 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEngiAgent: Fully Connected Coordination of LLM Agents for Solving Open-ended Engineering Problems with Feasible Solutions
May 04, 2026Engineering problem solving is central to real-world decision-making, requiring mathematical formulations that not only represent complex problems but also produce feasible solutions under data and physical constraints. Unlike mathematical problem solving, which operates on predefined formulations, engineering tasks demand open-ended analysis, feasibility-driven modeling, and iterative refinement. Although large language models (LLMs) have shown strong capabilities in reasoning and code generation, they often fail to ensure feasibility, which limits their applicability to engineering problem solving. To address this challenge, we propose EngiAgent, a multi-agent system with a fully connected coordinator that simulates expert workflows through specialized agents for problem analysis, modeling, verification, solving, and solution evaluation. The fully connected coordinator enables flexible feedback routing, overcoming the rigidity of prior pipeline-based reflection methods and ensuring feasibility at every stage of the process. This design not only improves robustness to diverse failure cases such as data extraction errors, constraint inconsistencies, and solver failures, but also enhances the overall quality of problem solving. Empirical results across four representative domains demonstrate that EngiAgent achieves substantial improvements in feasibility compared to prior approaches, establishing a new paradigm for feasibility-oriented engineering problem solving with LLMs. Our source code and data are available at https://github.com/AI4Engi/EngiAgent.
PhotoArtAgent: Intelligent Photo Retouching with Language Model-Based Artist Agents
May 29, 2025Photo retouching is integral to photographic art, extending far beyond simple technical fixes to heighten emotional expression and narrative depth. While artists leverage expertise to create unique visual effects through deliberate adjustments, non-professional users often rely on automated tools that produce visually pleasing results but lack interpretative depth and interactive transparency. In this paper, we introduce PhotoArtAgent, an intelligent system that combines Vision-Language Models (VLMs) with advanced natural language reasoning to emulate the creative process of a professional artist. The agent performs explicit artistic analysis, plans retouching strategies, and outputs precise parameters to Lightroom through an API. It then evaluates the resulting images and iteratively refines them until the desired artistic vision is achieved. Throughout this process, PhotoArtAgent provides transparent, text-based explanations of its creative rationale, fostering meaningful interaction and user control. Experimental results show that PhotoArtAgent not only surpasses existing automated tools in user studies but also achieves results comparable to those of professional human artists.
AI-Assisted Decision-Making for Clinical Assessment of Auto-Segmented Contour Quality
May 01, 2025Purpose: This study presents a Deep Learning (DL)-based quality assessment (QA) approach for evaluating auto-generated contours (auto-contours) in radiotherapy, with emphasis on Online Adaptive Radiotherapy (OART). Leveraging Bayesian Ordinal Classification (BOC) and calibrated uncertainty thresholds, the method enables confident QA predictions without relying on ground truth contours or extensive manual labeling. Methods: We developed a BOC model to classify auto-contour quality and quantify prediction uncertainty. A calibration step was used to optimize uncertainty thresholds that meet clinical accuracy needs. The method was validated under three data scenarios: no manual labels, limited labels, and extensive labels. For rectum contours in prostate cancer, we applied geometric surrogate labels when manual labels were absent, transfer learning when limited, and direct supervision when ample labels were available. Results: The BOC model delivered robust performance across all scenarios. Fine-tuning with just 30 manual labels and calibrating with 34 subjects yielded over 90% accuracy on test data. Using the calibrated threshold, over 93% of the auto-contours' qualities were accurately predicted in over 98% of cases, reducing unnecessary manual reviews and highlighting cases needing correction. Conclusion: The proposed QA model enhances contouring efficiency in OART by reducing manual workload and enabling fast, informed clinical decisions. Through uncertainty quantification, it ensures safer, more reliable radiotherapy workflows.
