 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Regularization for Semi-Supervised Learning
Jan 17, 2022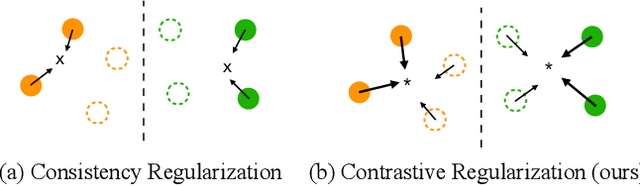
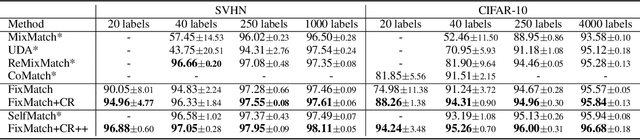
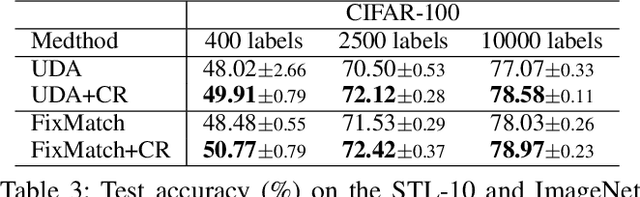

Consistency regularization on label predictions becomes a fundamental technique in semi-supervised learning, but it still requires a large number of training iterations for high performance. In this study, we analyze that the consistency regularization restricts the propagation of labeling information due to the exclusion of samples with unconfident pseudo-labels in the model updates. Then, we propose contrastive regularization to improve both efficiency and accuracy of the consistency regularization by well-clustered features of unlabeled data. In specific, after strongly augmented samples are assigned to clusters by their pseudo-labels, our contrastive regularization updates the model so that the features with confident pseudo-labels aggregate the features in the same cluster, while pushing away features in different clusters. As a result, the information of confident pseudo-labels can be effectively propagated into more unlabeled samples during training by the well-clustered features. On benchmarks of semi-supervised learning tasks, our contrastive regularization improves the previous consistency-based methods and achieves state-of-the-art results, especially with fewer training iterations. Our method also shows robust performance on open-set semi-supervised learning where unlabeled data includes out-of-distribution samples.
The Medical Segmentation Decathlon
Jun 10, 2021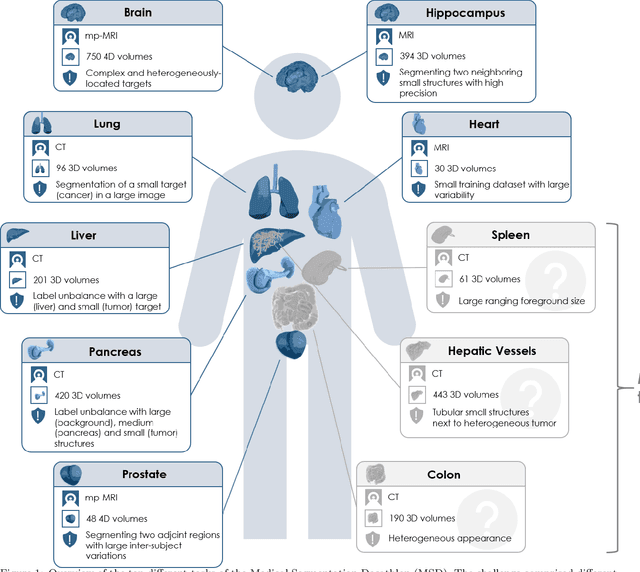
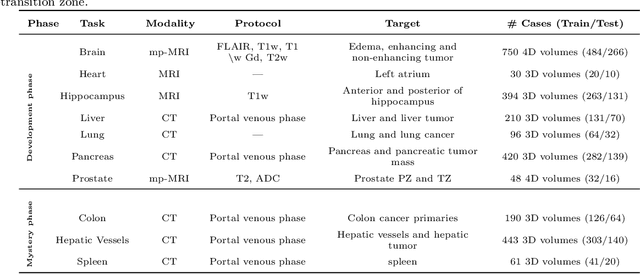
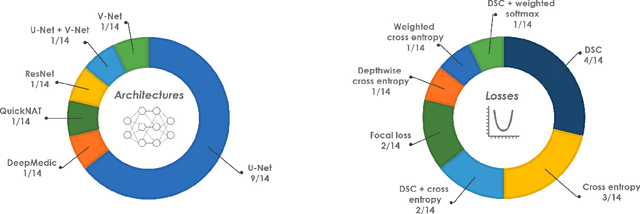
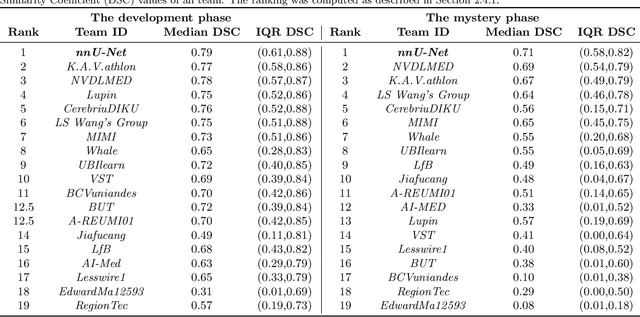
