 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Diversity in Objective Space for Sample-efficient Search of Multiobjective Optimization Problems
Jun 23, 2023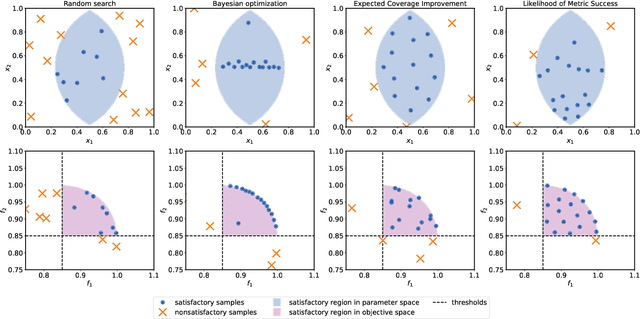
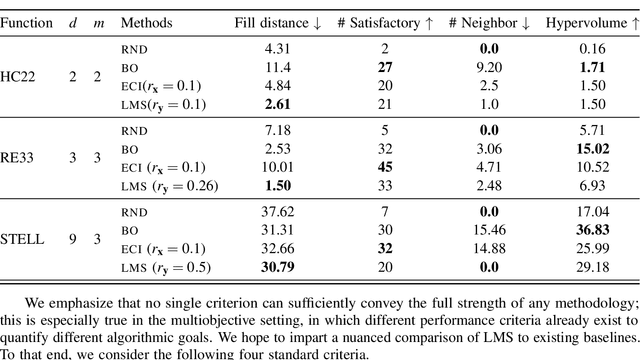
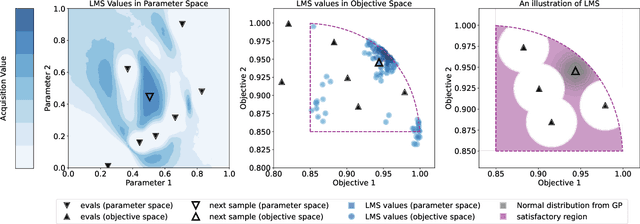
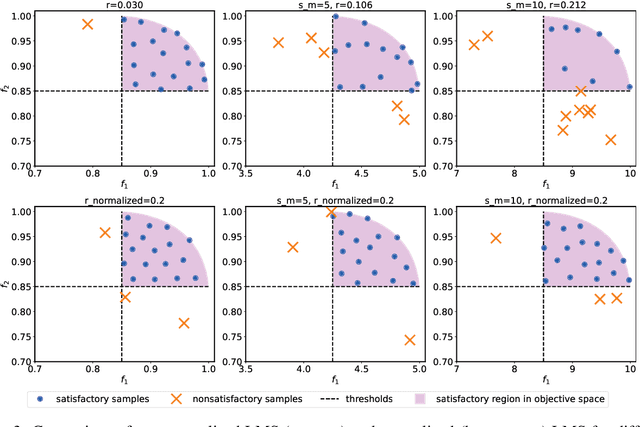
Efficiently solving multi-objective optimization problems for simulation optimization of important scientific and engineering applications such as materials design is becoming an increasingly important research topic. This is due largely to the expensive costs associated with said applications, and the resulting need for sample-efficient, multiobjective optimization methods that efficiently explore the Pareto frontier to expose a promising set of design solutions. We propose moving away from using explicit optimization to identify the Pareto frontier and instead suggest searching for a diverse set of outcomes that satisfy user-specified performance criteria. This method presents decision makers with a robust pool of promising design decisions and helps them better understand the space of good solutions. To achieve this outcome, we introduce the Likelihood of Metric Satisfaction (LMS) acquisition function, analyze its behavior and properties, and demonstrate its viability on various problems.
