 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVS-Adapter: Plug-and-Play Novel View Synthesis from a Single Image
Dec 12, 2023
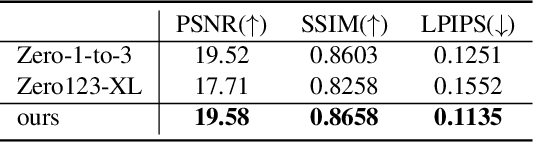
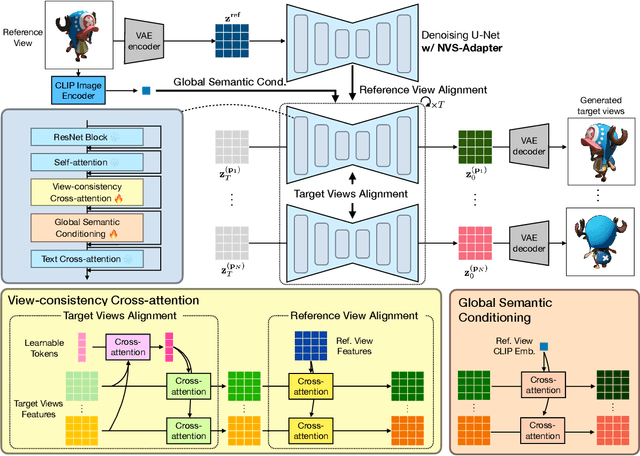
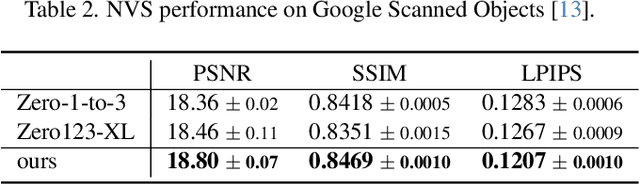
Transfer learning of large-scale Text-to-Image (T2I) models has recently shown impressive potential for Novel View Synthesis (NVS) of diverse objects from a single image. While previous methods typically train large models on multi-view datasets for NVS, fine-tuning the whole parameters of T2I models not only demands a high cost but also reduces the generalization capacity of T2I models in generating diverse images in a new domain. In this study, we propose an effective method, dubbed NVS-Adapter, which is a plug-and-play module for a T2I model, to synthesize novel multi-views of visual objects while fully exploiting the generalization capacity of T2I models. NVS-Adapter consists of two main components; view-consistency cross-attention learns the visual correspondences to align the local details of view features, and global semantic conditioning aligns the semantic structure of generated views with the reference view. Experimental results demonstrate that the NVS-Adapter can effectively synthesize geometrically consistent multi-views and also achieve high performance on benchmarks without full fine-tuning of T2I models. The code and data are publicly available in ~\href{https://postech-cvlab.github.io/nvsadapter/}{https://postech-cvlab.github.io/nvsadapter/}.