International challenges have become the de facto standard for comparative assessment of image analysis algorithms given a specific task. Segmentation is so far the most widely investigated medical image processing task, but the various segmentation challenges have typically been organized in isolation, such that algorithm development was driven by the need to tackle a single specific clinical problem. We hypothesized that a method capable of performing well on multiple tasks will generalize well to a previously unseen task and potentially outperform a custom-designed solution. To investigate the hypothesis, we organized the Medical Segmentation Decathlon (MSD) - a biomedical image analysis challenge, in which algorithms compete in a multitude of both tasks and modalities. The underlying data set was designed to explore the axis of difficulties typically encountered when dealing with medical images, such as small data sets, unbalanced labels, multi-site data and small objects. The MSD challenge confirmed that algorithms with a consistent good performance on a set of tasks preserved their good average performance on a different set of previously unseen tasks. Moreover, by monitoring the MSD winner for two years, we found that this algorithm continued generalizing well to a wide range of other clinical problems, further confirming our hypothesis. Three main conclusions can be drawn from this study: (1) state-of-the-art image segmentation algorithms are mature, accurate, and generalize well when retrained on unseen tasks; (2) consistent algorithmic performance across multiple tasks is a strong surrogate of algorithmic generalizability; (3) the training of accurate AI segmentation models is now commoditized to non AI experts.
Spatially Consistent Representation Learning
Mar 10, 2021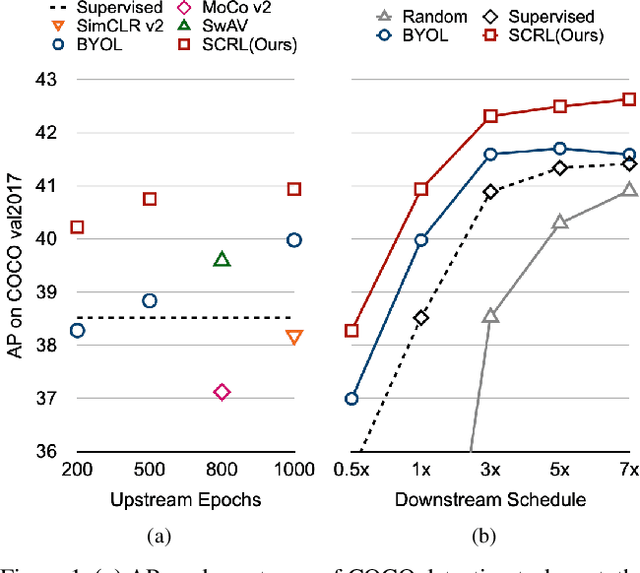
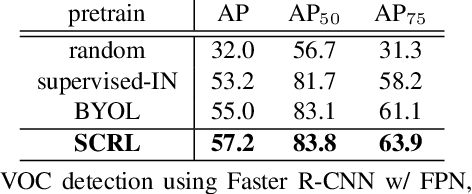

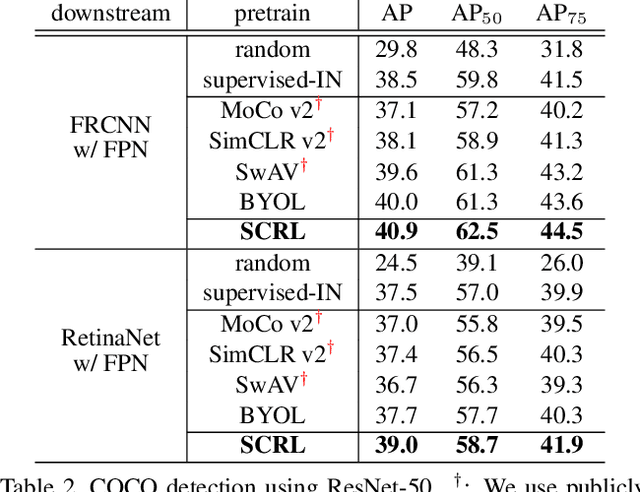
Self-supervised learning has been widely used to obtain transferrable representations from unlabeled images. Especially, recent contrastive learning methods have shown impressive performances on downstream image classification tasks. While these contrastive methods mainly focus on generating invariant global representations at the image-level under semantic-preserving transformations, they are prone to overlook spatial consistency of local representations and