Bayesian Optimization is Superior to Random Search for Machine Learning Hyperparameter Tuning: Analysis of the Black-Box Optimization Challenge 2020
Apr 20, 2021
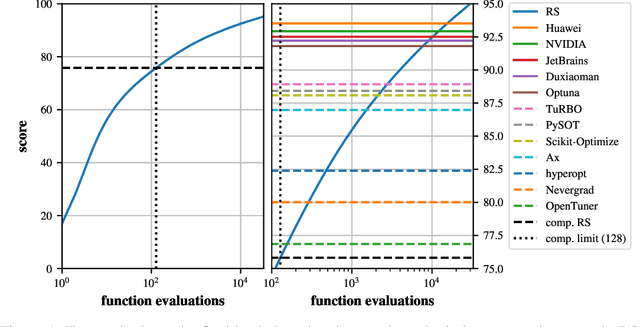
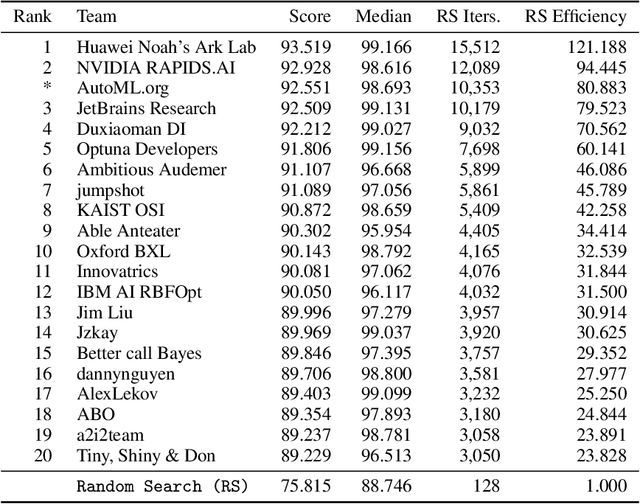
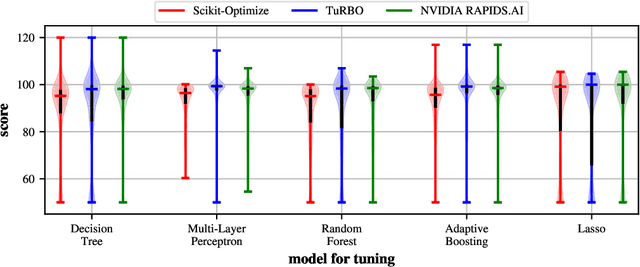
This paper presents the results and insights from the black-box optimization (BBO) challenge at NeurIPS 2020 which ran from July-October, 2020. The challenge emphasized the importance of evaluating derivative-free optimizers for tuning the hyperparameters of machine learning models. This was the first black-box optimization challenge with a machine learning emphasis. It was based on tuning (validation set) performance of standard machine learning models on real datasets. This competition has widespread impact as black-box optimization (e.g., Bayesian optimization) is relevant for hyperparameter tuning in almost every machine learning project as well as many applications outside of machine learning. The final leaderboard was determined using the optimization performance on held-out (hidden) objective functions, where the optimizers ran without human intervention. Baselines were set using the default settings of several open-source black-box optimization packages as well as random search.
