localization framework for pose estimation of a robot in real time. We evaluated our approach to indoor localization on a publicly available dataset for global localization and the experimental results indicate that our approach is able to more accurately localize a mobile robot than other localization approaches employing occupancy or existing neural map representations. In contrast to other approaches employing an implicit neural map representation for 2D LiDAR localization, our approach allows to perform real-time pose tracking after convergence and near real-time global localization. The code of our approach is available at: https://github.com/PRBonn/enm-mcl.
FastCuRL: Curriculum Reinforcement Learning with Progressive Context Extension for Efficient Training R1-like Reasoning Models
Mar 21, 2025In this paper, we propose \textbf{\textsc{FastCuRL}}, a simple yet efficient \textbf{Cu}rriculum \textbf{R}einforcement \textbf{L}earning approach with context window extending strategy to accelerate the reinforcement learning training efficiency for R1-like reasoning models while enhancing their performance in tackling complex reasoning tasks with long chain-of-thought rationales, particularly with a 1.5B parameter language model. \textbf{\textsc{FastCuRL}} consists of two main procedures: length-aware training data segmentation and context window extension training. Specifically, the former first splits the original training data into three different levels by the input prompt length, and then the latter leverages segmented training datasets with a progressively increasing context window length to train the reasoning model. Experimental results demonstrate that \textbf{\textsc{FastCuRL}}-1.5B-Preview surpasses DeepScaleR-1.5B-Preview across all five datasets (including MATH 500, AIME 2024, AMC 2023, Minerva Math, and OlympiadBench) while only utilizing 50\% of training steps. Furthermore, all training stages for FastCuRL-1.5B-Preview are completed using just a single node with 8 GPUs.
PINGS: Gaussian Splatting Meets Distance Fields within a Point-Based Implicit Neural Map
Feb 09, 2025Robots require high-fidelity reconstructions of their environment for effective operation. Such scene representations should be both, geometrically accurate and photorealistic to support downstream tasks. While this can be achieved by building distance fields from range sensors and radiance fields from cameras, the scalable incremental mapping of both fields consistently and at the same time with high quality remains challenging. In this paper, we propose a novel map representation that unifies a continuous signed distance field and a Gaussian splatting radiance field within an elastic and compact point-based implicit neural map. By enforcing geometric consistency between these fields, we achieve mutual improvements by exploiting both modalities. We devise a LiDAR-visual SLAM system called PINGS using the proposed map representation and evaluate it on several challenging large-scale datasets. Experimental results demonstrate that PINGS can incrementally build globally consistent distance and radiance fields encoded with a compact set of neural points. Compared to the state-of-the-art methods, PINGS achieves superior photometric and geometric rendering at novel views by leveraging the constraints from the distance field. Furthermore, by utilizing dense photometric cues and multi-view consistency from the radiance field, PINGS produces more accurate distance fields, leading to improved odometry estimation and mesh reconstruction.