therefore have a limitation in pretraining for localization tasks such as object detection and instance segmentation. Moreover, aggressively cropped views used in existing contrastive methods can minimize representation distances between the semantically different regions of a single image. In this paper, we propose a spatially consistent representation learning algorithm (SCRL) for multi-object and location-specific tasks. In particular, we devise a novel self-supervised objective that tries to produce coherent spatial representations of a randomly cropped local region according to geometric translations and zooming operations. On various downstream localization tasks with benchmark datasets, the proposed SCRL shows significant performance improvements over the image-level supervised pretraining as well as the state-of-the-art self-supervised learning methods.
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
Feb 05, 2021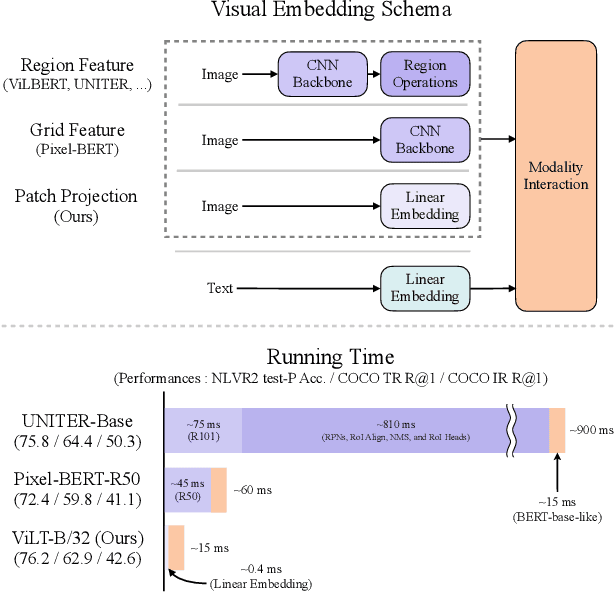
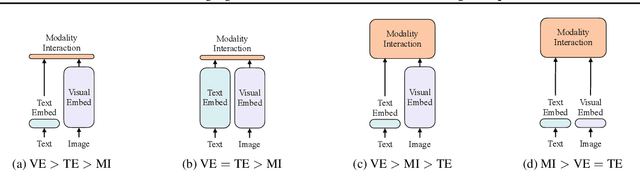
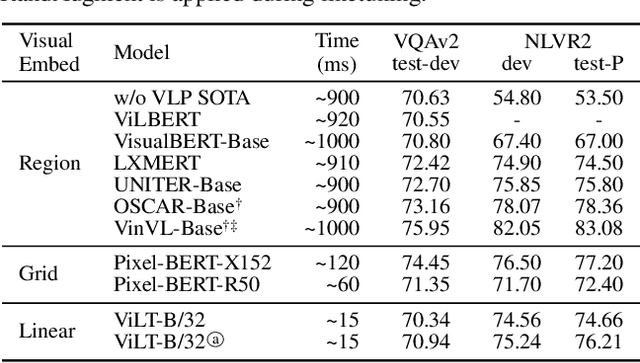
Vision-and-Language Pretraining (VLP) has improved performance on various joint vision-and-language downstream tasks. Current approaches for VLP heavily rely on image feature extraction processes, most of which involve region supervisions (e.g., object detection) and the convolutional architecture (e.g., ResNet). Although disregarded in the literature, we find it problematic in terms of both (1) efficiency/speed, that simply extracting input features requires much more computation than the actual multimodal interaction steps; and (2) expressive power, as it is upper bounded to the expressive power of the visual encoder and its predefined visual vocabulary. In this paper, we present a minimal VLP model, Vision-and-Language Transformer (ViLT), monolithic in the sense that processing of visual inputs is drastically simplified to just the same convolution-free manner that we process textual inputs. We show that ViLT is up to 60 times faster than previous VLP models, yet with competitive or better downstream task performance.
