 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeOrbit4D: Training-Free Arbitrary Camera Redirection for Monocular Videos via Geometry-Complete 4D Reconstruction
Jan 26, 2026Camera redirection aims to replay a dynamic scene from a single monocular video under a user-specified camera trajectory. However, large-angle redirection is inherently ill-posed: a monocular video captures only a narrow spatio-temporal view of a dynamic 3D scene, providing highly partial observations of the underlying 4D world. The key challenge is therefore to recover a complete and coherent representation from this limited input, with consistent geometry and motion. While recent diffusion-based methods achieve impressive results, they often break down under large-angle viewpoint changes far from the original trajectory, where missing visual grounding leads to severe geometric ambiguity and temporal inconsistency. To address this, we present FreeOrbit4D, an effective training-free framework that tackles this geometric ambiguity by recovering a geometry-complete 4D proxy as structural grounding for video generation. We obtain this proxy by decoupling foreground and background reconstructions: we unproject the monocular video into a static background and geometry-incomplete foreground point clouds in a unified global space, then leverage an object-centric multi-view diffusion model to synthesize multi-view images and reconstruct geometry-complete foreground point clouds in canonical object space. By aligning the canonical foreground point cloud to the global scene space via dense pixel-synchronized 3D--3D correspondences and projecting the geometry-complete 4D proxy onto target camera viewpoints, we provide geometric scaffolds that guide a conditional video diffusion model. Extensive experiments show that FreeOrbit4D produces more faithful redirected videos under challenging large-angle trajectories, and our geometry-complete 4D proxy further opens a potential avenue for practical applications such as edit propagation and 4D data generation. Project page and code will be released soon.
SceneDiff: A Benchmark and Method for Multiview Object Change Detection
Dec 18, 2025We investigate the problem of identifying objects that have been added, removed, or moved between a pair of captures (images or videos) of the same scene at different times. Detecting such changes is important for many applications, such as robotic tidying or construction progress and safety monitoring. A major challenge is that varying viewpoints can cause objects to falsely appear changed. We introduce SceneDiff Benchmark, the first multiview change detection benchmark with object instance annotations, comprising 350 diverse video pairs with thousands of changed objects. We also introduce the SceneDiff method, a new training-free approach for multiview object change detection that leverages pretrained 3D, segmentation, and image encoding models to robustly predict across multiple benchmarks. Our method aligns the captures in 3D, extracts object regions, and compares spatial and semantic region features to detect changes. Experiments on multi-view and two-view benchmarks demonstrate that our method outperforms existing approaches by large margins (94% and 37.4% relative AP improvements). The benchmark and code will be publicly released.
InvRGB+L: Inverse Rendering of Complex Scenes with Unified Color and LiDAR Reflectance Modeling
Jul 23, 2025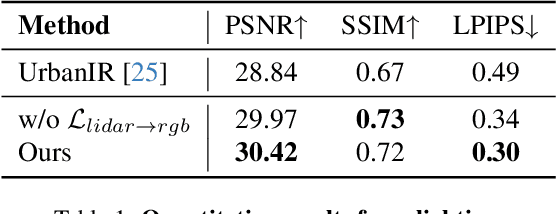

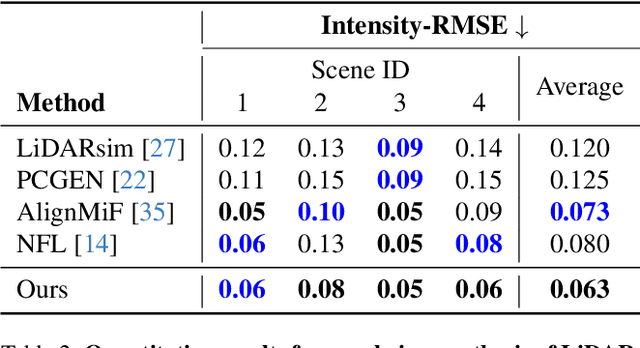
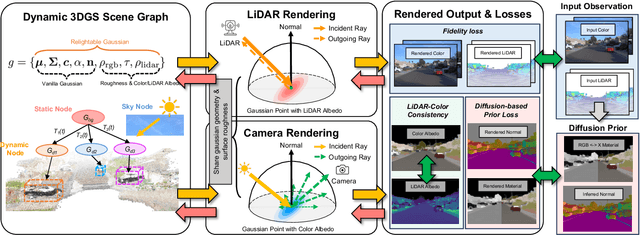
We present InvRGB+L, a novel inverse rendering model that reconstructs large, relightable, and dynamic scenes from a single RGB+LiDAR sequence. Conventional inverse graphics methods rely primarily on RGB observations and use LiDAR mainly for geometric information, often resulting in suboptimal material estimates due to visible light interference. We find that LiDAR's intensity values-captured with active illumination in a different spectral range-offer complementary cues for robust material estimation under variable lighting. Inspired by this, InvRGB+L leverages LiDAR intensity cues to overcome challenges inherent in RGB-centric inverse graphics through two key innovations: (1) a novel physics-based LiDAR shading model and (2) RGB-LiDAR material consistency losses. The model produces novel-view RGB and LiDAR renderings of urban and indoor scenes and supports relighting, night simulations, and dynamic object insertions, achieving results that surpass current state-of-the-art methods in both scene-level urban inverse rendering and LiDAR simulation.