Locality-Aware Generalizable Implicit Neural Representation
Oct 12, 2023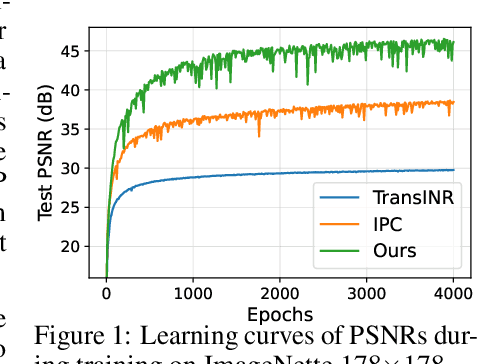
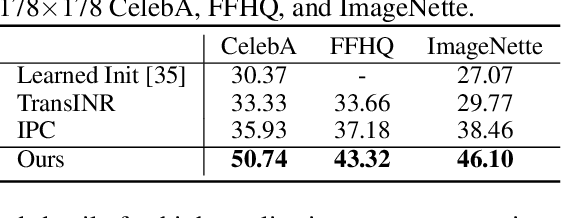
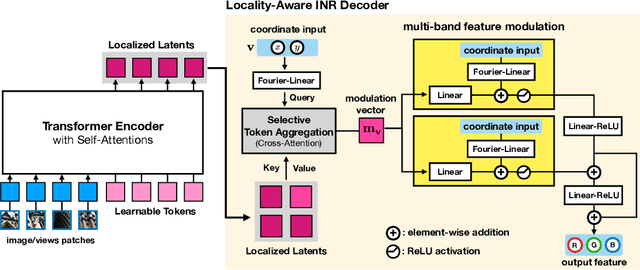

Generalizable implicit neural representation (INR) enables a single continuous function, i.e., a coordinate-based neural network, to represent multiple data instances by modulating its weights or intermediate features using latent codes. However, the expressive power of the state-of-the-art modulation is limited due to its inability to localize and capture fine-grained details of data entities such as specific pixels and rays. To address this issue, we propose a novel framework for generalizable INR that combines a transformer encoder with a locality-aware INR decoder. The transformer encoder predicts a set of latent tokens from a data instance to encode local information into each latent token. The locality-aware INR decoder extracts a modulation vector by selectively aggregating the latent tokens via cross-attention for a coordinate input and then predicts the output by progressively decoding with coarse-to-fine modulation through multiple frequency bandwidths. The selective token aggregation and the multi-band feature modulation enable us to learn locality-aware representation in spatial and spectral aspects, respectively. Our framework significantly outperforms previous generalizable INRs and validates the usefulness of the locality-aware latents for downstream tasks such as image generation.
Towards End-to-End Generative Modeling of Long Videos with Memory-Efficient Bidirectional Transformers
Mar 27, 2023Autoregressive transformers have shown remarkable success in video generation. However, the transformers are prohibited from directly learning the long-term dependency in videos due to the quadratic complexity of self-attention, and inherently suffering from slow inference time and error propagation due to the autoregressive process. In this paper, we propose Memory-efficient Bidirectional Transformer (MeBT) for end-to-end learning of long-term dependency in videos and fast inference. Based on recent advances in bidirectional transformers, our method learns to decode the entire spatio-temporal volume of a video in parallel from partially observed patches. The proposed transformer achieves a linear time complexity in both encoding and decoding, by projecting observable context tokens into a fixed number of latent tokens and conditioning them to decode the masked tokens through the cross-attention. Empowered by linear complexity and bidirectional modeling, our method demonstrates significant improvement over the autoregressive Transformers for generating moderately long videos in both quality and speed. Videos and code are available at https://sites.google.com/view/mebt-cvpr2023 .
Generalizable Implicit Neural Representations via Instance Pattern Composers
Nov 23, 2022



Despite recent advances in implicit neural representations (INRs), it remains challenging for a coordinate-based multi-layer perceptron (MLP) of INRs to learn a common representation across data instances and generalize it for unseen instances. In this work, we introduce a simple yet effective framework for generalizable INRs that enables a coordinate-based MLP to represent complex data instances by modulating only a small set of weights in an early MLP layer as an instance pattern composer; the remaining MLP weights learn pattern composition rules for common representations across instances. Our generalizable INR framework is fully compatible with existing meta-learning and hypernetworks in learning to predict the modulated weight for unseen instances. Extensive experiments demonstrate that our method achieves high performance on a wide range of domains such as an audio, image, and 3D object, while the ablation study validates our weight modulation.
