 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulation-Free Training of Neural ODEs on Paired Data
Oct 30, 2024In this work, we investigate a method for simulation-free training of Neural Ordinary Differential Equations (NODEs) for learning deterministic mappings between paired data. Despite the analogy of NODEs as continuous-depth residual networks, their application in typical supervised learning tasks has not been popular, mainly due to the large number of function evaluations required by ODE solvers and numerical instability in gradient estimation. To alleviate this problem, we employ the flow matching framework for simulation-free training of NODEs, which directly regresses the parameterized dynamics function to a predefined target velocity field. Contrary to generative tasks, however, we show that applying flow matching directly between paired data can often lead to an ill-defined flow that breaks the coupling of the data pairs (e.g., due to crossing trajectories). We propose a simple extension that applies flow matching in the embedding space of data pairs, where the embeddings are learned jointly with the dynamic function to ensure the validity of the flow which is also easier to learn. We demonstrate the effectiveness of our method on both regression and classification tasks, where our method outperforms existing NODEs with a significantly lower number of function evaluations. The code is available at https://github.com/seminkim/simulation-free-node.
Variational Distribution Learning for Unsupervised Text-to-Image Generation
Mar 28, 2023



We propose a text-to-image generation algorithm based on deep neural networks when text captions for images are unavailable during training. In this work, instead of simply generating pseudo-ground-truth sentences of training images using existing image captioning methods, we employ a pretrained CLIP model, which is capable of properly aligning embeddings of images and corresponding texts in a joint space and, consequently, works well on zero-shot recognition tasks. We optimize a text-to-image generation model by maximizing the data log-likelihood conditioned on pairs of image-text CLIP embeddings. To better align data in the two domains, we employ a principled way based on a variational inference, which efficiently estimates an approximate posterior of the hidden text embedding given an image and its CLIP feature. Experimental results validate that the proposed framework outperforms existing approaches by large margins under unsupervised and semi-supervised text-to-image generation settings.
Generalizable Implicit Neural Representations via Instance Pattern Composers
Nov 23, 2022



Despite recent advances in implicit neural representations (INRs), it remains challenging for a coordinate-based multi-layer perceptron (MLP) of INRs to learn a common representation across data instances and generalize it for unseen instances. In this work, we introduce a simple yet effective framework for generalizable INRs that enables a coordinate-based MLP to represent complex data instances by modulating only a small set of weights in an early MLP layer as an instance pattern composer; the remaining MLP weights learn pattern composition rules for common representations across instances. Our generalizable INR framework is fully compatible with existing meta-learning and hypernetworks in learning to predict the modulated weight for unseen instances. Extensive experiments demonstrate that our method achieves high performance on a wide range of domains such as an audio, image, and 3D object, while the ablation study validates our weight modulation.