Efficient Rollout Strategies for Bayesian Optimization
Feb 26, 2020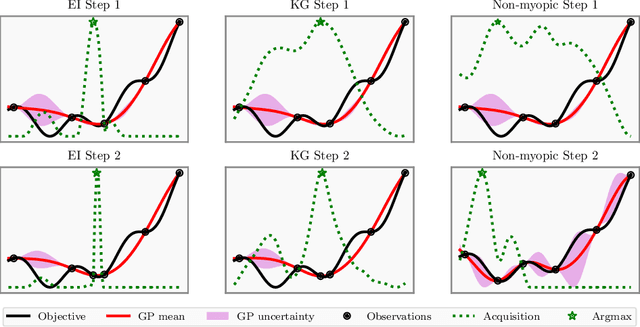
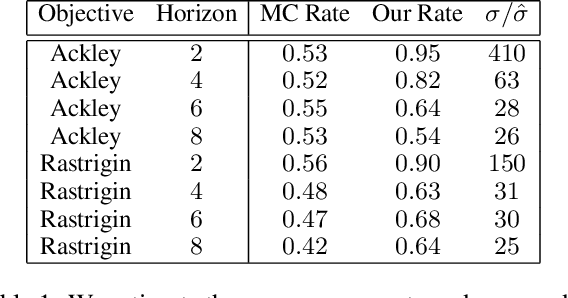
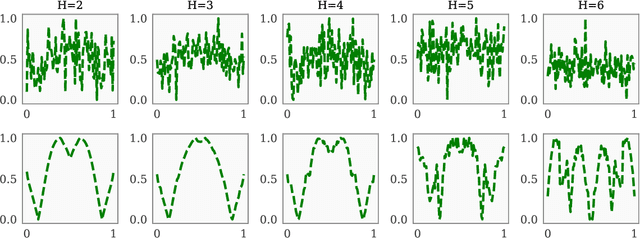
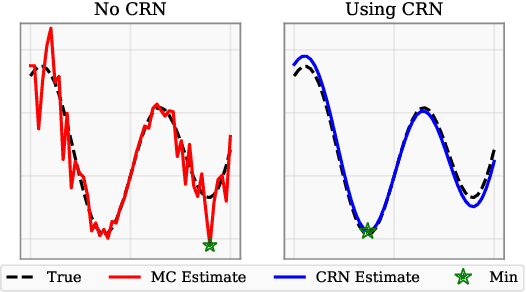
Bayesian optimization (BO) is a class of sample-efficient global optimization methods, where a probabilistic model conditioned on previous observations is used to determine future evaluations via the optimization of an acquisition function. Most acquisition functions are myopic, meaning that they only consider the impact of the next function evaluation. Non-myopic acquisition functions consider the impact of the next $h$ function evaluations and are typically computed through rollout, in which $h$ steps of BO are simulated. These rollout acquisition functions are defined as $h$-dimensional integrals, and are expensive to compute and optimize. We show that a combination of quasi-Monte Carlo, common random numbers, and control variates significantly reduce the computational burden of rollout. We then formulate a policy-search based approach that removes the need to optimize the rollout acquisition function. Finally, we discuss the qualitative behavior of rollout policies in the setting of multi-modal objectives and model error.
Sampling Humans for Optimizing Preferences in Coloring Artwork
Jun 10, 2019
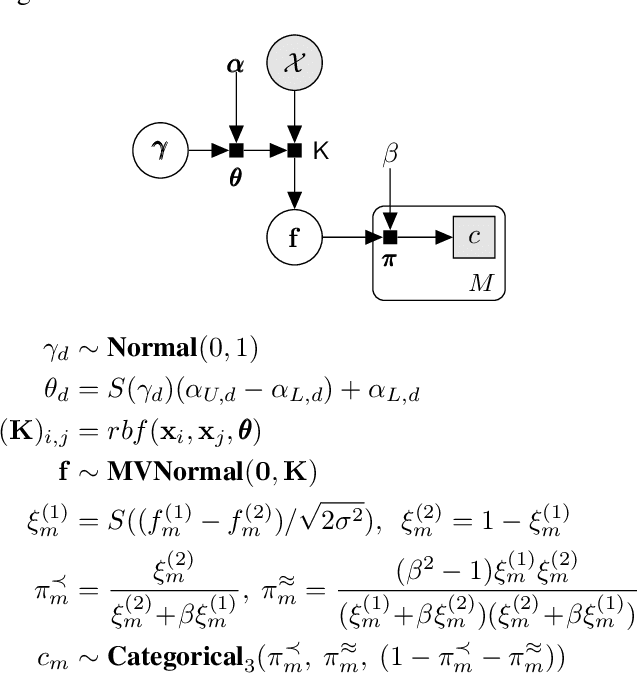

Many circumstances of practical importance have performance or success metrics which exist implicitly---in the eye of the beholder, so to speak. Tuning aspects of such problems requires working without defined metrics and only considering pairwise comparisons or rankings. In this paper, we review an existing Bayesian optimization strategy for determining most-preferred outcomes, and identify an adaptation to allow it to handle ties. We then discuss some of the issues we have encountered when humans use this optimization strategy to optimize coloring a piece of abstract artwork. We hope that, by participating in this workshop, we can learn how other researchers encounter difficulties unique to working with humans in the loop.