Draft-and-Revise: Effective Image Generation with Contextual RQ-Transformer
Jun 09, 2022
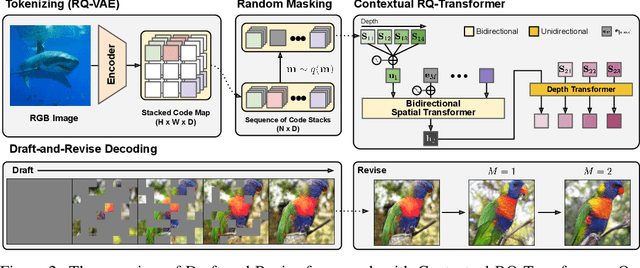
Although autoregressive models have achieved promising results on image generation, their unidirectional generation process prevents the resultant images from fully reflecting global contexts. To address the issue, we propose an effective image generation framework of Draft-and-Revise with Contextual RQ-transformer to consider global contexts during the generation process. As a generalized VQ-VAE, RQ-VAE first represents a high-resolution image as a sequence of discrete code stacks. After code stacks in the sequence are randomly masked, Contextual RQ-Transformer is trained to infill the masked code stacks based on the unmasked contexts of the image. Then, Contextual RQ-Transformer uses our two-phase decoding, Draft-and-Revise, and generates an image, while exploiting the global contexts of the image during the generation process. Specifically. in the draft phase, our model first focuses on generating diverse images despite rather low quality. Then, in the revise phase, the model iteratively improves the quality of images, while preserving the global contexts of generated images. In experiments, our method achieves state-of-the-art results on conditional image generation. We also validate that the Draft-and-Revise decoding can achieve high performance by effectively controlling the quality-diversity trade-off in image generation.
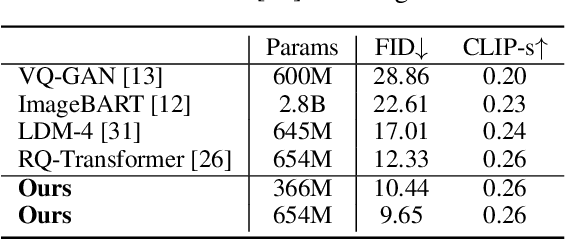
Autoregressive Image Generation using Residual Quantization
Mar 09, 2022
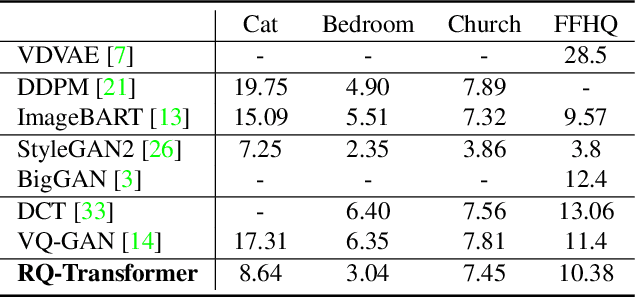
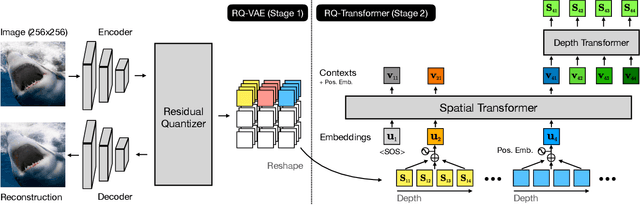

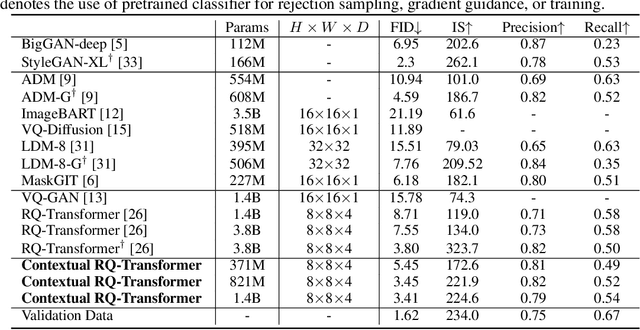
For autoregressive (AR) modeling of high-resolution images, vector quantization (VQ) represents an image as a sequence of discrete codes. A short sequence length is important for an AR model to reduce its computational costs to consider long-range interactions of codes. However, we postulate that previous VQ cannot shorten the code sequence and generate high-fidelity images together in terms of the rate-distortion trade-off. In this study, we propose the two-stage framework, which consists of Residual-Quantized VAE (RQ-VAE) and RQ-Transformer, to effectively generate high-resolution images. Given a fixed codebook size, RQ-VAE can precisely approximate a feature map of an image and represent the image as a stacked map of discrete codes. Then, RQ-Transformer learns to predict the quantized feature vector at the next position by predicting the next stack of codes. Thanks to the precise approximation of RQ-VAE, we can represent a 256$\times$256 image as 8$\times$8 resolution of the feature map, and RQ-Transformer can efficiently reduce the computational costs. Consequently, our framework outperforms the existing AR models on various benchmarks of unconditional and conditional image generation. Our approach also has a significantly faster sampling speed than previous AR models to generate high-quality images.