Draft-and-Revise: Effective Image Generation with Contextual RQ-Transformer
Jun 09, 2022
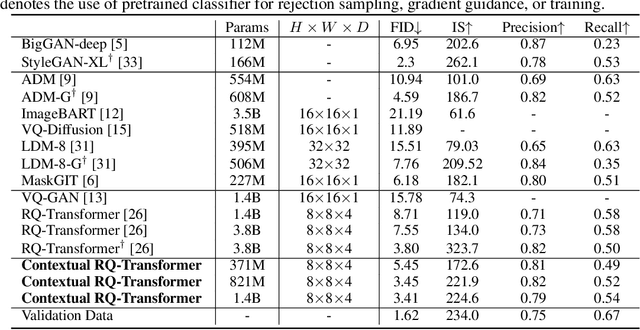
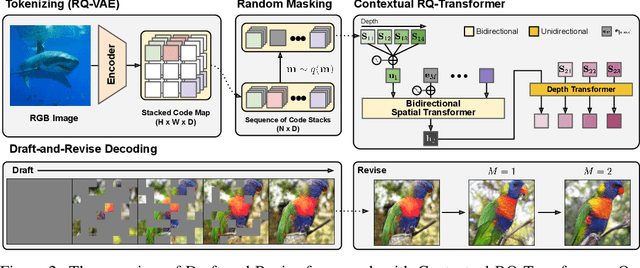
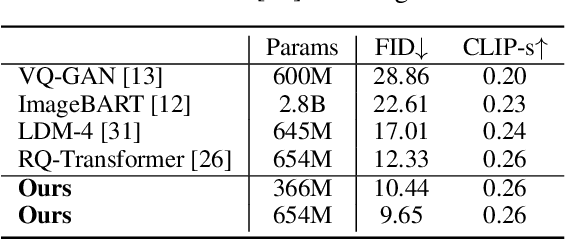
Although autoregressive models have achieved promising results on image generation, their unidirectional generation process prevents the resultant images from fully reflecting global contexts. To address the issue, we propose an effective image generation framework of Draft-and-Revise with Contextual RQ-transformer to consider global contexts during the generation process. As a generalized VQ-VAE, RQ-VAE first represents a high-resolution image as a sequence of discrete code stacks. After code stacks in the sequence are randomly masked, Contextual RQ-Transformer is trained to infill the masked code stacks based on the unmasked contexts of the image. Then, Contextual RQ-Transformer uses our two-phase decoding, Draft-and-Revise, and generates an image, while exploiting the global contexts of the image during the generation process. Specifically. in the draft phase, our model first focuses on generating diverse images despite rather low quality. Then, in the revise phase, the model iteratively improves the quality of images, while preserving the global contexts of generated images. In experiments, our method achieves state-of-the-art results on conditional image generation. We also validate that the Draft-and-Revise decoding can achieve high performance by effectively controlling the quality-diversity trade-off in image generation.
Autoregressive Image Generation using Residual Quantization
Mar 09, 2022
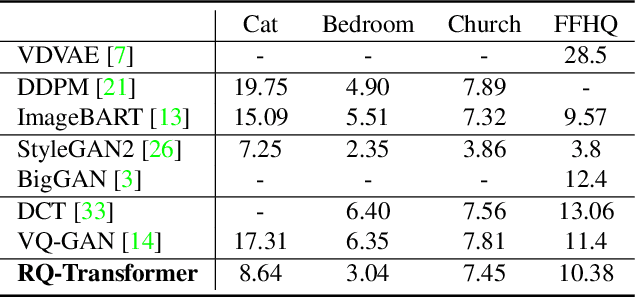
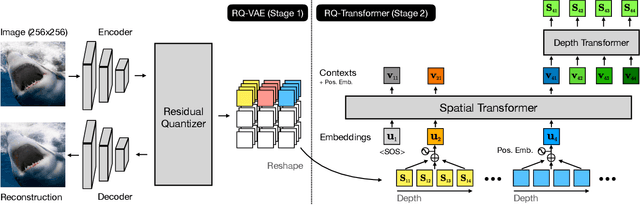

For autoregressive (AR) modeling of high-resolution images, vector quantization (VQ) represents an image as a sequence of discrete codes. A short sequence length is important for an AR model to reduce its computational costs to consider long-range interactions of codes. However, we postulate that previous VQ cannot shorten the code sequence and generate high-fidelity images together in terms of the rate-distortion trade-off. In this study, we propose the two-stage framework, which consists of Residual-Quantized VAE (RQ-VAE) and RQ-Transformer, to effectively generate high-resolution images. Given a fixed codebook size, RQ-VAE can precisely approximate a feature map of an image and represent the image as a stacked map of discrete codes. Then, RQ-Transformer learns to predict the quantized feature vector at the next position by predicting the next stack of codes. Thanks to the precise approximation of RQ-VAE, we can represent a 256$\times$256 image as 8$\times$8 resolution of the feature map, and RQ-Transformer can efficiently reduce the computational costs. Consequently, our framework outperforms the existing AR models on various benchmarks of unconditional and conditional image generation. Our approach also has a significantly faster sampling speed than previous AR models to generate high-quality images.