CropCraft: Inverse Procedural Modeling for 3D Reconstruction of Crop Plants
Nov 14, 2024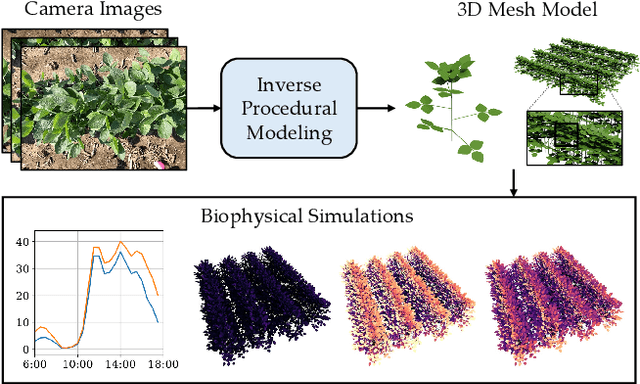
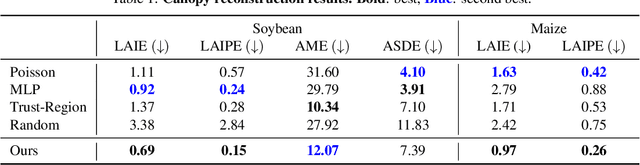
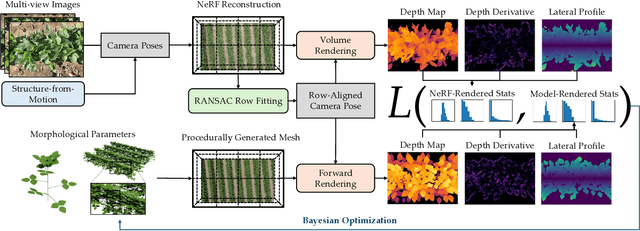
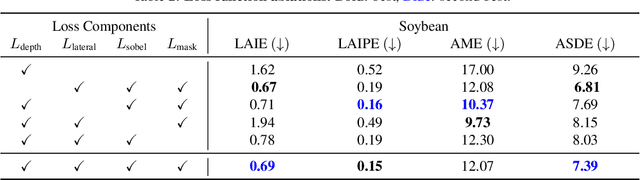
The ability to automatically build 3D digital twins of plants from images has countless applications in agriculture, environmental science, robotics, and other fields. However, current 3D reconstruction methods fail to recover complete shapes of plants due to heavy occlusion and complex geometries. In this work, we present a novel method for 3D reconstruction of agricultural crops based on optimizing a parametric model of plant morphology via inverse procedural modeling. Our method first estimates depth maps by fitting a neural radiance field and then employs Bayesian optimization to estimate plant morphological parameters that result in consistent depth renderings. The resulting 3D model is complete and biologically plausible. We validate our method on a dataset of real images of agricultural fields, and demonstrate that the reconstructions can be used for a variety of monitoring and simulation applications.
From News to Forecast: Integrating Event Analysis in LLM-Based Time Series Forecasting with Reflection
Sep 26, 2024



This paper introduces a novel approach to enhance time series forecasting using Large Language Models (LLMs) and Generative Agents. With language as a medium, our method adaptively integrates various social events into forecasting models, aligning news content with time series fluctuations for enriched insights. Specifically, we utilize LLM-based agents to iteratively filter out irrelevant news and employ human-like reasoning and reflection to evaluate predictions. This enables our model to analyze complex events, such as unexpected incidents and shifts in social behavior, and continuously refine the selection logic of news and the robustness of the agent's output. By compiling selected news with time series data, we fine-tune the LLaMa2 pre-trained model. The results demonstrate significant improvements in forecasting accuracy and suggest a potential paradigm shift in time series forecasting by effectively harnessing unstructured news data.
Physical Property Understanding from Language-Embedded Feature Fields
Apr 05, 2024Can computers perceive the physical properties of objects solely through vision? Research in cognitive science and vision science has shown that humans excel at identifying materials and estimating their physical properties based purely on visual appearance. In this paper, we present a novel approach for dense prediction of the physical properties of objects using a collection of images. Inspired by how humans reason about physics through vision, we leverage large language models to propose candidate materials for each object. We then construct a language-embedded point cloud and estimate the physical properties of each 3D point using a zero-shot kernel regression approach. Our method is accurate, annotation-free, and applicable to any object in the open world. Experiments demonstrate the effectiveness of the proposed approach in various physical property reasoning tasks, such as estimating the mass of common objects, as well as other properties like friction and hardness.