Bayesian Optimization over Sets
May 23, 2019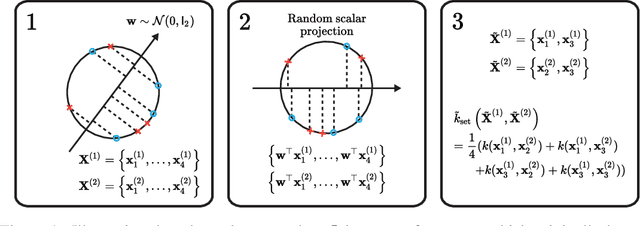
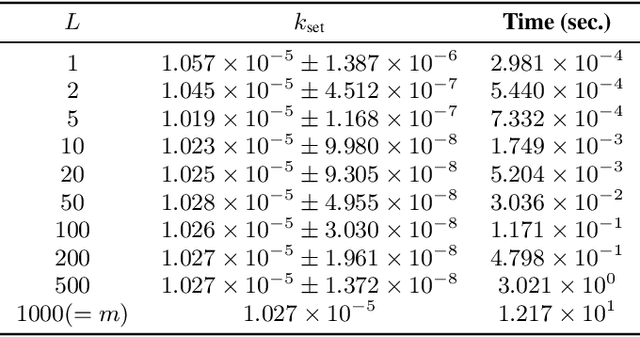
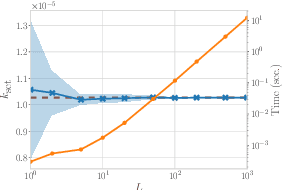
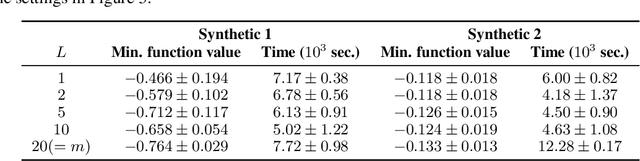
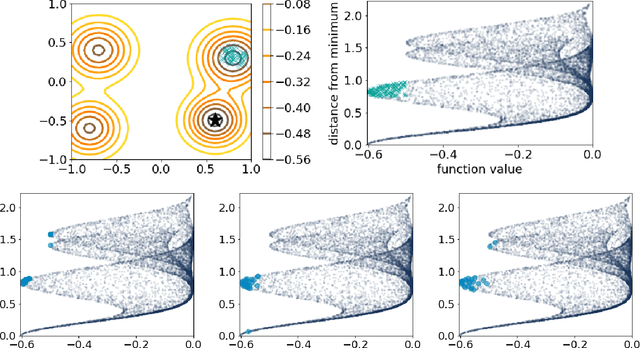
We propose a Bayesian optimization method over sets, to minimize a black-box function that can take a set as single input. Because set inputs are permutation-invariant and variable-length, traditional Gaussian process-based Bayesian optimization strategies which assume vector inputs can fall short. To address this, we develop a Bayesian optimization method with \emph{set kernel} that is used to build surrogate functions. This kernel accumulates similarity over set elements to enforce permutation-invariance and permit sets of variable size, but this comes at a greater computational cost. To reduce this burden, we propose a more efficient probabilistic approximation which we prove is still positive definite and is an unbiased estimator of the true set kernel. Finally, we present several numerical experiments which demonstrate that our method outperforms other methods in various applications.