Learning Loss for Test-Time Augmentation
Oct 22, 2020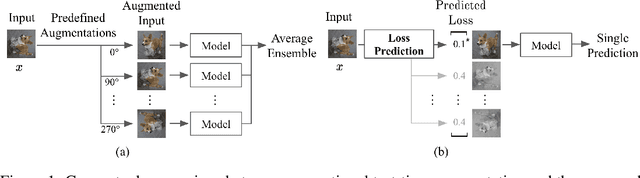
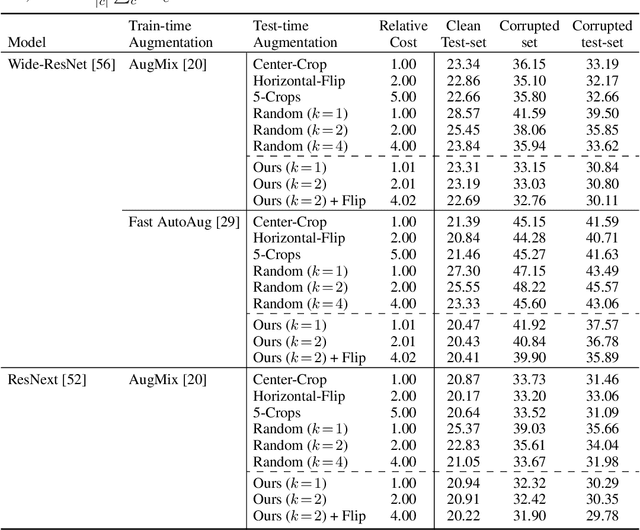
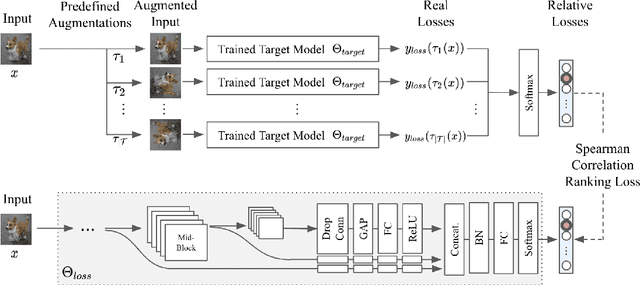

Data augmentation has been actively studied for robust neural networks. Most of the recent data augmentation methods focus on augmenting datasets during the training phase. At the testing phase, simple transformations are still widely used for test-time augmentation. This paper proposes a novel instance-level test-time augmentation that efficiently selects suitable transformations for a test input. Our proposed method involves an auxiliary module to predict the loss of each possible transformation given the input. Then, the transformations having lower predicted losses are applied to the input. The network obtains the results by averaging the prediction results of augmented inputs. Experimental results on several image classification benchmarks show that the proposed instance-aware test-time augmentation improves the model's robustness against various corruptions.
