 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal-Prior-Guided View Planning for Periodic 3D Plant Reconstruction
Oct 08, 2025Periodic 3D reconstruction is essential for crop monitoring, but costly when each cycle restarts from scratch, wasting resources and ignoring information from previous captures. We propose temporal-prior-guided view planning for periodic plant reconstruction, in which a previously reconstructed model of the same plant is non-rigidly aligned to a new partial observation to form an approximation of the current geometry. To accommodate plant growth, we inflate this approximation and solve a set covering optimization problem to compute a minimal set of views. We integrated this method into a complete pipeline that acquires one additional next-best view before registration for robustness and then plans a globally shortest path to connect the planned set of views and outputs the best view sequence. Experiments on maize and tomato under hemisphere and sphere view spaces show that our system maintains or improves surface coverage while requiring fewer views and comparable movement cost compared to state-of-the-art baselines.
End-to-End Multi-Task Policy Learning from NMPC for Quadruped Locomotion
May 13, 2025Quadruped robots excel in traversing complex, unstructured environments where wheeled robots often fail. However, enabling efficient and adaptable locomotion remains challenging due to the quadrupeds' nonlinear dynamics, high degrees of freedom, and the computational demands of real-time control. Optimization-based controllers, such as Nonlinear Model Predictive Control (NMPC), have shown strong performance, but their reliance on accurate state estimation and high computational overhead makes deployment in real-world settings challenging. In this work, we present a Multi-Task Learning (MTL) framework in which expert NMPC demonstrations are used to train a single neural network to predict actions for multiple locomotion behaviors directly from raw proprioceptive sensor inputs. We evaluate our approach extensively on the quadruped robot Go1, both in simulation and on real hardware, demonstrating that it accurately reproduces expert behavior, allows smooth gait switching, and simplifies the control pipeline for real-time deployment. Our MTL architecture enables learning diverse gaits within a unified policy, achieving high $R^{2}$ scores for predicted joint targets across all tasks.
Privacy Risks of Robot Vision: A User Study on Image Modalities and Resolution
May 12, 2025User privacy is a crucial concern in robotic applications, especially when mobile service robots are deployed in personal or sensitive environments. However, many robotic downstream tasks require the use of cameras, which may raise privacy risks. To better understand user perceptions of privacy in relation to visual data, we conducted a user study investigating how different image modalities and image resolutions affect users' privacy concerns. The results show that depth images are broadly viewed as privacy-safe, and a similarly high proportion of respondents feel the same about semantic segmentation images. Additionally, the majority of participants consider 32*32 resolution RGB images to be almost sufficiently privacy-preserving, while most believe that 16*16 resolution can fully guarantee privacy protection.
DM-OSVP++: One-Shot View Planning Using 3D Diffusion Models for Active RGB-Based Object Reconstruction
Apr 16, 2025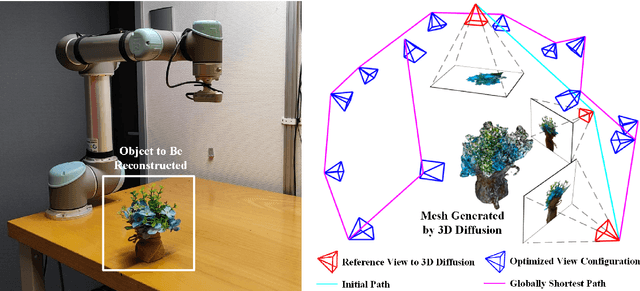


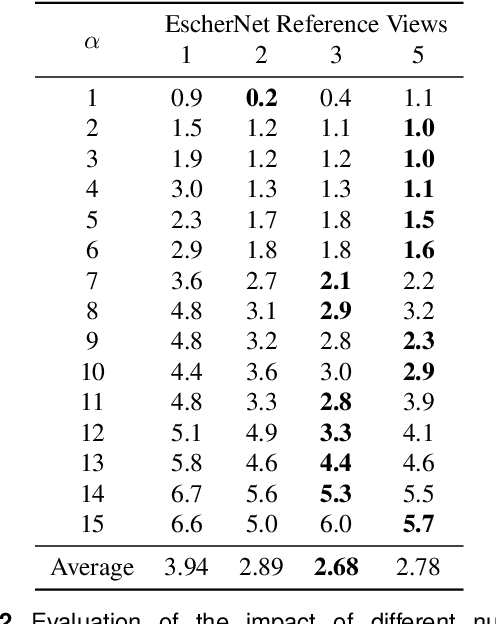
Active object reconstruction is crucial for many robotic applications. A key aspect in these scenarios is generating object-specific view configurations to obtain informative measurements for reconstruction. One-shot view planning enables efficient data collection by predicting all views at once, eliminating the need for time-consuming online replanning. Our primary insight is to leverage the generative power of 3D diffusion models as valuable prior information. By conditioning on initial multi-view images, we exploit the priors from the 3D diffusion model to generate an approximate object model, serving as the foundation for our view planning. Our novel approach integrates the geometric and textural distributions of the object model into the view planning process, generating views that focus on the complex parts of the object to be reconstructed. We validate the proposed active object reconstruction system through both simulation and real-world experiments, demonstrating the effectiveness of using 3D diffusion priors for one-shot view planning.