Automated Learning Rate Scheduler for Large-batch Training
Jul 13, 2021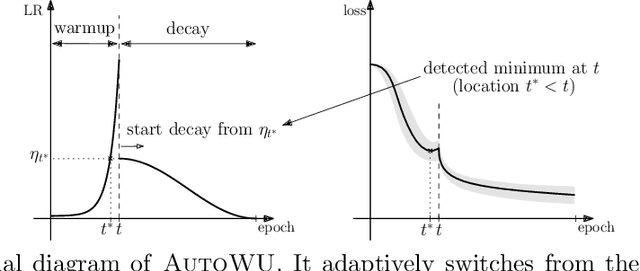
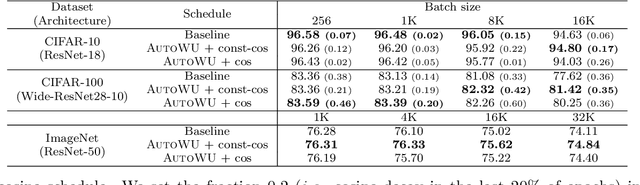
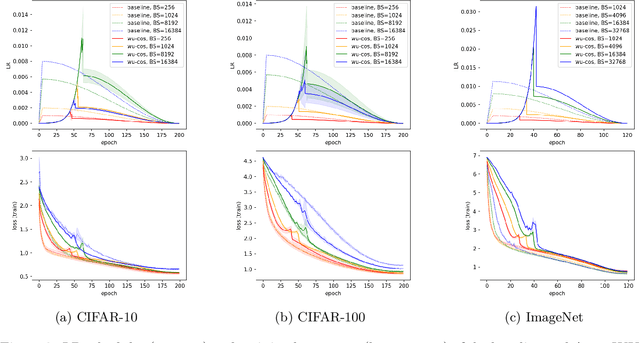

Large-batch training has been essential in leveraging large-scale datasets and models in deep learning. While it is computationally beneficial to use large batch sizes, it often requires a specially designed learning rate (LR) schedule to achieve a comparable level of performance as in smaller batch training. Especially, when the number of training epochs is constrained, the use of a large LR and a warmup strategy is critical in the final performance of large-batch training due to the reduced number of updating steps. In this work, we propose an automated LR scheduling algorithm which is effective for neural network training with a large batch size under the given epoch budget. In specific, the whole schedule consists of two phases: adaptive warmup and predefined decay, where the LR is increased until the training loss no longer decreases and decreased to zero until the end of training. Here, whether the training loss has reached the minimum value is robustly checked with Gaussian process smoothing in an online manner with a low computational burden. Coupled with adaptive stochastic optimizers such as AdamP and LAMB, the proposed scheduler successfully adjusts the LRs without cumbersome hyperparameter tuning and achieves comparable or better performances than tuned baselines on various image classification benchmarks and architectures with a wide range of batch sizes.