AD-GS: Object-Aware B-Spline Gaussian Splatting for Self-Supervised Autonomous Driving
Jul 16, 2025Modeling and rendering dynamic urban driving scenes is crucial for self-driving simulation. Current high-quality methods typically rely on costly manual object tracklet annotations, while self-supervised approaches fail to capture dynamic object motions accurately and decompose scenes properly, resulting in rendering artifacts. We introduce AD-GS, a novel self-supervised framework for high-quality free-viewpoint rendering of driving scenes from a single log. At its core is a novel learnable motion model that integrates locality-aware B-spline curves with global-aware trigonometric functions, enabling flexible yet precise dynamic object modeling. Rather than requiring comprehensive semantic labeling, AD-GS automatically segments scenes into objects and background with the simplified pseudo 2D segmentation, representing objects using dynamic Gaussians and bidirectional temporal visibility masks. Further, our model incorporates visibility reasoning and physically rigid regularization to enhance robustness. Extensive evaluations demonstrate that our annotation-free model significantly outperforms current state-of-the-art annotation-free methods and is competitive with annotation-dependent approaches.
VoxelSplat: Dynamic Gaussian Splatting as an Effective Loss for Occupancy and Flow Prediction
Jun 05, 2025Recent advancements in camera-based occupancy prediction have focused on the simultaneous prediction of 3D semantics and scene flow, a task that presents significant challenges due to specific difficulties, e.g., occlusions and unbalanced dynamic environments. In this paper, we analyze these challenges and their underlying causes. To address them, we propose a novel regularization framework called VoxelSplat. This framework leverages recent developments in 3D Gaussian Splatting to enhance model performance in two key ways: (i) Enhanced Semantics Supervision through 2D Projection: During training, our method decodes sparse semantic 3D Gaussians from 3D representations and projects them onto the 2D camera view. This provides additional supervision signals in the camera-visible space, allowing 2D labels to improve the learning of 3D semantics. (ii) Scene Flow Learning: Our framework uses the predicted scene flow to model the motion of Gaussians, and is thus able to learn the scene flow of moving objects in a self-supervised manner using the labels of adjacent frames. Our method can be seamlessly integrated into various existing occupancy models, enhancing performance without increasing inference time. Extensive experiments on benchmark datasets demonstrate the effectiveness of VoxelSplat in improving the accuracy of both semantic occupancy and scene flow estimation. The project page and codes are available at https://zzy816.github.io/VoxelSplat-Demo/.
Controllable Weather Synthesis and Removal with Video Diffusion Models
May 01, 2025



Generating realistic and controllable weather effects in videos is valuable for many applications. Physics-based weather simulation requires precise reconstructions that are hard to scale to in-the-wild videos, while current video editing often lacks realism and control. In this work, we introduce WeatherWeaver, a video diffusion model that synthesizes diverse weather effects -- including rain, snow, fog, and clouds -- directly into any input video without the need for 3D modeling. Our model provides precise control over weather effect intensity and supports blending various weather types, ensuring both realism and adaptability. To overcome the scarcity of paired training data, we propose a novel data strategy combining synthetic videos, generative image editing, and auto-labeled real-world videos. Extensive evaluations show that our method outperforms state-of-the-art methods in weather simulation and removal, providing high-quality, physically plausible, and scene-identity-preserving results over various real-world videos.