Auditory Localization and Assessment of Consequential Robot Sounds: A Multi-Method Study in Virtual Reality
Apr 01, 2025Mobile robots increasingly operate alongside humans but are often out of sight, so that humans need to rely on the sounds of the robots to recognize their presence. For successful human-robot interaction (HRI), it is therefore crucial to understand how humans perceive robots by their consequential sounds, i.e., operating noise. Prior research suggests that the sound of a quadruped Go1 is more detectable than that of a wheeled Turtlebot. This study builds on this and examines the human ability to localize consequential sounds of three robots (quadruped Go1, wheeled Turtlebot 2i, wheeled HSR) in Virtual Reality. In a within-subjects design, we assessed participants' localization performance for the robots with and without an acoustic vehicle alerting system (AVAS) for two velocities (0.3, 0.8 m/s) and two trajectories (head-on, radial). In each trial, participants were presented with the sound of a moving robot for 3~s and were tasked to point at its final position (localization task). Localization errors were measured as the absolute angular difference between the participants' estimated and the actual robot position. Results showed that the robot type significantly influenced the localization accuracy and precision, with the sound of the wheeled HSR (especially without AVAS) performing worst under all experimental conditions. Surprisingly, participants rated the HSR sound as more positive, less annoying, and more trustworthy than the Turtlebot and Go1 sound. This reveals a tension between subjective evaluation and objective auditory localization performance. Our findings highlight consequential robot sounds as a critical factor for designing intuitive and effective HRI, with implications for human-centered robot design and social navigation.
Immersive Explainability: Visualizing Robot Navigation Decisions through XAI Semantic Scene Projections in Virtual Reality
Apr 01, 2025End-to-end robot policies achieve high performance through neural networks trained via reinforcement learning (RL). Yet, their black box nature and abstract reasoning pose challenges for human-robot interaction (HRI), because humans may experience difficulty in understanding and predicting the robot's navigation decisions, hindering trust development. We present a virtual reality (VR) interface that visualizes explainable AI (XAI) outputs and the robot's lidar perception to support intuitive interpretation of RL-based navigation behavior. By visually highlighting objects based on their attribution scores, the interface grounds abstract policy explanations in the scene context. This XAI visualization bridges the gap between obscure numerical XAI attribution scores and a human-centric semantic level of explanation. A within-subjects study with 24 participants evaluated the effectiveness of our interface for four visualization conditions combining XAI and lidar. Participants ranked scene objects across navigation scenarios based on their importance to the robot, followed by a questionnaire assessing subjective understanding and predictability. Results show that semantic projection of attributions significantly enhances non-expert users' objective understanding and subjective awareness of robot behavior. In addition, lidar visualization further improves perceived predictability, underscoring the value of integrating XAI and sensor for transparent, trustworthy HRI.
DogLegs: Robust Proprioceptive State Estimation for Legged Robots Using Multiple Leg-Mounted IMUs
Mar 06, 2025



Robust and accurate proprioceptive state estimation of the main body is crucial for legged robots to execute tasks in extreme environments where exteroceptive sensors, such as LiDARs and cameras may become unreliable. In this paper, we propose DogLegs, a state estimation system for legged robots that fuses the measurements from a body-mounted inertial measurement unit (Body-IMU), joint encoders, and multiple leg-mounted IMUs (Leg-IMU) using an extended Kalman filter (EKF). The filter system contains the error states of all IMU frames. The Leg-IMUs are used to detect foot contact, thereby providing zero velocity measurements to update the state of the Leg-IMU frames. Additionally, we compute the relative position constraints between the Body-IMU and Leg-IMUs by the leg kinematics and use them to update the main body state and reduce the error drift of the individual IMU frames. Field experimental results have shown that our proposed system can achieve better state estimation accuracy compared to the traditional leg odometry method (using only Body-IMU and joint encoders) across different terrains. We make our datasets publicly available to benefit the research community.
