 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni4D: Unifying Visual Foundation Models for 4D Modeling from a Single Video
Mar 27, 2025This paper presents a unified approach to understanding dynamic scenes from casual videos. Large pretrained vision foundation models, such as vision-language, video depth prediction, motion tracking, and segmentation models, offer promising capabilities. However, training a single model for comprehensive 4D understanding remains challenging. We introduce Uni4D, a multi-stage optimization framework that harnesses multiple pretrained models to advance dynamic 3D modeling, including static/dynamic reconstruction, camera pose estimation, and dense 3D motion tracking. Our results show state-of-the-art performance in dynamic 4D modeling with superior visual quality. Notably, Uni4D requires no retraining or fine-tuning, highlighting the effectiveness of repurposing visual foundation models for 4D understanding.
CropCraft: Inverse Procedural Modeling for 3D Reconstruction of Crop Plants
Nov 14, 2024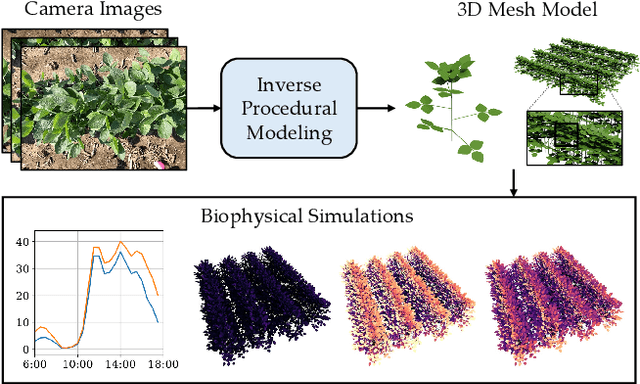
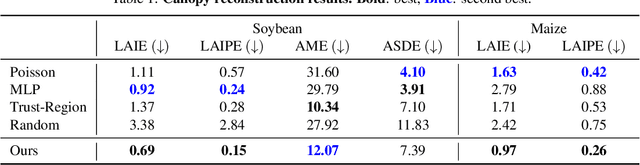
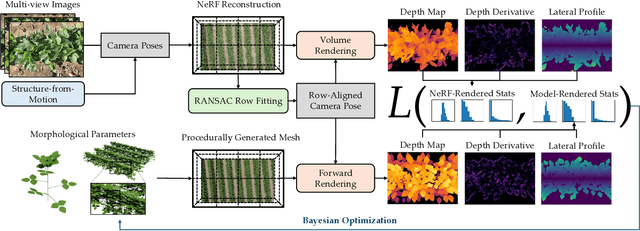
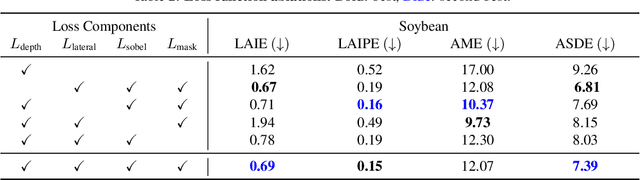
The ability to automatically build 3D digital twins of plants from images has countless applications in agriculture, environmental science, robotics, and other fields. However, current 3D reconstruction methods fail to recover complete shapes of plants due to heavy occlusion and complex geometries. In this work, we present a novel method for 3D reconstruction of agricultural crops based on optimizing a parametric model of plant morphology via inverse procedural modeling. Our method first estimates depth maps by fitting a neural radiance field and then employs Bayesian optimization to estimate plant morphological parameters that result in consistent depth renderings. The resulting 3D model is complete and biologically plausible. We validate our method on a dataset of real images of agricultural fields, and demonstrate that the reconstructions can be used for a variety of monitoring and simulation applications.
Physical Property Understanding from Language-Embedded Feature Fields
Apr 05, 2024Can computers perceive the physical properties of objects solely through vision? Research in cognitive science and vision science has shown that humans excel at identifying materials and estimating their physical properties based purely on visual appearance. In this paper, we present a novel approach for dense prediction of the physical properties of objects using a collection of images. Inspired by how humans reason about physics through vision, we leverage large language models to propose candidate materials for each object. We then construct a language-embedded point cloud and estimate the physical properties of each 3D point using a zero-shot kernel regression approach. Our method is accurate, annotation-free, and applicable to any object in the open world. Experiments demonstrate the effectiveness of the proposed approach in various physical property reasoning tasks, such as estimating the mass of common objects, as well as other properties like friction and hardness.
PEANUT: Predicting and Navigating to Unseen Targets
Dec 05, 2022



Efficient ObjectGoal navigation (ObjectNav) in novel environments requires an understanding of the spatial and semantic regularities in environment layouts. In this work, we present a straightforward method for learning these regularities by predicting the locations of unobserved objects from incomplete semantic maps. Our method differs from previous prediction-based navigation methods, such as frontier potential prediction or egocentric map completion, by directly predicting unseen targets while leveraging the global context from all previously explored areas. Our prediction model is lightweight and can be trained in a supervised manner using a relatively small amount of passively collected data. Once trained, the model can be incorporated into a modular pipeline for ObjectNav without the need for any reinforcement learning. We validate the effectiveness of our method on the HM3D and MP3D ObjectNav datasets. We find that it achieves the state-of-the-art on both datasets, despite not using any additional data for training.
Learning Visually Guided Latent Actions for Assistive Teleoperation
May 02, 2021



It is challenging for humans -- particularly those living with physical disabilities -- to control high-dimensional, dexterous robots. Prior work explores learning embedding functions that map a human's low-dimensional inputs (e.g., via a joystick) to complex, high-dimensional robot actions for assistive teleoperation; however, a central problem is that there are many more high-dimensional actions than available low-dimensional inputs. To extract the correct action and maximally assist their human controller, robots must reason over their context: for example, pressing a joystick down when interacting with a coffee cup indicates a different action than when interacting with knife. In this work, we develop assistive robots that condition their latent embeddings on visual inputs. We explore a spectrum of visual encoders and show that incorporating object detectors pretrained on small amounts of cheap, easy-to-collect structured data enables i) accurately and robustly recognizing the current context and ii) generalizing control embeddings to new objects and tasks. In user studies with a high-dimensional physical robot arm, participants leverage this approach to perform new tasks with unseen objects. Our results indicate that structured visual representations improve few-shot performance and are subjectively preferred by users.