 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Quantization Errors Due to Activation Spikes in GLU-Based LLMs
May 23, 2024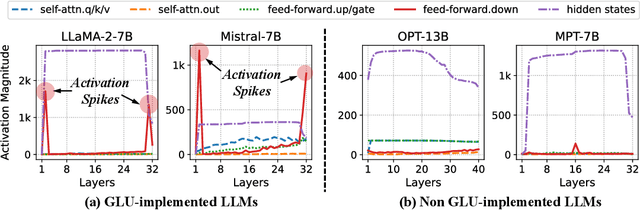
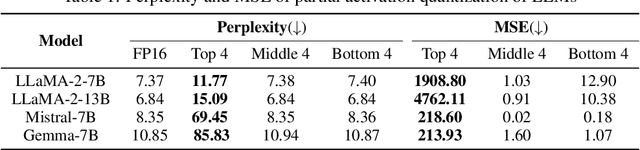
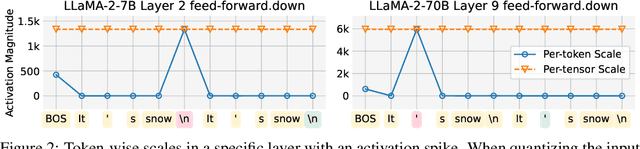
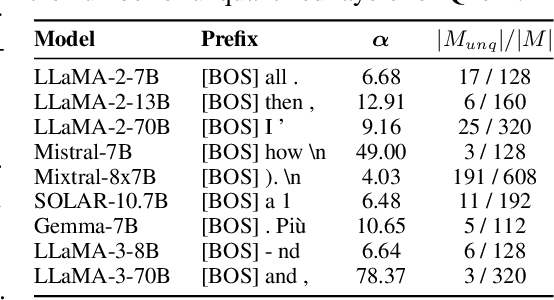
Modern large language models (LLMs) have established state-of-the-art performance through architectural improvements, but still require significant computational cost for inference. In an effort to reduce the inference cost, post-training quantization (PTQ) has become a popular approach, quantizing weights and activations to lower precision, such as INT8. In this paper, we reveal the challenges of activation quantization in GLU variants, which are widely used in feed-forward network (FFN) of modern LLMs, such as LLaMA family. The problem is that severe local quantization errors, caused by excessive magnitudes of activation in GLU variants, significantly degrade the performance of the quantized LLM. We denote these activations as activation spikes. Our further observations provide a systematic pattern of activation spikes: 1) The activation spikes occur in the FFN of specific layers, particularly in the early and late layers, 2) The activation spikes are dedicated to a couple of tokens, rather than being shared across a sequence. Based on our observations, we propose two empirical methods, Quantization-free Module (QFeM) and Quantization-free Prefix (QFeP), to isolate the activation spikes during quantization. Our extensive experiments validate the effectiveness of the proposed methods for the activation quantization, especially with coarse-grained scheme, of latest LLMs with GLU variants, including LLaMA-2/3, Mistral, Mixtral, SOLAR, and Gemma. In particular, our methods enhance the current alleviation techniques (e.g., SmoothQuant) that fail to control the activation spikes. Code is available at https://github.com/onnoo/activation-spikes.