AutoCLINT: The Winning Method in AutoCV Challenge 2019
May 09, 2020
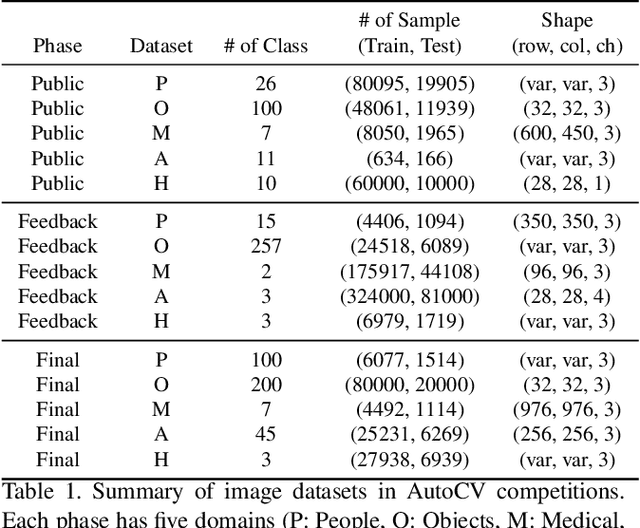
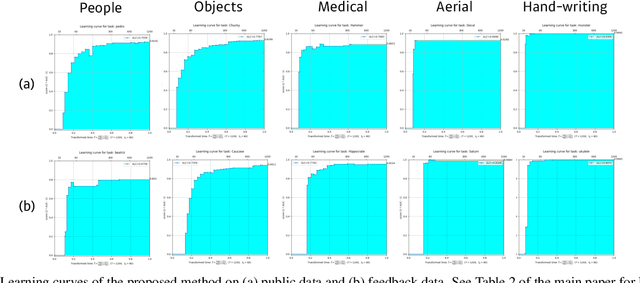

NeurIPS 2019 AutoDL challenge is a series of six automated machine learning competitions. Particularly, AutoCV challenges mainly focused on classification tasks on visual domain. In this paper, we introduce the winning method in the competition, AutoCLINT. The proposed method implements an autonomous training strategy, including efficient code optimization, and applies an automated data augmentation to achieve the fast adaptation of pretrained networks. We implement a light version of Fast AutoAugment to search for data augmentation policies efficiently for the arbitrarily given image domains. We also empirically analyze the components of the proposed method and provide ablation studies focusing on AutoCV datasets.
torchgpipe: On-the-fly Pipeline Parallelism for Training Giant Models
Apr 21, 2020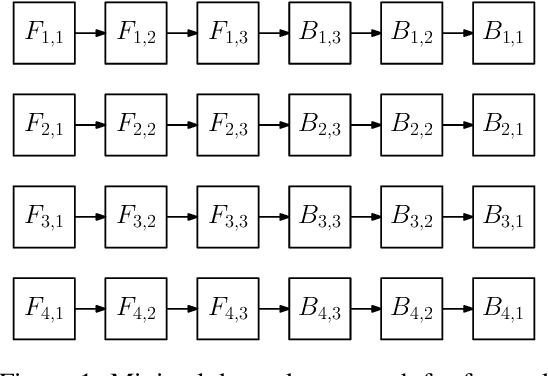

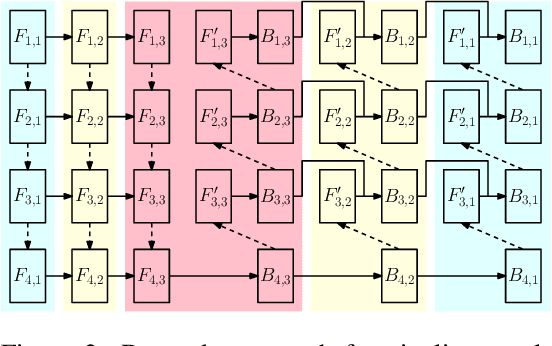
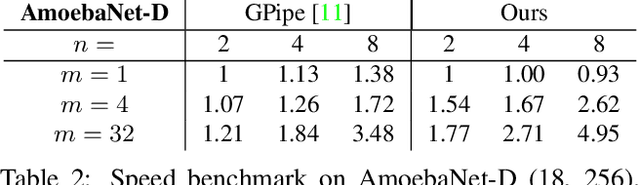
We design and implement a ready-to-use library in PyTorch for performing micro-batch pipeline parallelism with checkpointing proposed by GPipe (Huang et al., 2019). In particular, we develop a set of design components to enable pipeline-parallel gradient computation in PyTorch's define-by-run and eager execution environment. We show that each component is necessary to fully benefit from pipeline parallelism in such environment, and demonstrate the efficiency of the library by applying it to various network architectures including AmoebaNet-D and U-Net. Our library is available at https://github.com/kakaobrain/torchgpipe .