torchgpipe: On-the-fly Pipeline Parallelism for Training Giant Models
Apr 21, 2020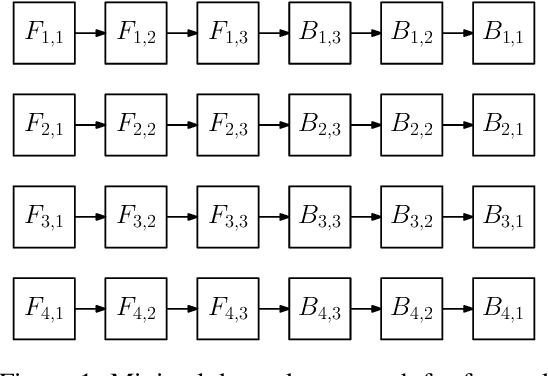

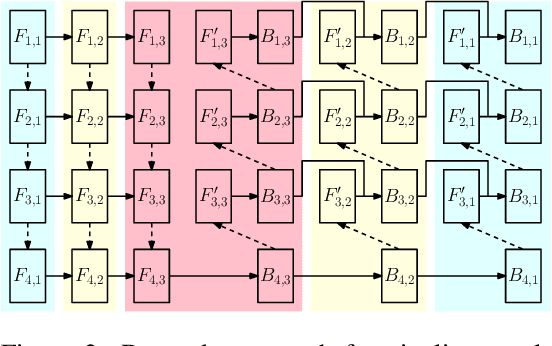
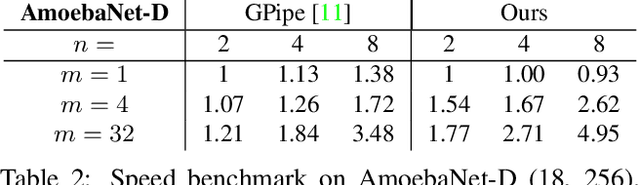
We design and implement a ready-to-use library in PyTorch for performing micro-batch pipeline parallelism with checkpointing proposed by GPipe (Huang et al., 2019). In particular, we develop a set of design components to enable pipeline-parallel gradient computation in PyTorch's define-by-run and eager execution environment. We show that each component is necessary to fully benefit from pipeline parallelism in such environment, and demonstrate the efficiency of the library by applying it to various network architectures including AmoebaNet-D and U-Net. Our library is available at https://github.com/kakaobrain/torchgpipe .
Mining GOLD Samples for Conditional GANs
Oct 21, 2019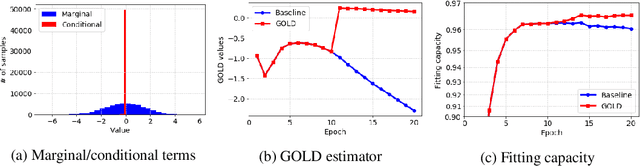
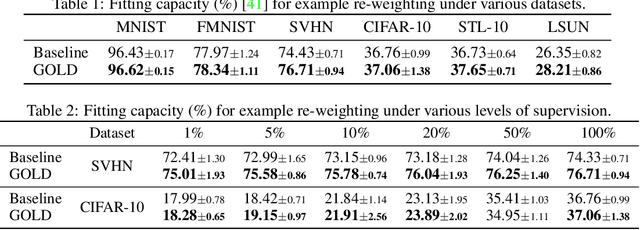
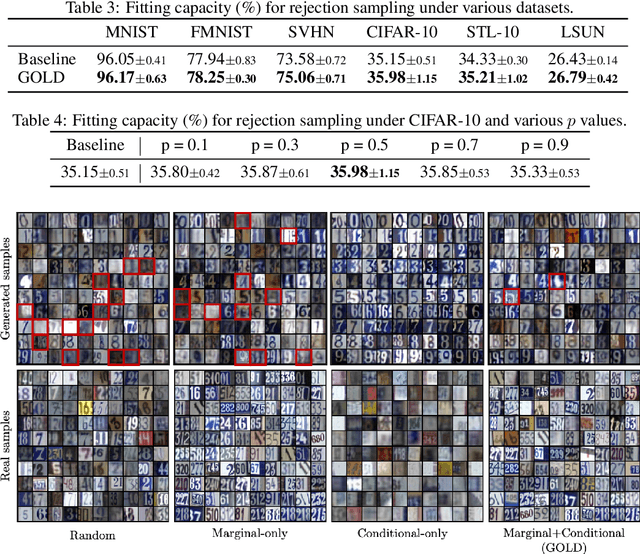
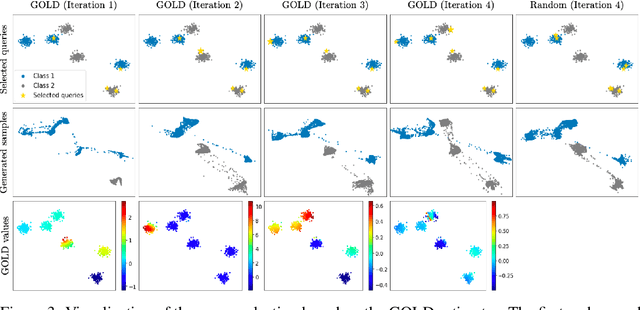
Conditional generative adversarial networks (cGANs) have gained a considerable attention in recent years due to its class-wise controllability and superior quality for complex generation tasks. We introduce a simple yet effective approach to improving cGANs by measuring the discrepancy between the data distribution and the model distribution on given samples. The proposed measure, coined the gap of log-densities (GOLD), provides an effective