Structured Estimation of Heterogeneous Time Series
Nov 15, 2023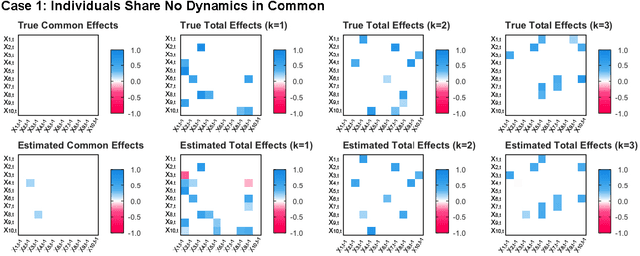
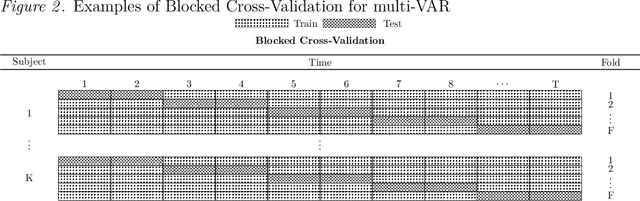
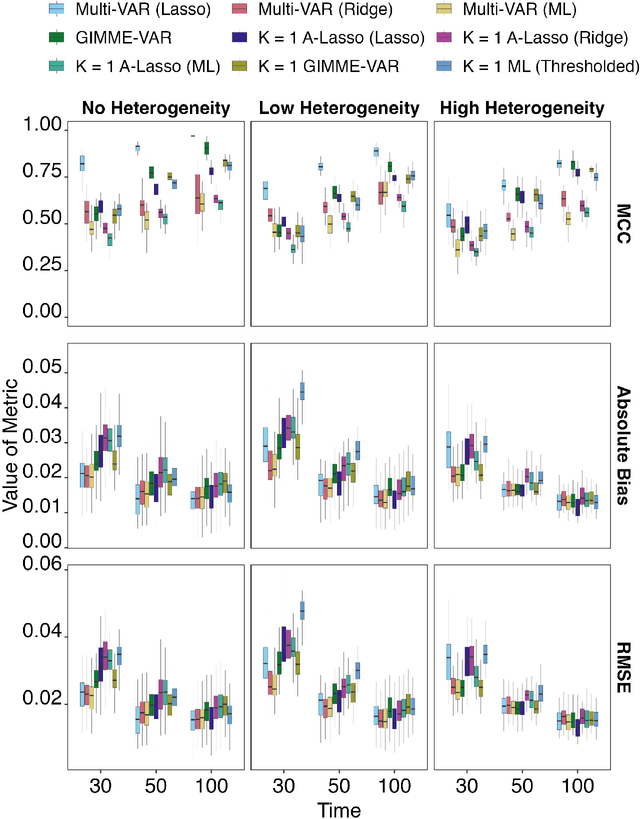
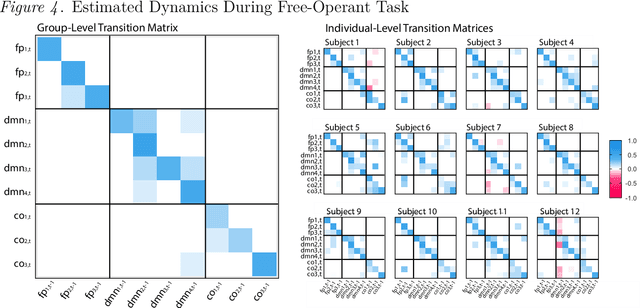
How best to model structurally heterogeneous processes is a foundational question in the social, health and behavioral sciences. Recently, Fisher et al., (2022) introduced the multi-VAR approach for simultaneously estimating multiple-subject multivariate time series characterized by common and individualizing features using penalized estimation. This approach differs from many popular modeling approaches for multiple-subject time series in that qualitative and quantitative differences in a large number of individual dynamics are well-accommodated. The current work extends the multi-VAR framework to include new adaptive weighting schemes that greatly improve estimation performance. In a small set of simulation studies we compare adaptive multi-VAR with these new penalty weights to common alternative estimators in terms of path recovery and bias. Furthermore, we provide toy examples and code demonstrating the utility of multi-VAR under different heterogeneity regimes using the multivar package for R (Fisher, 2022).
Testing the Channels of Convolutional Neural Networks
Mar 06, 2023


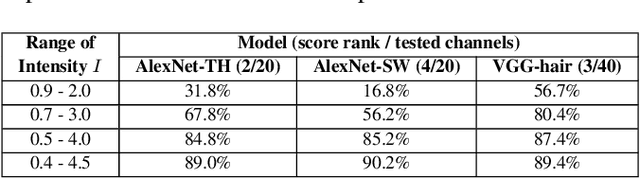
Neural networks have complex structures, and thus it is hard to understand their inner workings and ensure correctness. To understand and debug convolutional neural networks (CNNs) we propose techniques for testing the channels of CNNs. We design FtGAN, an extension to GAN, that can generate test data with varying the intensity (i.e., sum of the neurons) of a channel of a target CNN. We also proposed a channel selection algorithm to find representative channels for testing. To efficiently inspect the target CNN's inference computations, we define unexpectedness score, which estimates how similar the inference computation of the test data is to that of the training data. We evaluated FtGAN with five public datasets and showed that our techniques successfully identify defective channels in five different CNN models.
