 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPPI-based Informative Trajectory Planning for Search and Capture of Drifting Targets with ASVs
Jun 10, 2026Autonomous surface vehicles offer an efficient solution for environmental cleanup as well as search and rescue operations in open waters. Targets in these settings drift continuously, so efficient search must balance exploration of unobserved regions with tracking of known targets. However, most target tracking and pursuit scenarios consider simple guidance behaviours and short-term predictions for decision-making. In this letter, we address the problem of search and capture of multiple drifting targets, such as litter, in dynamic environments, using a hybrid planning framework. A key aspect of our strategy is a spatiotemporal informative planning method based on model predictive path integral (MPPI) control, a sampling-based model predictive control approach. The planner directly generates kinematic-level commands by optimising continuous trajectories over long horizons. A multi-objective cost balances search and tracking objectives while ensuring safe, feasible trajectories. In the interception stage, we switch to a pure pursuit guidance controller for the physical capture of moving targets. Experiments show that our planner outperforms the chosen planning baselines. Finally, we validate our approach in field trials with an ASV.
EAAE: Energy-Aware Autonomous Exploration for UAVs in Unknown 3D Environments
Mar 16, 2026Battery-powered multirotor unmanned aerial vehicles (UAVs) can rapidly map unknown environments, but mission performance is often limited by energy rather than geometry alone. Standard exploration policies that optimise for coverage or time can therefore waste energy through manoeuvre-heavy trajectories. In this paper, we address energy-aware autonomous 3D exploration for multirotor UAVs in initially unknown environments. We propose Energy-Aware Autonomous Exploration (EAAE), a modular frontier-based framework that makes energy an explicit decision variable during frontier selection. EAAE clusters frontiers into view-consistent regions, plans dynamically feasible candidate trajectories to the most informative clusters, and predicts their execution energy using an offline power estimation loop. The next target is then selected by minimising predicted trajectory energy while preserving exploration progress through a dual-layer planning architecture for safe execution. We evaluate EAAE in a full exploration pipeline with a rotor-speed-based power model across simulated 3D environments of increasing complexity. Compared to representative distance-based and information gain-based frontier baselines, EAAE consistently reduces total energy consumption while maintaining competitive exploration time and comparable map quality, providing a practical drop-in energy-aware layer for frontier exploration.
Perception-Aware Autonomous Exploration in Feature-Limited Environments
Mar 16, 2026Autonomous exploration in unknown environments typically relies on onboard state estimation for localisation and mapping. Existing exploration methods primarily maximise coverage efficiency, but often overlook that visual-inertial odometry (VIO) performance strongly depends on the availability of robust visual features. As a result, exploration policies can drive a robot into feature-sparse regions where tracking degrades, leading to odometry drift, corrupted maps, and mission failure. We propose a hierarchical perception-aware exploration framework for a stereo-equipped unmanned aerial vehicle (UAV) that explicitly couples exploration progress with feature observability. Our approach (i) associates each candidate frontier with an expected feature quality using a global feature map, and prioritises visually informative subgoals, and (ii) optimises a continuous yaw trajectory along the planned motion to maintain stable feature tracks. We evaluate our method in simulation across environments with varying texture levels and in real-world indoor experiments with largely textureless walls. Compared to baselines that ignore feature quality and/or do not optimise continuous yaw, our method maintains more reliable feature tracking, reduces odometry drift, and achieves on average 30\% higher coverage before the odometry error exceeds specified thresholds.
Semantic Landmark Particle Filter for Robot Localisation in Vineyards
Mar 11, 2026Reliable localisation in vineyards is hindered by row-level perceptual aliasing: parallel crop rows produce nearly identical LiDAR observations, causing geometry-only and vision-based SLAM systems to converge towards incorrect corridors, particularly during headland transitions. We present a Semantic Landmark Particle Filter (SLPF) that integrates trunk and pole landmark detections with 2D LiDAR within a probabilistic localisation framework. Detected trunks are converted into semantic walls, forming structural row boundaries embedded in the measurement model to improve discrimination between adjacent rows. GNSS is incorporated as a lightweight prior that stabilises localisation when semantic observations are sparse. Field experiments in a 10-row vineyard demonstrate consistent improvements over geometry-only (AMCL), vision-based (RTAB-Map), and GNSS baselines. Compared to AMCL, SLPF reduces Absolute Pose Error by 22% and 65% across two traversal directions; relative to a NoisyGNSS baseline, APE decreases by 65% and 61%. Row correctness improves from 0.67 to 0.73, while mean cross-track error decreases from 1.40 m to 1.26 m. These results show that embedding row-level structural semantics within the measurement model enables robust localisation in highly repetitive outdoor agricultural environments.