self-diagnosis for cGANs while being efficienty computed from the discriminator. We propose three applications of the GOLD: example re-weighting, rejection sampling, and active learning, which improve the training, inference, and data selection of cGANs, respectively. Our experimental results demonstrate that the proposed methods outperform corresponding baselines for all three applications on different image datasets.
Scalable Neural Architecture Search for 3D Medical Image Segmentation
Jun 13, 2019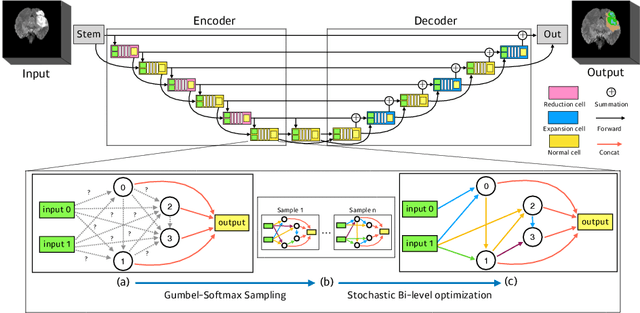
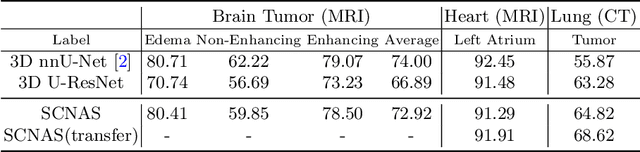
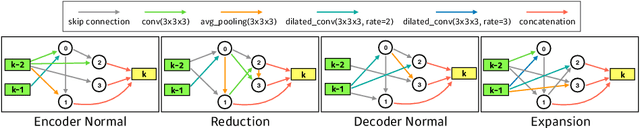
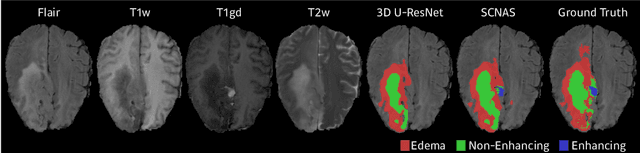
In this paper, a neural architecture search (NAS) framework is proposed for 3D medical image segmentation, to automatically optimize a neural architecture from a large design space. Our NAS framework searches the structure of each layer including neural connectivities and operation types in both of the encoder and decoder. Since optimizing over a large discrete architecture space is difficult due to high-resolution 3D medical images, a novel stochastic sampling algorithm based on a continuous relaxation is also proposed for scalable gradient based optimization. On the 3D medical image segmentation tasks with a benchmark dataset, an automatically designed architecture by the proposed NAS framework outperforms the human-designed 3D U-Net, and moreover this optimized architecture is well suited to be transferred for different tasks.