Sparse DETR: Efficient End-to-End Object Detection with Learnable Sparsity
Nov 29, 2021
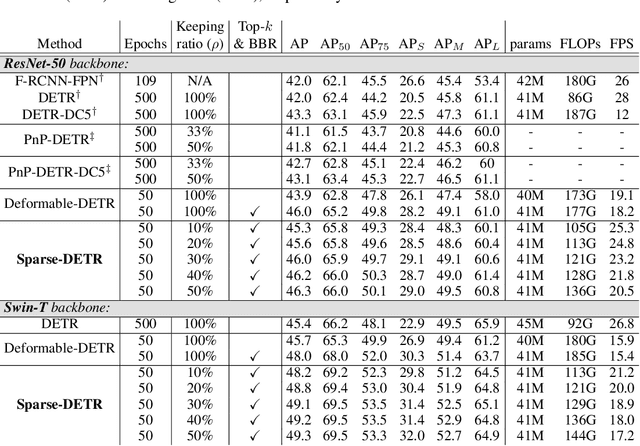
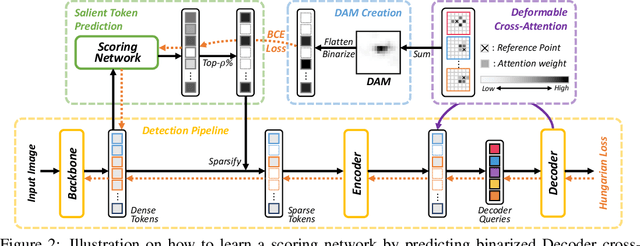
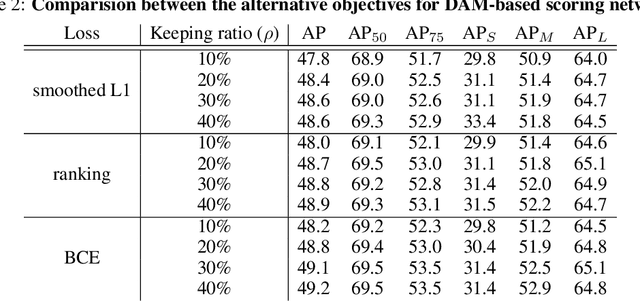
DETR is the first end-to-end object detector using a transformer encoder-decoder architecture and demonstrates competitive performance but low computational efficiency on high resolution feature maps. The subsequent work, Deformable DETR, enhances the efficiency of DETR by replacing dense attention with deformable attention, which achieves 10x faster convergence and improved performance. Deformable DETR uses the multiscale feature to ameliorate performance, however, the number of encoder tokens increases by 20x compared to DETR, and the computation cost of the encoder attention remains a bottleneck. In our preliminary experiment, we observe that the detection performance hardly deteriorates even if only a part of the encoder token is updated. Inspired by this observation, we propose Sparse DETR that selectively updates only the tokens expected to be referenced by the decoder, thus help the model effectively detect objects. In addition, we show that applying an auxiliary detection loss on the selected tokens in the encoder improves the performance while minimizing computational overhead. We validate that Sparse DETR achieves better performance than Deformable DETR even with only 10% encoder tokens on the COCO dataset. Albeit only the encoder tokens are sparsified, the total computation cost decreases by 38% and the frames per second (FPS) increases by 42% compared to Deformable DETR. Code is available at https://github.com/kakaobrain/sparse-detr
Automated Learning Rate Scheduler for Large-batch Training
Jul 13, 2021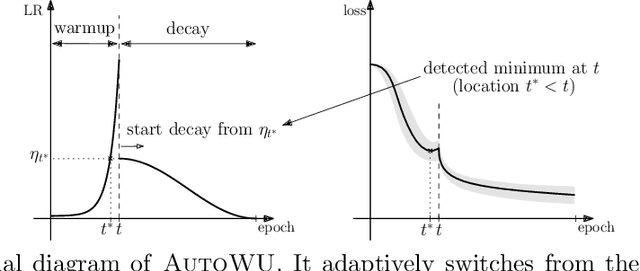
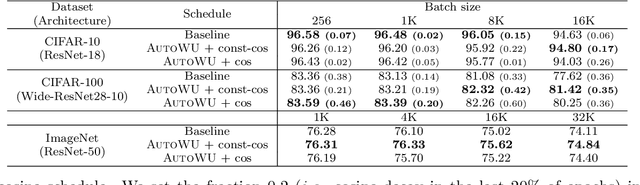
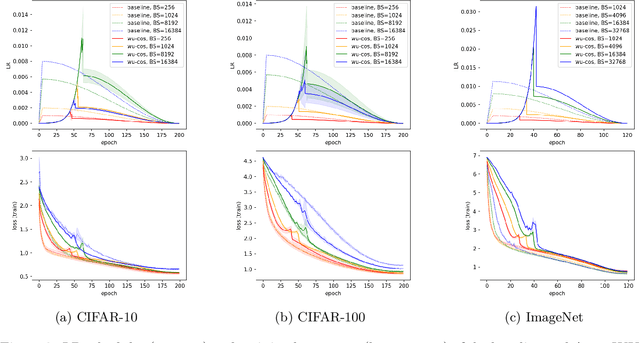

Large-batch training has been essential in leveraging large-scale datasets and models in deep learning. While it is computationally beneficial to use large batch sizes, it often requires a specially designed learning rate (LR) schedule to achieve a comparable level of performance as in smaller batch training. Especially, when the number of training epochs is constrained, the use of a large LR and a warmup strategy is critical in the final performance of large-batch training due to the reduced number of updating steps. In this work, we propose an automated LR scheduling algorithm which is effective for neural network training with a large batch size under the given epoch budget. In specific, the whole schedule consists of two phases: adaptive warmup and predefined decay, where the LR is increased until the training loss no longer decreases and decreased to zero until the end of training. Here, whether the training loss has reached the minimum value is robustly checked with Gaussian process smoothing in an online manner with a low computational burden. Coupled with adaptive stochastic optimizers such as AdamP and LAMB, the proposed scheduler successfully adjusts the LRs without cumbersome hyperparameter tuning and achieves comparable or better performances than tuned baselines on various image classification benchmarks and architectures with a wide range of batch sizes.