Spatially Attentive Output Layer for Image Classification
Apr 16, 2020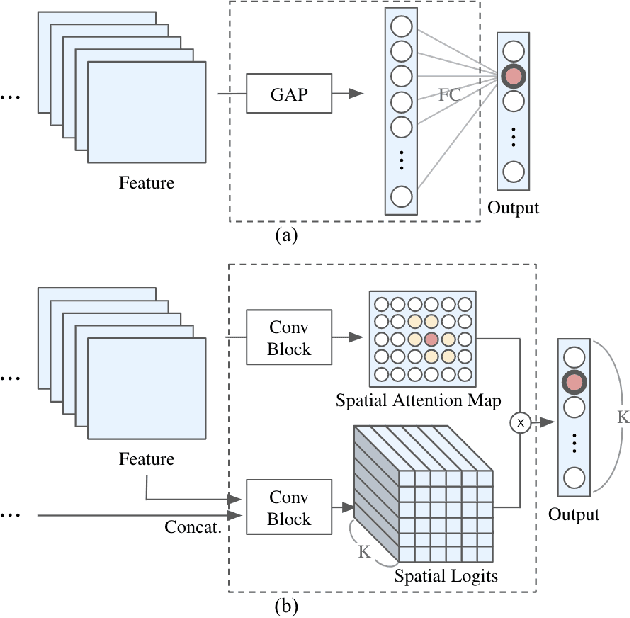
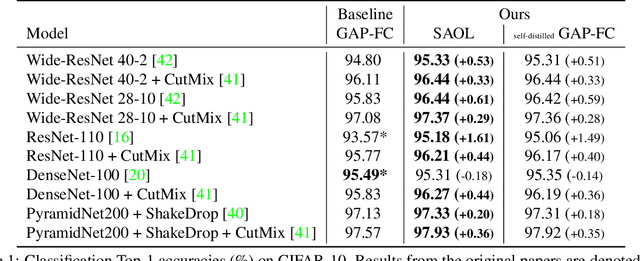
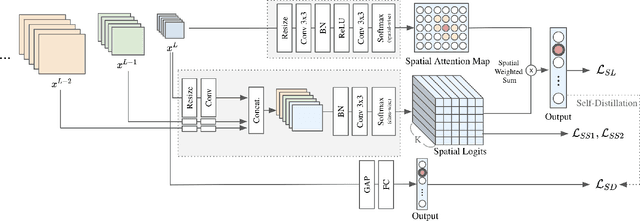
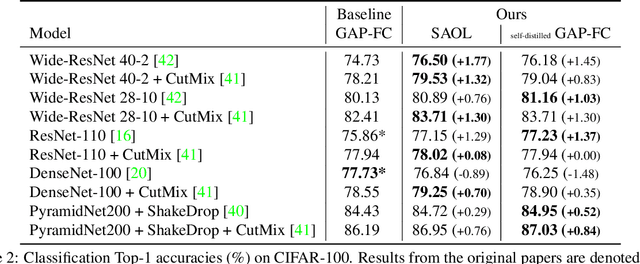
Most convolutional neural networks (CNNs) for image classification use a global average pooling (GAP) followed by a fully-connected (FC) layer for output logits. However, this spatial aggregation procedure inherently restricts the utilization of location-specific information at the output layer, although this spatial information can be beneficial for classification. In this paper, we propose a novel spatial output layer on top of the existing convolutional feature maps to explicitly exploit the location-specific output information. In specific, given the spatial feature maps, we replace the previous GAP-FC layer with a spatially attentive output layer (SAOL) by employing a attention mask on spatial logits. The proposed location-specific attention selectively aggregates spatial logits within a target region, which leads to not only the performance improvement but also spatially interpretable outputs. Moreover, the proposed SAOL also permits to fully exploit location-specific self-supervision as well as self-distillation to enhance the generalization ability during training. The proposed SAOL with self-supervision and self-distillation can be easily plugged into existing CNNs. Experimental results on various classification tasks with representative architectures show consistent performance improvements by SAOL at almost the same computational cost.