Sequential Preference-Based Optimization
Jan 09, 2018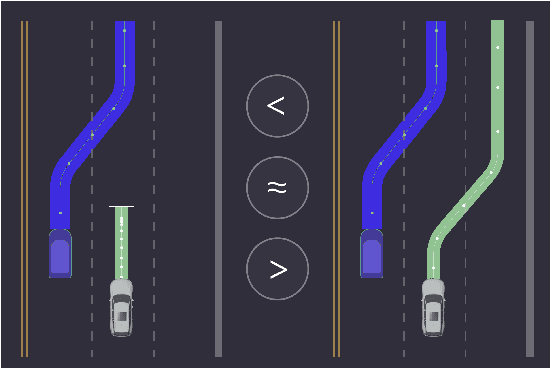


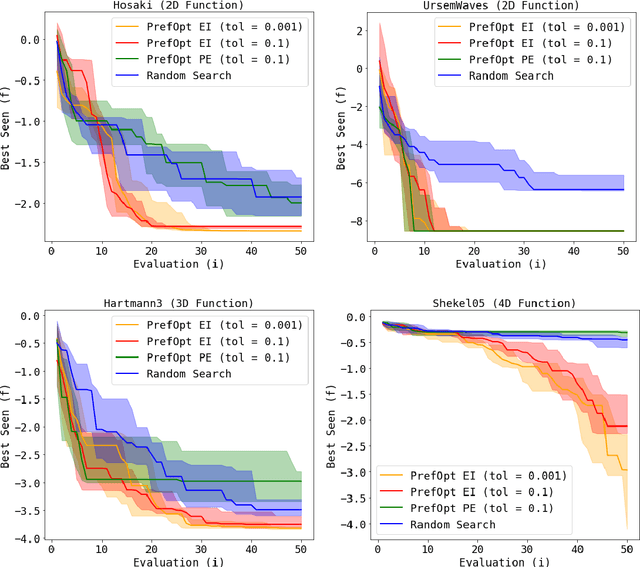
Many real-world engineering problems rely on human preferences to guide their design and optimization. We present PrefOpt, an open source package to simplify sequential optimization tasks that incorporate human preference feedback. Our approach extends an existing latent variable model for binary preferences to allow for observations of equivalent preference from users.
Practical Bayesian optimization in the presence of outliers
Dec 12, 2017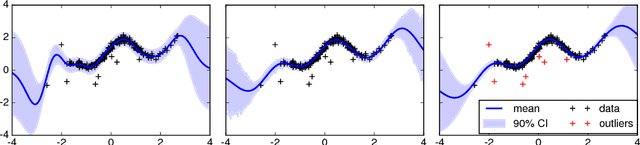
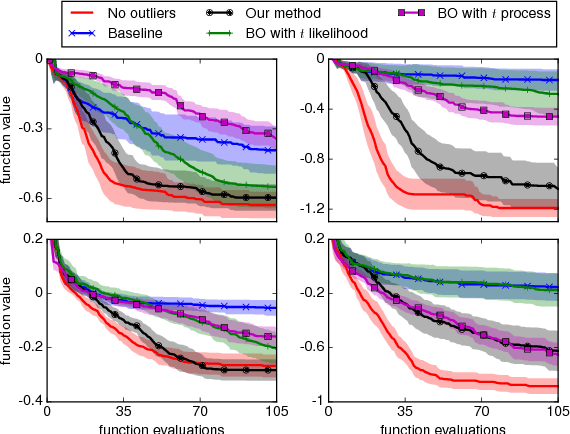
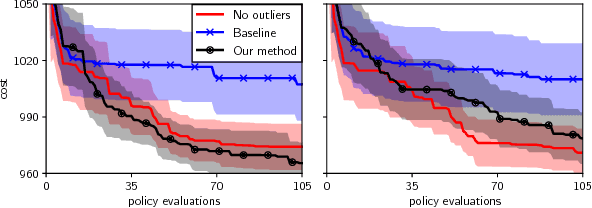
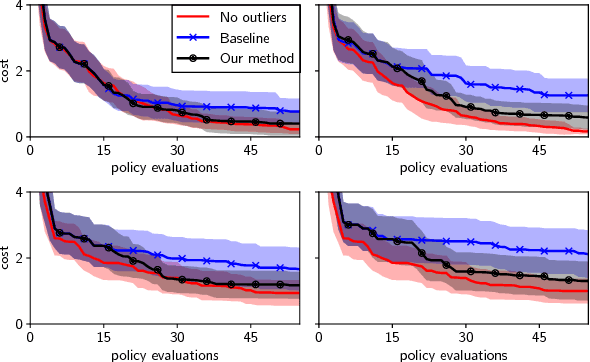
Inference in the presence of outliers is an important field of research as outliers are ubiquitous and may arise across a variety of problems and domains. Bayesian optimization is method that heavily relies on probabilistic inference. This allows outstanding sample efficiency because the probabilistic machinery provides a memory of the whole optimization process. However, that virtue becomes a disadvantage when the memory is populated with outliers, inducing bias in the estimation. In this paper, we present an empirical evaluation of Bayesian optimization methods in the presence of outliers. The empirical evidence shows that Bayesian optimization with robust regression often produces suboptimal results. We then propose a new algorithm which combines robust regression (a Gaussian process with