Hybrid Generative-Contrastive Representation Learning
Jun 11, 2021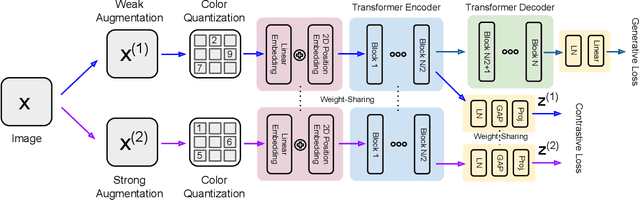
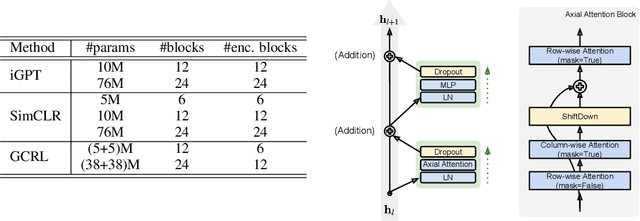

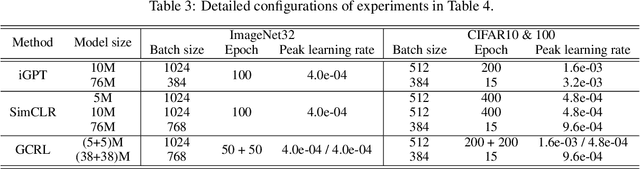
Unsupervised representation learning has recently received lots of interest due to its powerful generalizability through effectively leveraging large-scale unlabeled data. There are two prevalent approaches for this, contrastive learning and generative pre-training, where the former learns representations from instance-wise discrimination tasks and the latter learns them from estimating the likelihood. These seemingly orthogonal approaches have their own strengths and weaknesses. Contrastive learning tends to extract semantic information and discards details irrelevant for classifying objects, making the representations effective for discriminative tasks while degrading robustness to out-of-distribution data. On the other hand, the generative pre-training directly estimates the data distribution, so the representations tend to be robust but not optimal for discriminative tasks. In this paper, we show that we could achieve the best of both worlds by a hybrid training scheme. Specifically, we demonstrated that a transformer-based encoder-decoder architecture trained with both contrastive and generative losses can learn highly discriminative and robust representations without hurting the generative performance. We extensively validate our approach on various tasks.