Multiple Instance Neural Networks Based on Sparse Attention for Cancer Detection using T-cell Receptor Sequences
Aug 09, 2022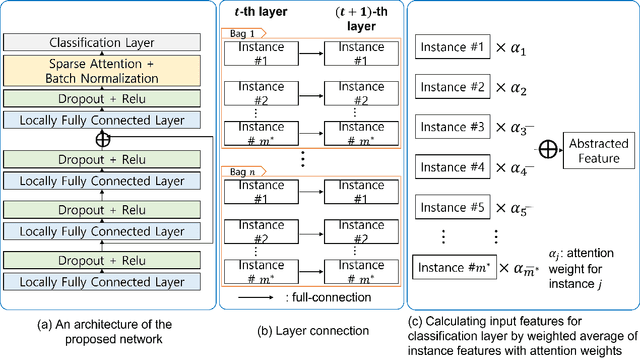
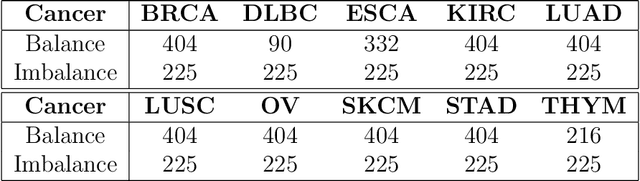

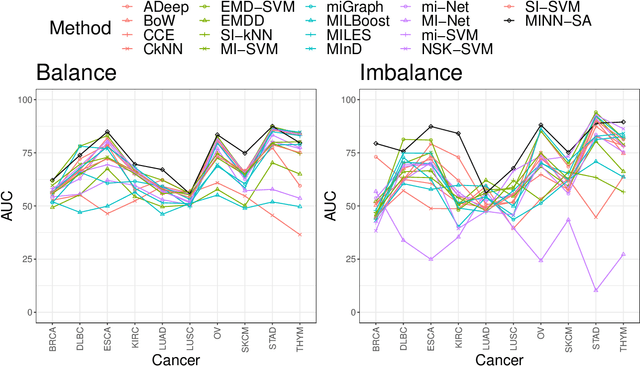
Early detection of cancers has been much explored due to its paramount importance in biomedical fields. Among different types of data used to answer this biological question, studies based on T cell receptors (TCRs) are under recent spotlight due to the growing appreciation of the roles of the host immunity system in tumor biology. However, the one-to-many correspondence between a patient and multiple TCR sequences hinders researchers from simply adopting classical statistical/machine learning methods. There were recent attempts to model this type of data in the context of multiple instance learning (MIL). Despite the novel application of MIL to cancer detection using TCR sequences and the demonstrated adequate performance in several tumor types, there is still room for improvement, especially for certain cancer types. Furthermore, explainable neural network models are not fully investigated for this application. In this article, we propose multiple instance neural networks based on sparse attention (MINN-SA) to enhance the performance in cancer detection and explainability. The sparse attention structure drops out uninformative instances in each bag, achieving both interpretability and better predictive performance in combination with the skip connection. Our experiments show that MINN-SA yields the highest area under the ROC curve (AUC) scores on average measured across 10 different types of cancers, compared to existing MIL approaches. Moreover, we observe from the estimated attentions that MINN-SA can identify the TCRs that are specific for tumor antigens in the same T cell repertoire.