Intersection-free Robot Manipulation with Soft-Rigid Coupled Incremental Potential Contact
Nov 10, 2023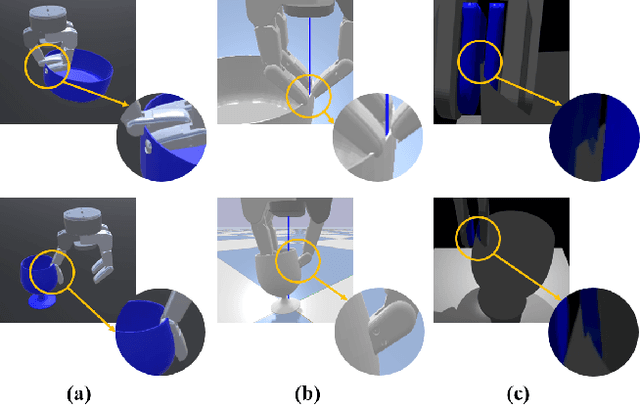

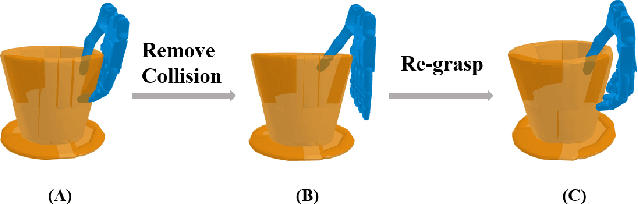
This paper presents a novel simulation platform, ZeMa, designed for robotic manipulation tasks concerning soft objects. Such simulation ideally requires three properties: two-way soft-rigid coupling, intersection-free guarantees, and frictional contact modeling, with acceptable runtime suitable for deep and reinforcement learning tasks. Current simulators often satisfy only a subset of these needs, primarily focusing on distinct rigid-rigid or soft-soft interactions. The proposed ZeMa prioritizes physical accuracy and integrates the incremental potential contact method, offering unified dynamics simulation for both soft and rigid objects. It efficiently manages soft-rigid contact, operating 75x faster than baseline tools with similar methodologies like IPC-GraspSim. To demonstrate its applicability, we employ it for parallel grasp generation, penetrated grasp repair, and reinforcement learning for grasping, successfully transferring the trained RL policy to real-world scenarios.
Performance Deterioration of Deep Learning Models after Clinical Deployment: A Case Study with Auto-segmentation for Definitive Prostate Cancer Radiotherapy
Oct 11, 2022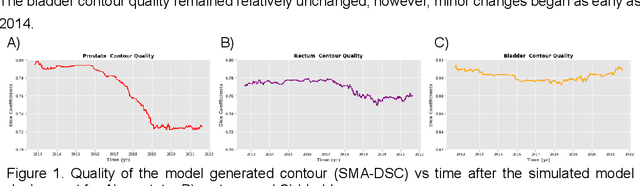
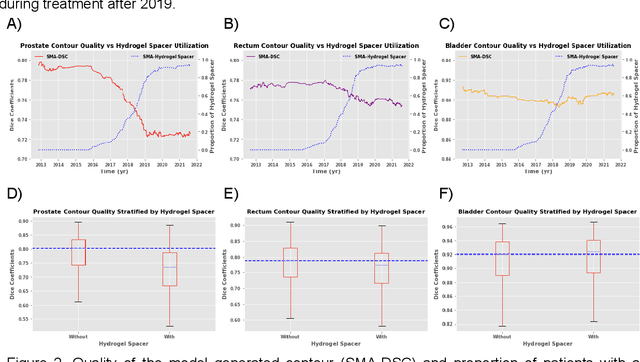
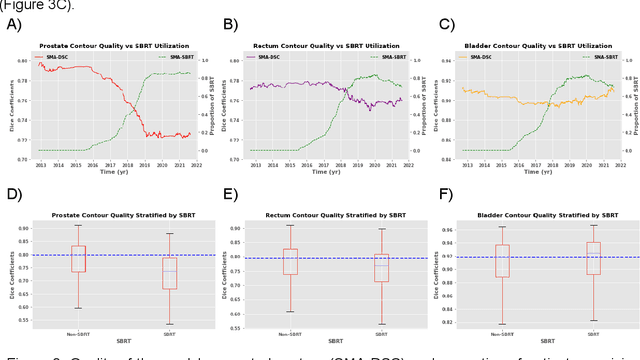
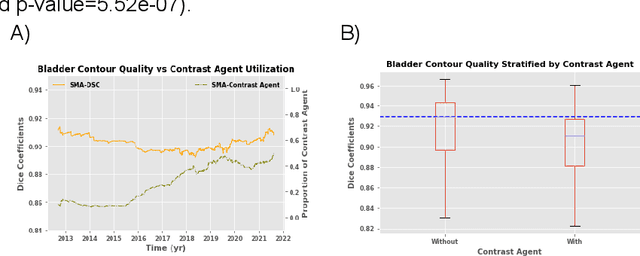