Learning to Balance: Bayesian Meta-Learning for Imbalanced and Out-of-distribution Tasks
May 30, 2019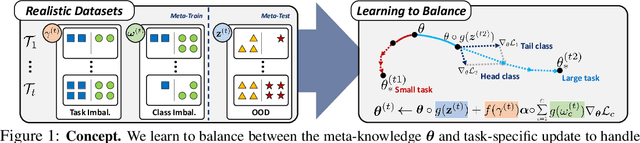
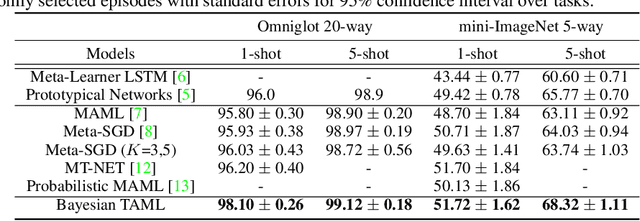
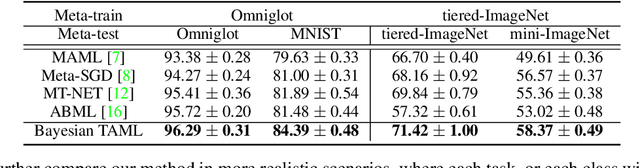
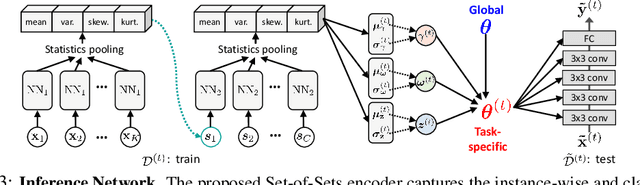
While tasks could come with varying number of instances in realistic settings, the existing meta-learning approaches for few-shot classfication assume even task distributions where the number of instances for each task and class are fixed. Due to such restriction, they learn to equally utilize the meta-knowledge across all the tasks, even when the number of instances per task and class largely varies. Moreover, they do not consider distributional difference in unseen tasks at the meta-test time, on which the meta-knowledge may have varying degree of usefulness depending on the task relatedness. To overcome these limitations, we propose a novel meta-learning model that adaptively balances the effect of the meta-learning and task-specific learning, and also class-specific learning within each task. Through the learning of the balancing variables, we can decide whether to obtain a solution close to the initial parameter or far from it. We formulate this objective into a Bayesian inference framework and solve it using variational inference. Our Bayesian Task-Adaptive Meta-Learning (Bayesian-TAML) significantly outperforms existing meta-learning approaches on benchmark datasets for both few-shot and realistic class- and task-imbalanced datasets, with especially higher gains on the latter.
Bayesian Optimization over Sets
May 23, 2019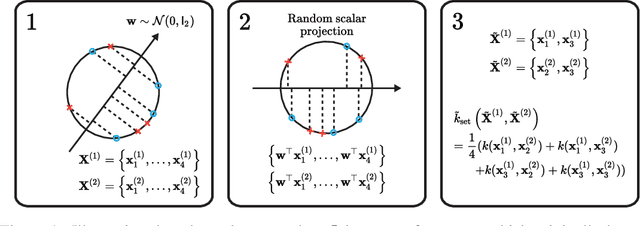
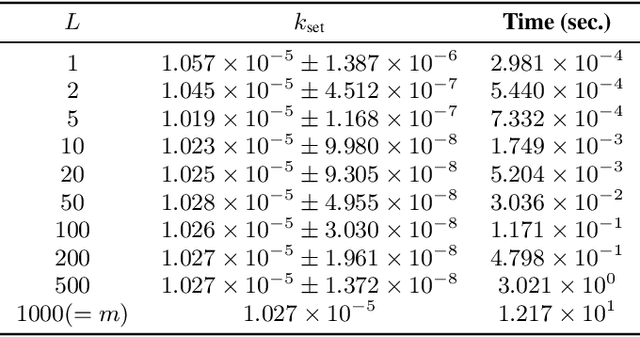
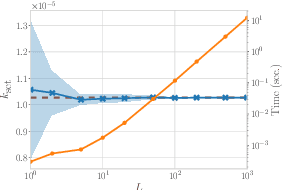
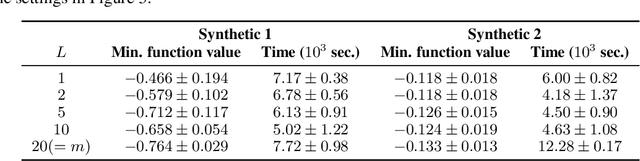
We propose a Bayesian optimization method over sets, to minimize a black-box function that can take a set as single input. Because set inputs are permutation-invariant and variable-length, traditional Gaussian process-based Bayesian optimization strategies which assume vector inputs can fall short. To address this, we develop a Bayesian optimization method with \emph{set kernel} that is used to build surrogate functions. This kernel accumulates similarity over set elements to enforce permutation-invariance and permit sets of variable size, but this comes at a greater computational cost. To reduce this burden, we propose a more efficient probabilistic approximation which we prove is still positive definite and is an unbiased estimator of the true set kernel. Finally, we present several numerical experiments which demonstrate that our method outperforms other methods in various applications.