Active Informative Planning for UAV-based Weed Mapping using Discrete Gaussian Process Representations
Jan 19, 2026Accurate agricultural weed mapping using unmanned aerial vehicles (UAVs) is crucial for precision farming. While traditional methods rely on rigid, pre-defined flight paths and intensive offline processing, informative path planning (IPP) offers a way to collect data adaptively where it is most needed. Gaussian process (GP) mapping provides a continuous model of weed distribution with built-in uncertainty. However, GPs must be discretised for practical use in autonomous planning. Many discretisation techniques exist, but the impact of discrete representation choice remains poorly understood. This paper investigates how different discrete GP representations influence both mapping quality and mission-level performance in UAV-based weed mapping. Considering a UAV equipped with a downward-facing camera, we implement a receding-horizon IPP strategy that selects sampling locations based on the map uncertainty, travel cost, and coverage penalties. We investigate multiple discretisation strategies for representing the GP posterior and use their induced map partitions to generate candidate viewpoints for planning. Experiments on real-world weed distributions show that representation choice significantly affects exploration behaviour and efficiency. Overall, our results demonstrate that discretisation is not only a representational detail but a key design choice that shapes planning dynamics, coverage efficiency, and computational load in online UAV weed mapping.
An Informative Planning Framework for Target Tracking and Active Mapping in Dynamic Environments with ASVs
Aug 21, 2025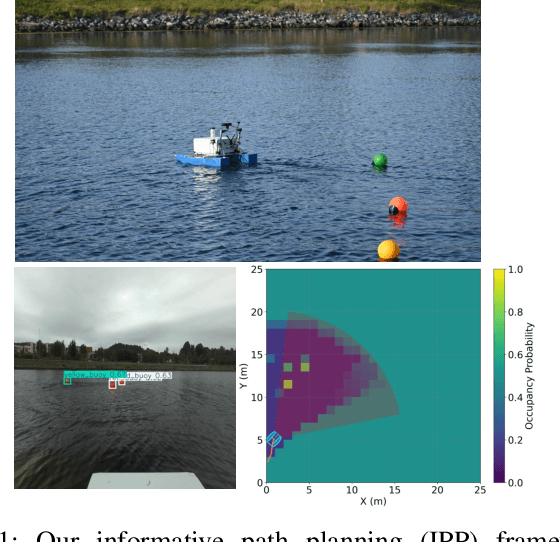
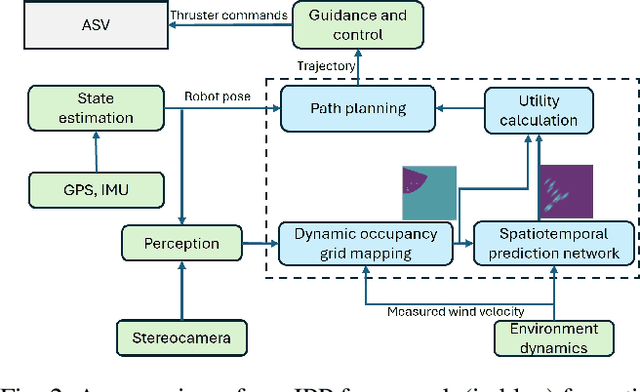
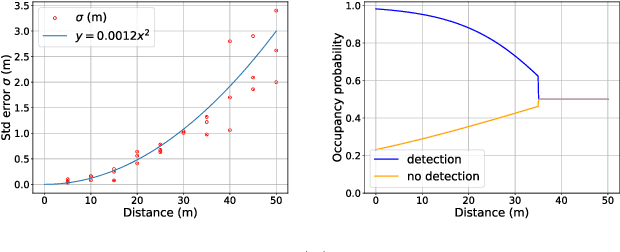
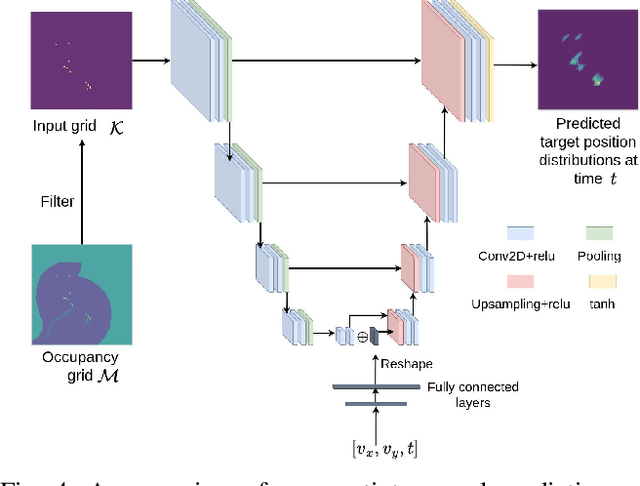
Mobile robot platforms are increasingly being used to automate information gathering tasks such as environmental monitoring. Efficient target tracking in dynamic environments is critical for applications such as search and rescue and pollutant cleanups. In this letter, we study active mapping of floating targets that drift due to environmental disturbances such as wind and currents. This is a challenging problem as it involves predicting both spatial and temporal variations in the map due to changing conditions. We propose an informative path planning framework to map an arbitrary number of moving targets with initially unknown positions in dynamic environments. A key component of our approach is a spatiotemporal prediction network that predicts target position distributions over time. We propose an adaptive planning objective for target tracking that leverages these predictions. Simulation experiments show that our proposed planning objective improves target tracking performance compared to existing methods that consider only entropy reduction as the planning objective. Finally, we validate our approach in field tests using an autonomous surface vehicle, showcasing its ability to track targets in real-world monitoring scenarios.