GMAC: A Distributional Perspective on Actor-Critic Framework
May 24, 2021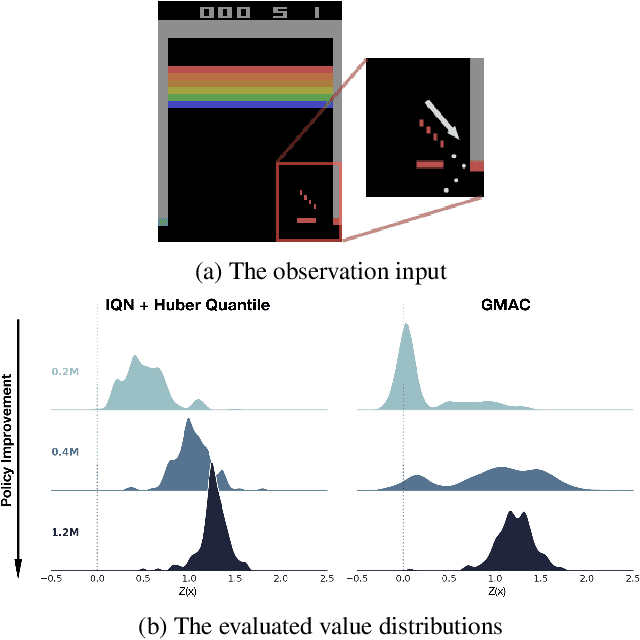
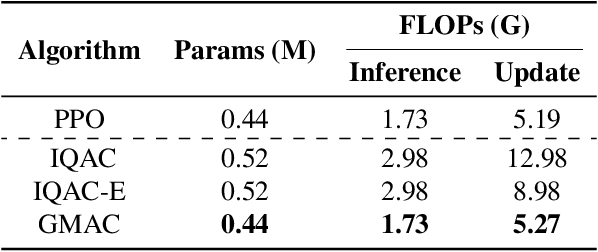
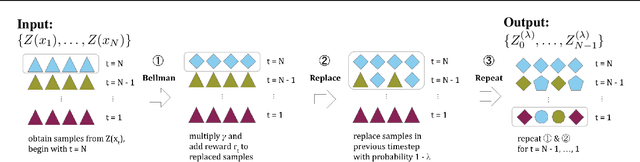
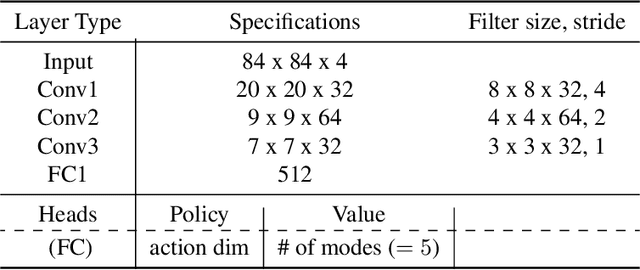
In this paper, we devise a distributional framework on actor-critic as a solution to distributional instability, action type restriction, and conflation between samples and statistics. We propose a new method that minimizes the Cram\'er distance with the multi-step Bellman target distribution generated from a novel Sample-Replacement algorithm denoted SR($\lambda$), which learns the correct value distribution under multiple Bellman operations. Parameterizing a value distribution with Gaussian Mixture Model further improves the efficiency and the performance of the method, which we name GMAC. We empirically show that GMAC captures the correct representation of value distributions and improves the performance of a conventional actor-critic method with low computational cost, in both discrete and continuous action spaces using Arcade Learning Environment (ALE) and PyBullet environment.
DeepRF: Deep Reinforcement Learning Designed RadioFrequency Waveform in MRI
May 07, 2021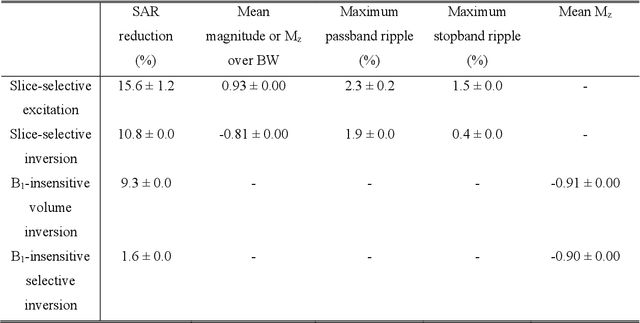
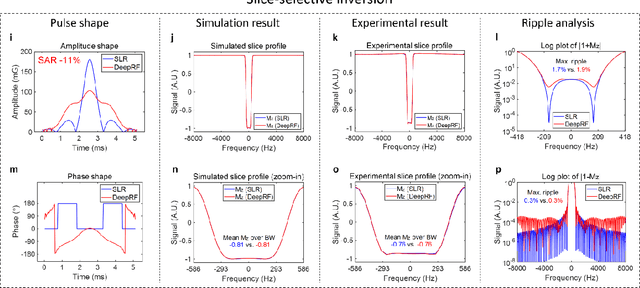
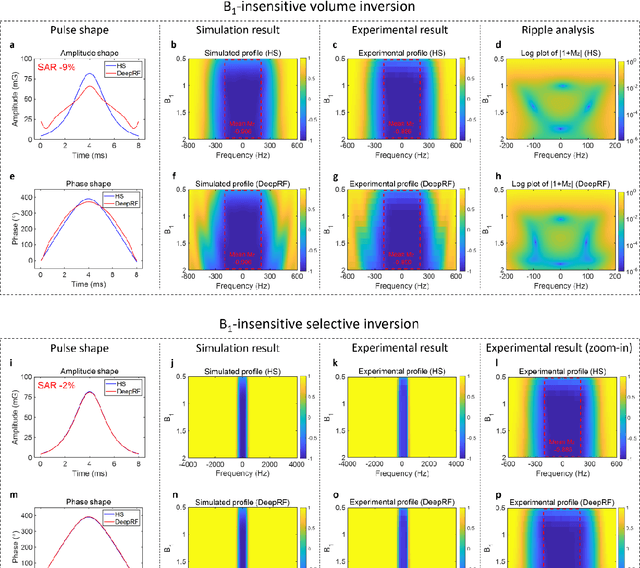
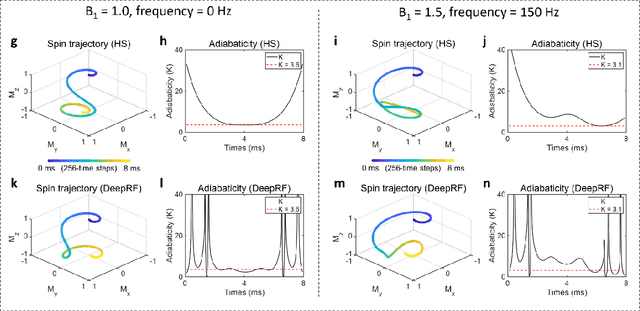
A carefully engineered radiofrequency (RF) pulse plays a key role in a number of systems such as mobile phone, radar, and magnetic resonance imaging (MRI). The design of an RF waveform, however, is often posed as an inverse problem that has no general solution. As a result, various design methods each with a specific purpose have been developed based on the intuition of human experts. In this work, we propose an artificial intelligence-powered RF pulse design framework, DeepRF, which utilizes the self-learning characteristics of deep reinforcement learning (DRL) to generate a novel RF beyond human intuition. Additionally, the method can design various types of RF pulses via customized reward