EvidMTL: Evidential Multi-Task Learning for Uncertainty-Aware Semantic Surface Mapping from Monocular RGB Images
Mar 06, 2025For scene understanding in unstructured environments, an accurate and uncertainty-aware metric-semantic mapping is required to enable informed action selection by autonomous systems.Existing mapping methods often suffer from overconfident semantic predictions, and sparse and noisy depth sensing, leading to inconsistent map representations. In this paper, we therefore introduce EvidMTL, a multi-task learning framework that uses evidential heads for depth estimation and semantic segmentation, enabling uncertainty-aware inference from monocular RGB images. To enable uncertainty-calibrated evidential multi-task learning, we propose a novel evidential depth loss function that jointly optimizes the belief strength of the depth prediction in conjunction with evidential segmentation loss. Building on this, we present EvidKimera, an uncertainty-aware semantic surface mapping framework, which uses evidential depth and semantics prediction for improved 3D metric-semantic consistency. We train and evaluate EvidMTL on the NYUDepthV2 and assess its zero-shot performance on ScanNetV2, demonstrating superior uncertainty estimation compared to conventional approaches while maintaining comparable depth estimation and semantic segmentation. In zero-shot mapping tests on ScanNetV2, EvidKimera outperforms Kimera in semantic surface mapping accuracy and consistency, highlighting the benefits of uncertainty-aware mapping and underscoring its potential for real-world robotic applications.
GO-VMP: Global Optimization for View Motion Planning in Fruit Mapping
Mar 05, 2025Automating labor-intensive tasks such as crop monitoring with robots is essential for enhancing production and conserving resources. However, autonomously monitoring horticulture crops remains challenging due to their complex structures, which often result in fruit occlusions. Existing view planning methods attempt to reduce occlusions but either struggle to achieve adequate coverage or incur high robot motion costs. We introduce a global optimization approach for view motion planning that aims to minimize robot motion costs while maximizing fruit coverage. To this end, we leverage coverage constraints derived from the set covering problem (SCP) within a shortest Hamiltonian path problem (SHPP) formulation. While both SCP and SHPP are well-established, their tailored integration enables a unified framework that computes a global view path with minimized motion while ensuring full coverage of selected targets. Given the NP-hard nature of the problem, we employ a region-prior-based selection of coverage targets and a sparse graph structure to achieve effective optimization outcomes within a limited time. Experiments in simulation demonstrate that our method detects more fruits, enhances surface coverage, and achieves higher volume accuracy than the motion-efficient baseline with a moderate increase in motion cost, while significantly reducing motion costs compared to the coverage-focused baseline. Real-world experiments further confirm the practical applicability of our approach.
Map Space Belief Prediction for Manipulation-Enhanced Mapping
Feb 28, 2025
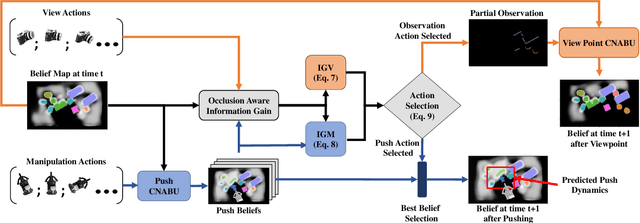
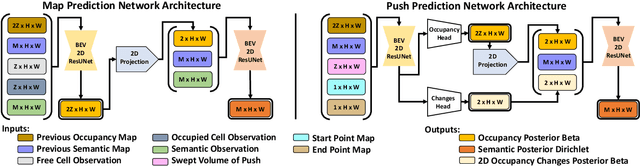

Searching for objects in cluttered environments requires selecting efficient viewpoints and manipulation actions to remove occlusions and reduce uncertainty in object locations, shapes, and categories. In this work, we address the problem of manipulation-enhanced semantic mapping, where a robot has to efficiently identify all objects in a cluttered shelf. Although Partially Observable Markov Decision Processes~(POMDPs) are standard for decision-making under uncertainty, representing unstructured interactive worlds remains challenging in this formalism. To tackle this, we define a POMDP whose belief is summarized by a metric-semantic grid map and propose a novel framework that uses neural networks to perform map-space belief updates to reason efficiently and simultaneously about object geometries, locations, categories, occlusions, and manipulation physics. Further, to enable accurate information gain analysis, the learned belief updates should maintain calibrated estimates of uncertainty. Therefore, we propose Calibrated Neural-Accelerated Belief Updates (CNABUs) to learn a belief propagation model that generalizes to novel scenarios and provides confidence-calibrated predictions for unknown areas. Our experiments show that our novel POMDP planner improves map completeness and accuracy over existing methods in challenging simulations and successfully transfers to real-world cluttered shelves in zero-shot fashion.