ActiveGS: Active Scene Reconstruction using Gaussian Splatting
Dec 23, 2024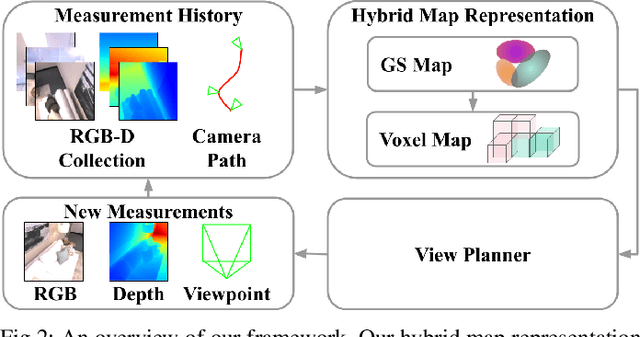
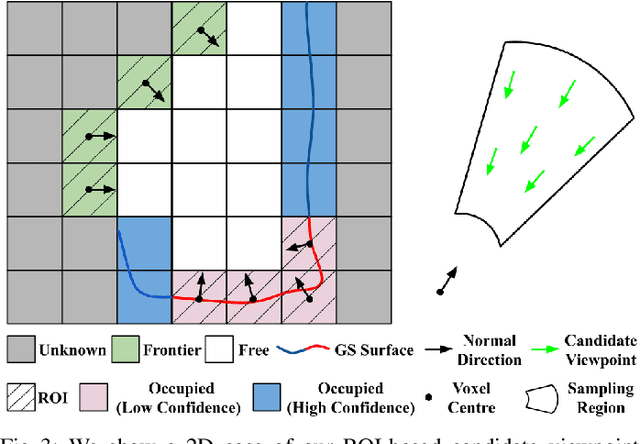
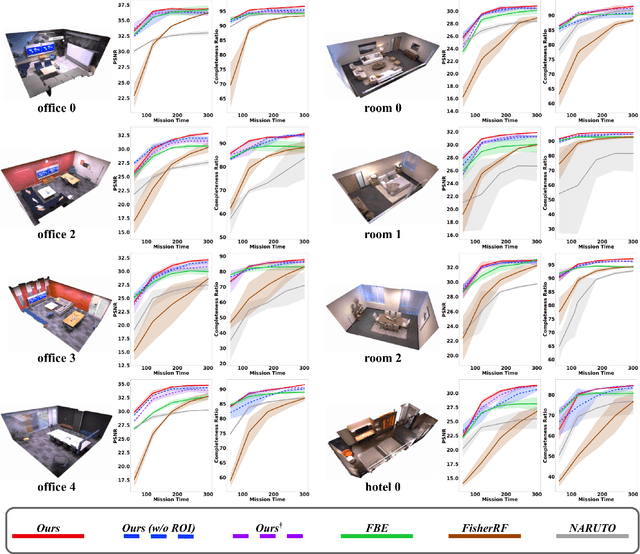

Robotics applications often rely on scene reconstructions to enable downstream tasks. In this work, we tackle the challenge of actively building an accurate map of an unknown scene using an on-board RGB-D camera. We propose a hybrid map representation that combines a Gaussian splatting map with a coarse voxel map, leveraging the strengths of both representations: the high-fidelity scene reconstruction capabilities of Gaussian splatting and the spatial modelling strengths of the voxel map. The core of our framework is an effective confidence modelling technique for the Gaussian splatting map to identify under-reconstructed areas, while utilising spatial information from the voxel map to target unexplored areas and assist in collision-free path planning. By actively collecting scene information in under-reconstructed and unexplored areas for map updates, our approach achieves superior Gaussian splatting reconstruction results compared to state-of-the-art approaches. Additionally, we demonstrate the applicability of our active scene reconstruction framework in the real world using an unmanned aerial vehicle.
DuA: Dual Attentive Transformer in Long-Term Continuous EEG Emotion Analysis
Jul 30, 2024
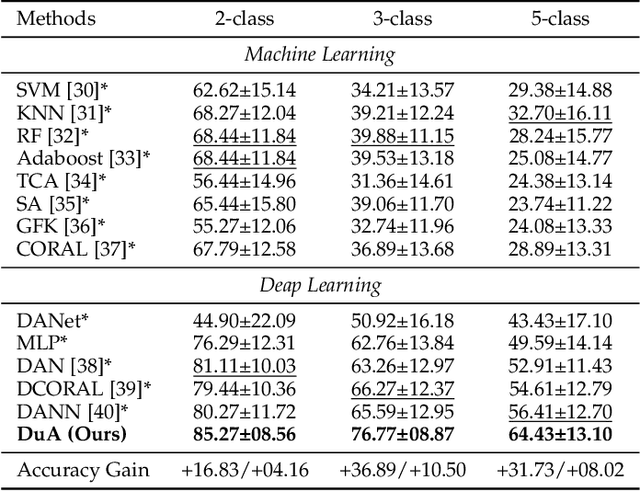
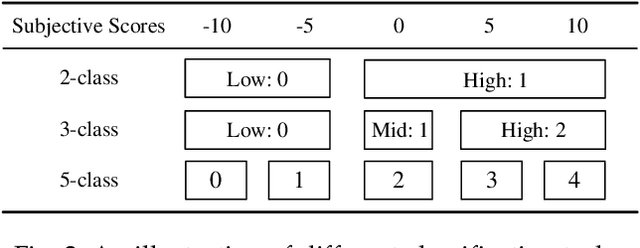

Affective brain-computer interfaces (aBCIs) are increasingly recognized for their potential in monitoring and interpreting emotional states through electroencephalography (EEG) signals. Current EEG-based emotion recognition methods perform well with short segments of EEG data. However, these methods encounter significant challenges in real-life scenarios where emotional states evolve over extended periods. To address this issue, we propose a Dual Attentive (DuA) transformer framework for long-term continuous EEG emotion analysis. Unlike segment-based approaches, the DuA transformer processes an entire EEG trial as a whole, identifying emotions at the trial level, referred to as trial-based emotion analysis. This framework is designed to adapt to varying signal lengths, providing a substantial advantage over traditional methods. The DuA transformer incorporates three key modules: the spatial-spectral network module, the temporal network module, and the transfer learning module. The spatial-spectral network module simultaneously captures spatial and spectral information from EEG signals, while the temporal network module detects temporal dependencies within long-term EEG data. The transfer learning module enhances the model's adaptability across different subjects and conditions. We extensively evaluate the DuA transformer using a self-constructed long-term EEG emotion database, along with two benchmark EEG emotion databases. On the basis of the trial-based leave-one-subject-out cross-subject cross-validation protocol, our experimental results demonstrate that the proposed DuA transformer significantly outperforms existing methods in long-term continuous EEG emotion analysis, with an average enhancement of 5.28%.