Scalable Neural Architecture Search for 3D Medical Image Segmentation
Jun 13, 2019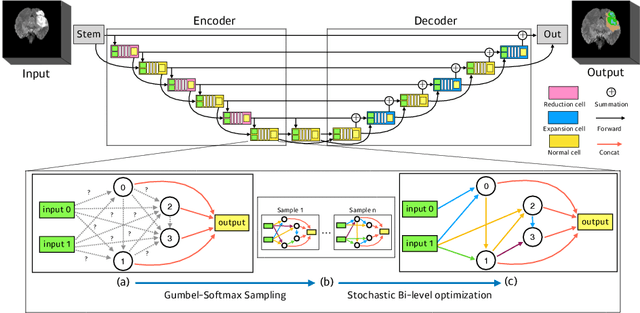
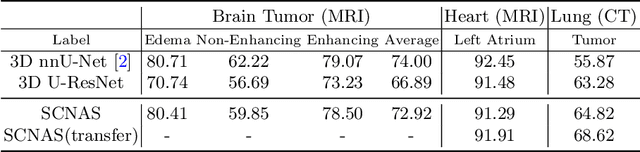
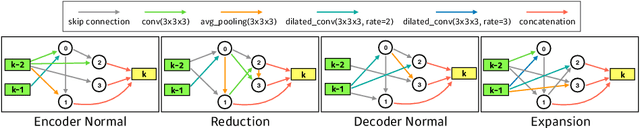
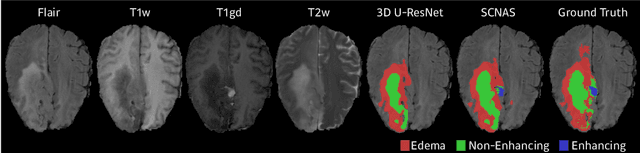
In this paper, a neural architecture search (NAS) framework is proposed for 3D medical image segmentation, to automatically optimize a neural architecture from a large design space. Our NAS framework searches the structure of each layer including neural connectivities and operation types in both of the encoder and decoder. Since optimizing over a large discrete architecture space is difficult due to high-resolution 3D medical images, a novel stochastic sampling algorithm based on a continuous relaxation is also proposed for scalable gradient based optimization. On the 3D medical image segmentation tasks with a benchmark dataset, an automatically designed architecture by the proposed NAS framework outperforms the human-designed 3D U-Net, and moreover this optimized architecture is well suited to be transferred for different tasks.
Fast AutoAugment
May 25, 2019


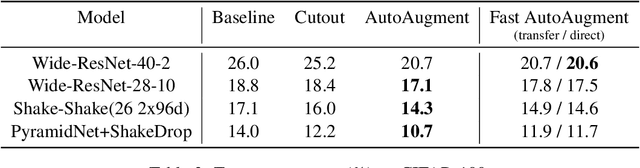
Data augmentation is an essential technique for improving generalization ability of deep learning models. Recently, AutoAugment has been proposed as an algorithm to automatically search for augmentation policies from a dataset and has significantly enhanced performances on many image recognition tasks. However, its search method requires thousands of GPU hours even for a relatively small dataset. In this paper, we propose an algorithm called Fast AutoAugment that finds effective augmentation policies via a more efficient search strategy based on density matching. In comparison to AutoAugment, the proposed algorithm speeds up the search time by orders of magnitude while achieves comparable performances on image recognition tasks with various models and datasets including CIFAR-10, CIFAR-100, SVHN, and ImageNet.