Student-t likelihood) with outlier diagnostics to classify data points as outliers or inliers. By using an scheduler for the classification of outliers, our method is more efficient and has better convergence over the standard robust regression. Furthermore, we show that even in controlled situations with no expected outliers, our method is able to produce better results.
Robust Bayesian Optimization with Student-t Likelihood
Jul 18, 2017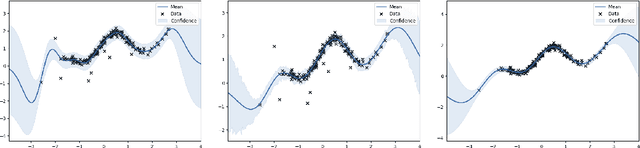
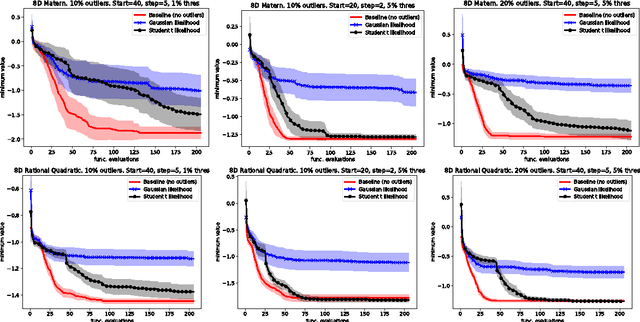
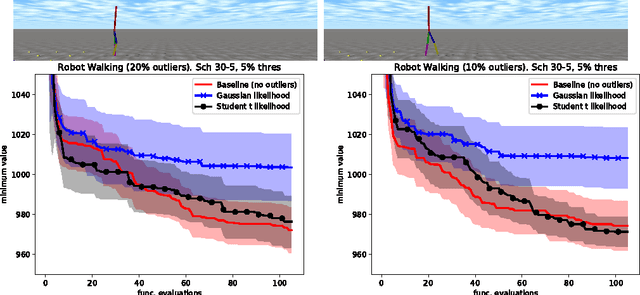
Bayesian optimization has recently attracted the attention of the automatic machine learning community for its excellent results in hyperparameter tuning. BO is characterized by the sample efficiency with which it can optimize expensive black-box functions. The efficiency is achieved in a similar fashion to the learning to learn methods: surrogate models (typically in the form of Gaussian processes) learn the target function and perform intelligent sampling. This surrogate model can be applied even in the presence of noise; however, as with most regression methods, it is very sensitive to outlier data. This can result in erroneous predictions and, in the case of BO, biased and inefficient exploration. In this work, we present a GP model that is robust to outliers which uses a Student-t likelihood to segregate outliers and robustly conduct Bayesian optimization. We present numerical results evaluating the proposed method in both artificial functions and real problems.