functions. The algorithm of DeepRF consists of two modules: the RF generation module, which utilizes DRL to explore new RF pulses, and the RF refinement module, which optimizes the seed RF pulses from the generation module via gradient ascent. The effectiveness of DeepRF is demonstrated using four exemplary RF pulses, slice-selective excitation pulse, slice-selective inversion pulse, B1-insensitive volume inversion pulse, and B1-insensitive selective inversion pulse, that are commonly used in MRI. The results show that the DeepRF-designed pulses successfully satisfy the design criteria while improving specific absorption rates when compared to those of the conventional RF pulses. Further analyses suggest that the DeepRF-designed pulses utilize new mechanisms of magnetization manipulation that are difficult to be explained by conventional theory, suggesting the potentials of DeepRF in discovering unseen design dimensions beyond human intuition. This work may lay the foundation for an emerging field of AI-driven RF waveform design.
Learning Loss for Test-Time Augmentation
Oct 22, 2020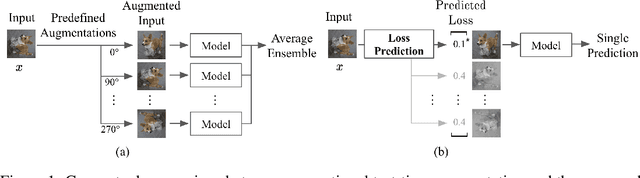
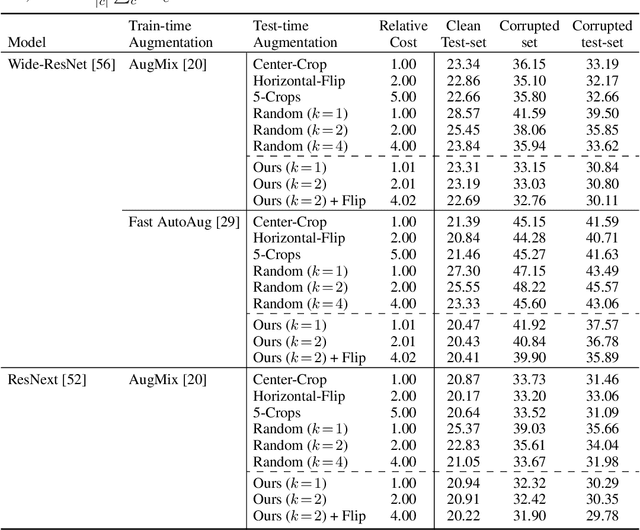
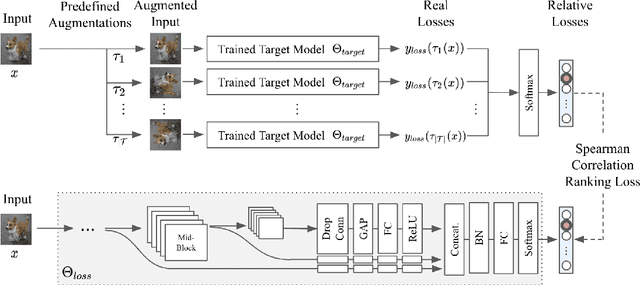

Data augmentation has been actively studied for robust neural networks. Most of the recent data augmentation methods focus on augmenting datasets during the training phase. At the testing phase, simple transformations are still widely used for test-time augmentation. This paper proposes a novel instance-level test-time augmentation that efficiently selects suitable transformations for a test input. Our proposed method involves an auxiliary module to predict the loss of each possible transformation given the input. Then, the transformations having lower predicted losses are applied to the input. The network obtains the results by averaging the prediction results of augmented inputs. Experimental results on several image classification benchmarks show that the proposed instance-aware test-time augmentation improves the model's robustness against various corruptions.