Uncertainty-Informed Active Perception for Open Vocabulary Object Goal Navigation
Jun 16, 2025



Mobile robots exploring indoor environments increasingly rely on vision-language models to perceive high-level semantic cues in camera images, such as object categories. Such models offer the potential to substantially advance robot behaviour for tasks such as object-goal navigation (ObjectNav), where the robot must locate objects specified in natural language by exploring the environment. Current ObjectNav methods heavily depend on prompt engineering for perception and do not address the semantic uncertainty induced by variations in prompt phrasing. Ignoring semantic uncertainty can lead to suboptimal exploration, which in turn limits performance. Hence, we propose a semantic uncertainty-informed active perception pipeline for ObjectNav in indoor environments. We introduce a novel probabilistic sensor model for quantifying semantic uncertainty in vision-language models and incorporate it into a probabilistic geometric-semantic map to enhance spatial understanding. Based on this map, we develop a frontier exploration planner with an uncertainty-informed multi-armed bandit objective to guide efficient object search. Experimental results demonstrate that our method achieves ObjectNav success rates comparable to those of state-of-the-art approaches, without requiring extensive prompt engineering.
DM-OSVP++: One-Shot View Planning Using 3D Diffusion Models for Active RGB-Based Object Reconstruction
Apr 16, 2025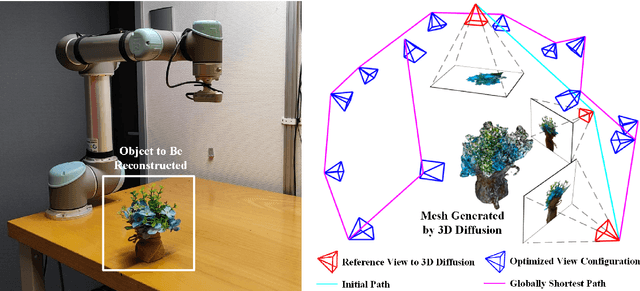


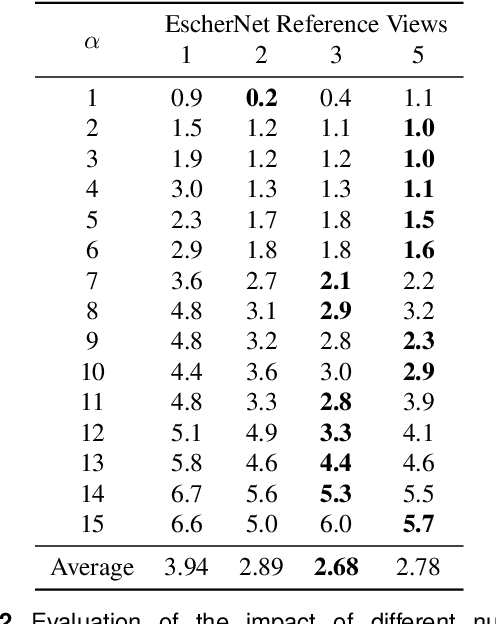
Active object reconstruction is crucial for many robotic applications. A key aspect in these scenarios is generating object-specific view configurations to obtain informative measurements for reconstruction. One-shot view planning enables efficient data collection by predicting all views at once, eliminating the need for time-consuming online replanning. Our primary insight is to leverage the generative power of 3D diffusion models as valuable prior information. By conditioning on initial multi-view images, we exploit the priors from the 3D diffusion model to generate an approximate object model, serving as the foundation for our view planning. Our novel approach integrates the geometric and textural distributions of the object model into the view planning process, generating views that focus on the complex parts of the object to be reconstructed. We validate the proposed active object reconstruction system through both simulation and real-world experiments, demonstrating the effectiveness of using 3D diffusion priors for one-shot view planning.