In the past decade, deep learning (DL)-based artificial intelligence (AI) has witnessed unprecedented success and has led to much excitement in medicine. However, many successful models have not been implemented in the clinic predominantly due to concerns regarding the lack of interpretability and generalizability in both spatial and temporal domains. In this work, we used a DL-based auto segmentation model for intact prostate patients to observe any temporal performance changes and then correlate them to possible explanatory variables. We retrospectively simulated the clinical implementation of our DL model to investigate temporal performance trends. Our cohort included 912 patients with prostate cancer treated with definitive radiotherapy from January 2006 to August 2021 at the University of Texas Southwestern Medical Center (UTSW). We trained a U-Net-based DL auto segmentation model on the data collected before 2012 and tested it on data collected from 2012 to 2021 to simulate the clinical deployment of the trained model starting in 2012. We visualize the trends using a simple moving average curve and used ANOVA and t-test to investigate the impact of various clinical factors. The prostate and rectum contour quality decreased rapidly after 2016-2017. Stereotactic body radiotherapy (SBRT) and hydrogel spacer use were significantly associated with prostate contour quality (p=5.6e-12 and 0.002, respectively). SBRT and physicians' styles are significantly associated with the rectum contour quality (p=0.0005 and 0.02, respectively). Only the presence of contrast within the bladder significantly affected the bladder contour quality (p=1.6e-7). We showed that DL model performance decreased over time in concordance with changes in clinical practice patterns and changes in clinical personnel.