Penalized Estimation and Forecasting of Multiple Subject Intensive Longitudinal Data
Jul 09, 2020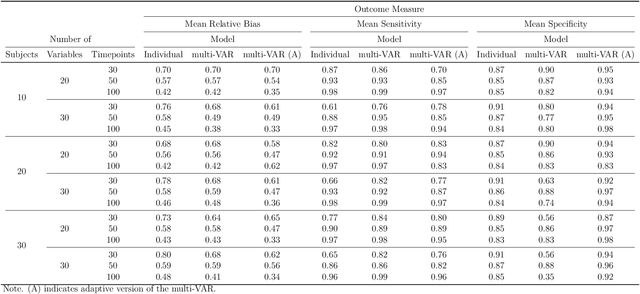

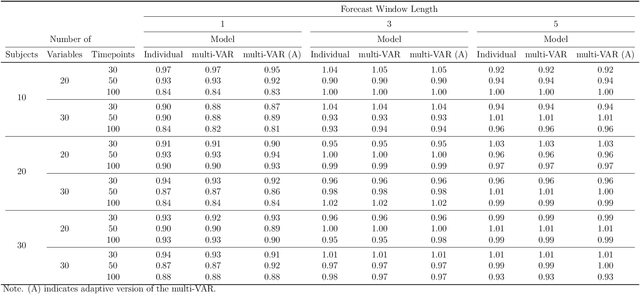
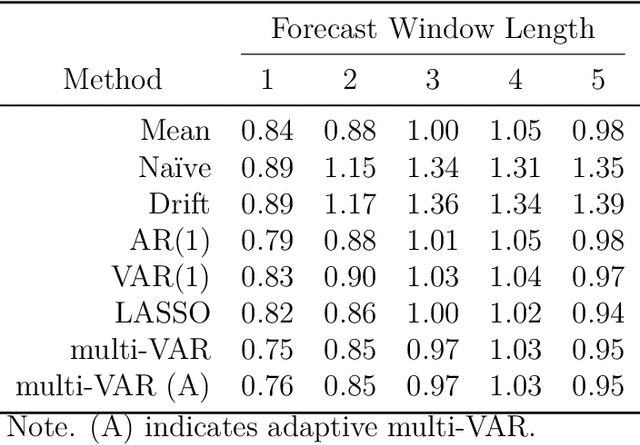
Intensive Longitudinal Data (ILD) is an increasingly common data type in the social and behavioral sciences. Despite the many benefits these data provide, little work has been dedicated to realizing the potential such data hold for forecasting dynamic processes at the individual level. To address this gap in the literature we present the multi-VAR framework, a novel methodological approach for penalized estimation and forecasting of ILD collected from multiple individuals. Importantly, our approach estimates models for all individuals simultaneously and is capable of adaptively adjusting to the amount of heterogeneity exhibited across individual dynamic processes. To accomplish this we propose proximal gradient descent algorithm for solving the multi-VAR problem and prove the consistency of the recovered transition matrices. We evaluate the forecasting performance of our method in comparison with a number of benchmark forecasting methods and provide an illustrative example involving the day-to-day emotional experiences of 16 individuals over an 11-week period.