PINGS: Gaussian Splatting Meets Distance Fields within a Point-Based Implicit Neural Map
Feb 09, 2025Robots require high-fidelity reconstructions of their environment for effective operation. Such scene representations should be both, geometrically accurate and photorealistic to support downstream tasks. While this can be achieved by building distance fields from range sensors and radiance fields from cameras, the scalable incremental mapping of both fields consistently and at the same time with high quality remains challenging. In this paper, we propose a novel map representation that unifies a continuous signed distance field and a Gaussian splatting radiance field within an elastic and compact point-based implicit neural map. By enforcing geometric consistency between these fields, we achieve mutual improvements by exploiting both modalities. We devise a LiDAR-visual SLAM system called PINGS using the proposed map representation and evaluate it on several challenging large-scale datasets. Experimental results demonstrate that PINGS can incrementally build globally consistent distance and radiance fields encoded with a compact set of neural points. Compared to the state-of-the-art methods, PINGS achieves superior photometric and geometric rendering at novel views by leveraging the constraints from the distance field. Furthermore, by utilizing dense photometric cues and multi-view consistency from the radiance field, PINGS produces more accurate distance fields, leading to improved odometry estimation and mesh reconstruction.
ActiveGS: Active Scene Reconstruction using Gaussian Splatting
Dec 23, 2024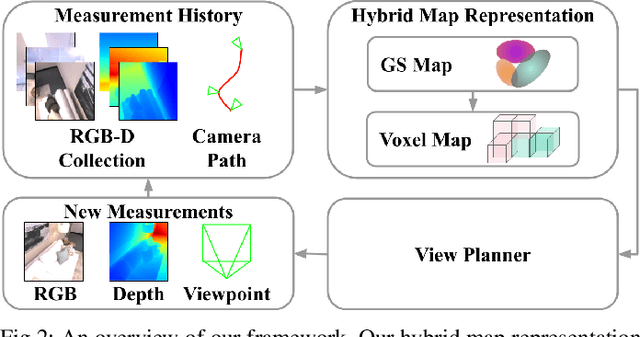
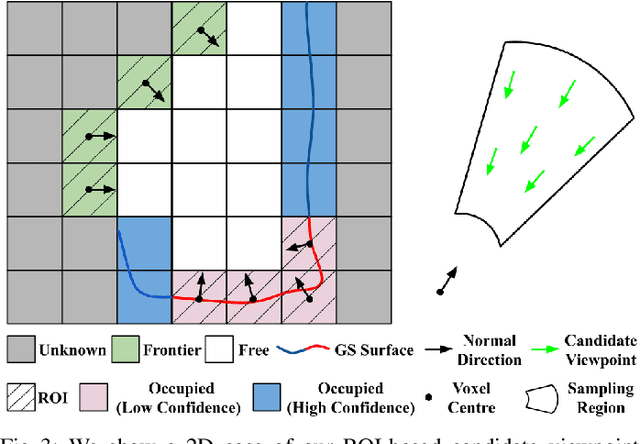
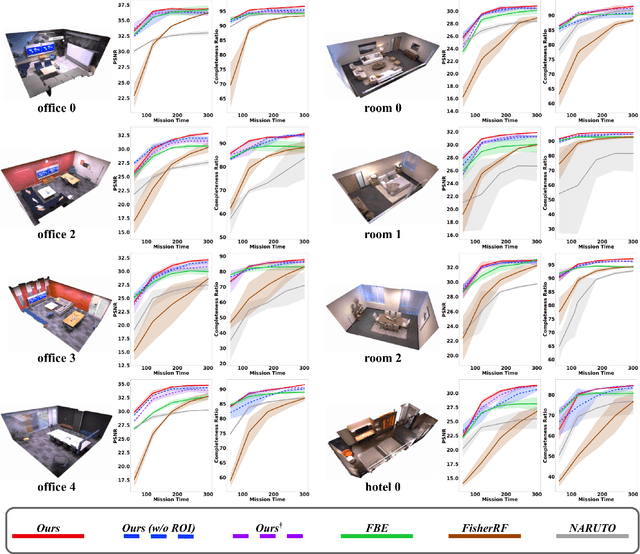

Robotics applications often rely on scene reconstructions to enable downstream tasks. In this work, we tackle the challenge of actively building an accurate map of an unknown scene using an on-board RGB-D camera. We propose a hybrid map representation that combines a Gaussian splatting map with a coarse voxel map, leveraging the strengths of both representations: the high-fidelity scene reconstruction capabilities of Gaussian splatting and the spatial modelling strengths of the voxel map. The core of our framework is an effective confidence modelling technique for the Gaussian splatting map to identify under-reconstructed areas, while utilising spatial information from the voxel map to target unexplored areas and assist in collision-free path planning. By actively collecting scene information in under-reconstructed and unexplored areas for map updates, our approach achieves superior Gaussian splatting reconstruction results compared to state-of-the-art approaches. Additionally, we demonstrate the applicability of our active scene reconstruction framework in the real world using an unmanned aerial vehicle.