Multiple Instance Neural Networks Based on Sparse Attention for Cancer Detection using T-cell Receptor Sequences
Aug 09, 2022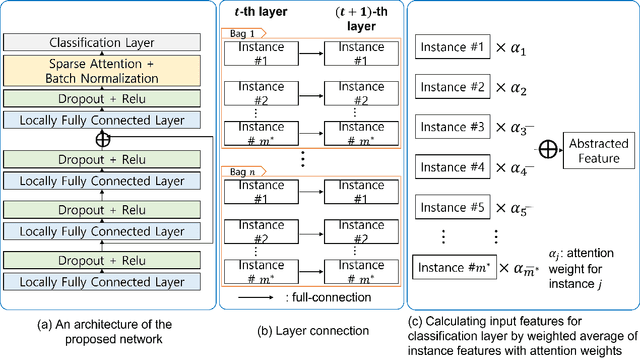
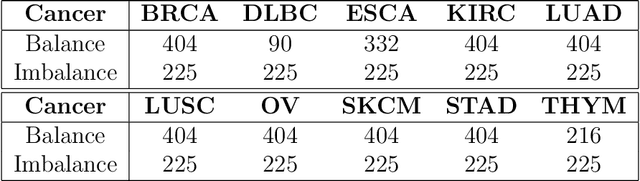

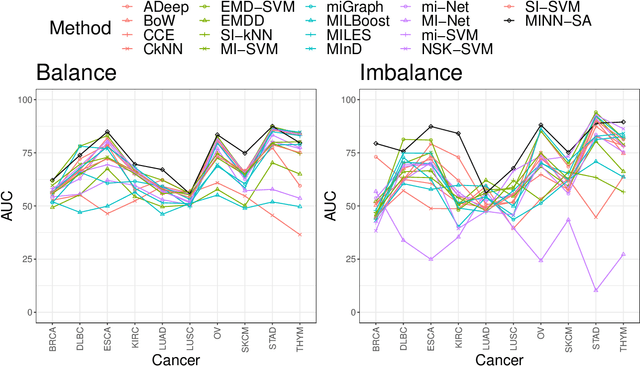
Early detection of cancers has been much explored due to its paramount importance in biomedical fields. Among different types of data used to answer this biological question, studies based on T cell receptors (TCRs) are under recent spotlight due to the growing appreciation of the roles of the host immunity system in tumor biology. However, the one-to-many correspondence between a patient and multiple TCR sequences hinders researchers from simply adopting classical statistical/machine learning methods. There were recent attempts to model this type of data in the context of multiple instance learning (MIL). Despite the novel application of MIL to cancer detection using TCR sequences and the demonstrated adequate performance in several tumor types, there is still room for improvement, especially for certain cancer types. Furthermore, explainable neural network models are not fully investigated for this application. In this article, we propose multiple instance neural networks based on sparse attention (MINN-SA) to enhance the performance in cancer detection and explainability. The sparse attention structure drops out uninformative instances in each bag, achieving both interpretability and better predictive performance in combination with the skip connection. Our experiments show that MINN-SA yields the highest area under the ROC curve (AUC) scores on average measured across 10 different types of cancers, compared to existing MIL approaches. Moreover, we observe from the estimated attentions that MINN-SA can identify the TCRs that are specific for tumor antigens in the same T cell repertoire.
Unsupervised Learning of Depth, Optical Flow and Pose with Occlusion from 3D Geometry
Mar 02, 2020

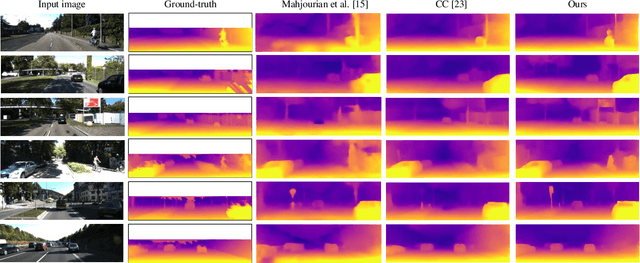

In autonomous driving, monocular sequences contain lots of information. Monocular depth estimation, camera ego-motion estimation and optical flow estimation in consecutive frames are high-profile concerns recently. By analyzing tasks above, pixels in the first frame are modeled into three parts: the rigid region, the non-rigid region, and the occluded region. In joint unsupervised training of depth and pose, we can segment the occluded region explicitly. The occlusion information is used in unsupervised learning of depth, pose and optical flow, as the image reconstructed by depth, pose and flow will be invalid in occluded regions. A less-than-mean mask is designed to further exclude the mismatched pixels which are interfered with motion or illumination change in the training of depth and pose networks. This method is also used to exclude some trivial mismatched pixels in the training of the flow net. Maximum normalization is proposed for smoothness term of depth-pose networks to restrain degradation in textureless regions. In the occluded region, as depth and camera motion can provide more reliable motion estimation, they can be used to instruct unsupervised learning of flow. Our experiments in KITTI dataset demonstrate that the model based on three regions, full and explicit segmentation of occlusion, rigid region and non-rigid region with corresponding unsupervised losses can improve performance on three tasks significantly.