Bayesian Optimization for Machine Learning : A Practical Guidebook
Dec 14, 2016


The engineering of machine learning systems is still a nascent field; relying on a seemingly daunting collection of quickly evolving tools and best practices. It is our hope that this guidebook will serve as a useful resource for machine learning practitioners looking to take advantage of Bayesian optimization techniques. We outline four example machine learning problems that can be solved using open source machine learning libraries, and highlight the benefits of using Bayesian optimization in the context of these common machine learning applications.
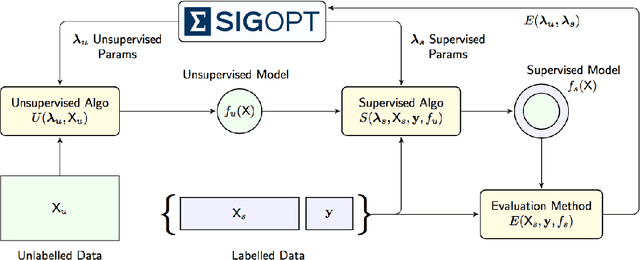
Evaluation System for a Bayesian Optimization Service
May 19, 2016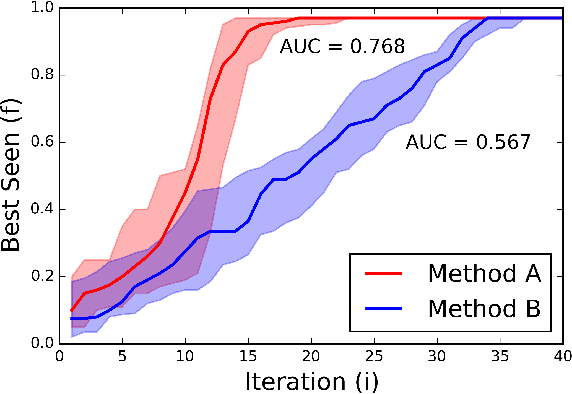
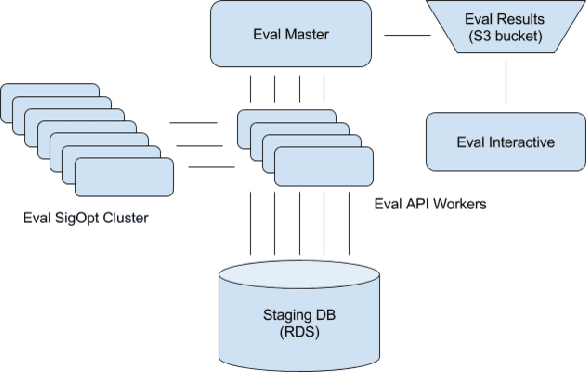
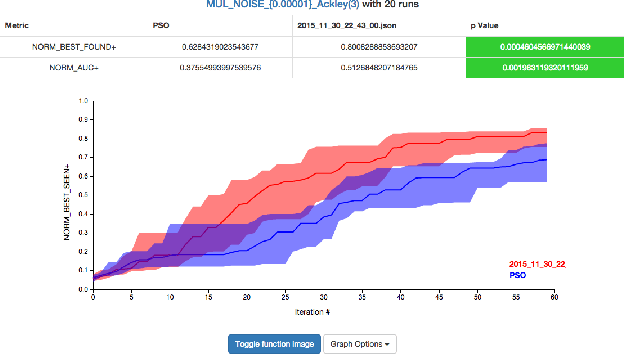
Bayesian optimization is an elegant solution to the hyperparameter optimization problem in machine learning. Building a reliable and robust Bayesian optimization service requires careful testing methodology and sound statistical analysis. In this talk we will outline our development of an evaluation framework to rigorously test and measure the impact of changes to the SigOpt optimization service. We present an overview of our evaluation system and discuss how this framework empowers our research engineers to confidently and quickly make changes to our core optimization engine