DRAWER: Digital Reconstruction and Articulation With Environment Realism
Apr 22, 2025Creating virtual digital replicas from real-world data unlocks significant potential across domains like gaming and robotics. In this paper, we present DRAWER, a novel framework that converts a video of a static indoor scene into a photorealistic and interactive digital environment. Our approach centers on two main contributions: (i) a reconstruction module based on a dual scene representation that reconstructs the scene with fine-grained geometric details, and (ii) an articulation module that identifies articulation types and hinge positions, reconstructs simulatable shapes and appearances and integrates them into the scene. The resulting virtual environment is photorealistic, interactive, and runs in real time, with compatibility for game engines and robotic simulation platforms. We demonstrate the potential of DRAWER by using it to automatically create an interactive game in Unreal Engine and to enable real-to-sim-to-real transfer for robotics applications.
Uni4D: Unifying Visual Foundation Models for 4D Modeling from a Single Video
Mar 27, 2025This paper presents a unified approach to understanding dynamic scenes from casual videos. Large pretrained vision foundation models, such as vision-language, video depth prediction, motion tracking, and segmentation models, offer promising capabilities. However, training a single model for comprehensive 4D understanding remains challenging. We introduce Uni4D, a multi-stage optimization framework that harnesses multiple pretrained models to advance dynamic 3D modeling, including static/dynamic reconstruction, camera pose estimation, and dense 3D motion tracking. Our results show state-of-the-art performance in dynamic 4D modeling with superior visual quality. Notably, Uni4D requires no retraining or fine-tuning, highlighting the effectiveness of repurposing visual foundation models for 4D understanding.
PhysGen3D: Crafting a Miniature Interactive World from a Single Image
Mar 26, 2025Envisioning physically plausible outcomes from a single image requires a deep understanding of the world's dynamics. To address this, we introduce PhysGen3D, a novel framework that transforms a single image into an amodal, camera-centric, interactive 3D scene. By combining advanced image-based geometric and semantic understanding with physics-based simulation, PhysGen3D creates an interactive 3D world from a static image, enabling us to "imagine" and simulate future scenarios based on user input. At its core, PhysGen3D estimates 3D shapes, poses, physical and lighting properties of objects, thereby capturing essential physical attributes that drive realistic object interactions. This framework allows users to specify precise initial conditions, such as object speed or material properties, for enhanced control over generated video outcomes. We evaluate PhysGen3D's performance against closed-source state-of-the-art (SOTA) image-to-video models, including Pika, Kling, and Gen-3, showing PhysGen3D's capacity to generate videos with realistic physics while offering greater flexibility and fine-grained control. Our results show that PhysGen3D achieves a unique balance of photorealism, physical plausibility, and user-driven interactivity, opening new possibilities for generating dynamic, physics-grounded video from an image.
GigaSLAM: Large-Scale Monocular SLAM with Hierachical Gaussian Splats
Mar 11, 2025Tracking and mapping in large-scale, unbounded outdoor environments using only monocular RGB input presents substantial challenges for existing SLAM systems. Traditional Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) SLAM methods are typically limited to small, bounded indoor settings. To overcome these challenges, we introduce GigaSLAM, the first NeRF/3DGS-based SLAM framework for kilometer-scale outdoor environments, as demonstrated on the KITTI and KITTI 360 datasets. Our approach employs a hierarchical sparse voxel map representation, where Gaussians are decoded by neural networks at multiple levels of detail. This design enables efficient, scalable mapping and high-fidelity viewpoint rendering across expansive, unbounded scenes. For front-end tracking, GigaSLAM utilizes a metric depth model combined with epipolar geometry and PnP algorithms to accurately estimate poses, while incorporating a Bag-of-Words-based loop closure mechanism to maintain robust alignment over long trajectories. Consequently, GigaSLAM delivers high-precision tracking and visually faithful rendering on urban outdoor benchmarks, establishing a robust SLAM solution for large-scale, long-term scenarios, and significantly extending the applicability of Gaussian Splatting SLAM systems to unbounded outdoor environments.