 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic Overestimation of Machine Learning Performance in Neuroimaging Studies of Depression
Dec 13, 2019
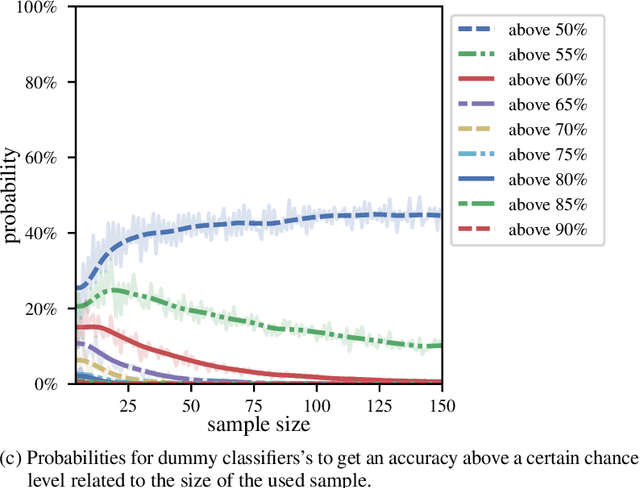
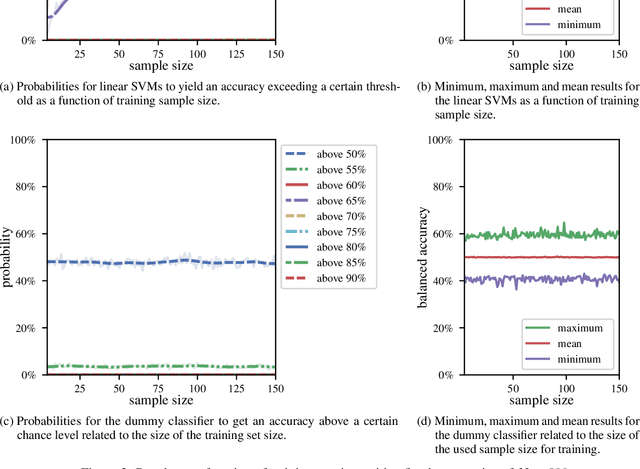
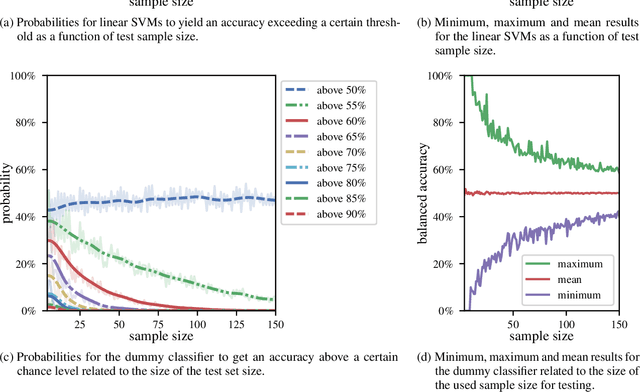
We currently observe a disconcerting phenomenon in machine learning studies in psychiatry: While we would expect larger samples to yield better results due to the availability of more data, larger machine learning studies consistently show much weaker performance than the numerous small-scale studies. Here, we systematically investigated this effect focusing on one of the most heavily studied questions in the field, namely the classification of patients suffering from Major Depressive Disorder (MDD) and healthy controls. Drawing upon a balanced sample of $N = 1,868$ MDD patients and healthy controls from our recent international Predictive Analytics Competition (PAC), we first trained and tested a classification model on the full dataset which yielded an accuracy of 61%. Next, we mimicked the process by which researchers would draw samples of various sizes ($N=4$ to $N=150$) from the population and showed a strong risk of overestimation. Specifically, for small sample sizes ($N=20$), we observe accuracies of up to 95%. For medium sample sizes ($N=100$) accuracies up to 75% were found. Importantly, further investigation showed that sufficiently large test sets effectively protect against performance overestimation whereas larger datasets per se do not. While these results question the validity of a substantial part of the current literature, we outline the relatively low-cost remedy of larger test sets.
Bayesian Optimization for Machine Learning : A Practical Guidebook
Dec 14, 2016


The engineering of machine learning systems is still a nascent field; relying on a seemingly daunting collection of quickly evolving tools and best practices. It is our hope that this guidebook will serve as a useful resource for machine learning practitioners looking to take advantage of Bayesian optimization techniques. We outline four example machine learning problems that can be solved using open source machine learning libraries, and highlight the benefits of using Bayesian optimization in the context of these common machine learning applications.
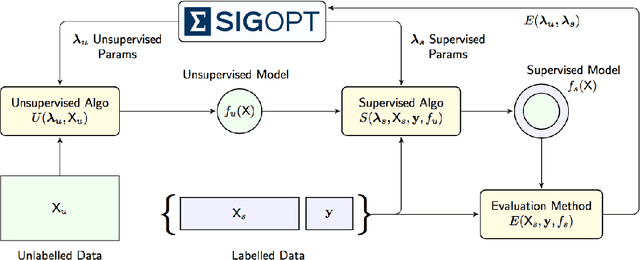
Evaluation System for a Bayesian Optimization Service
May 19, 2016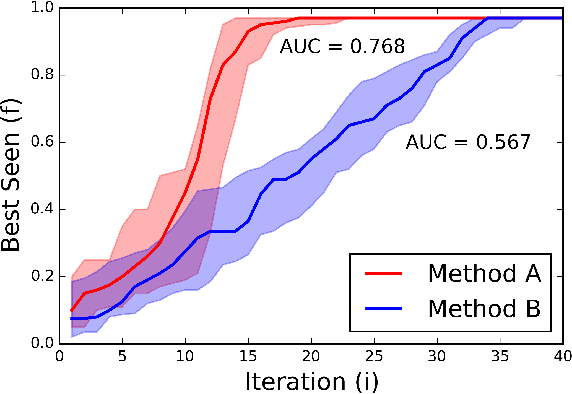
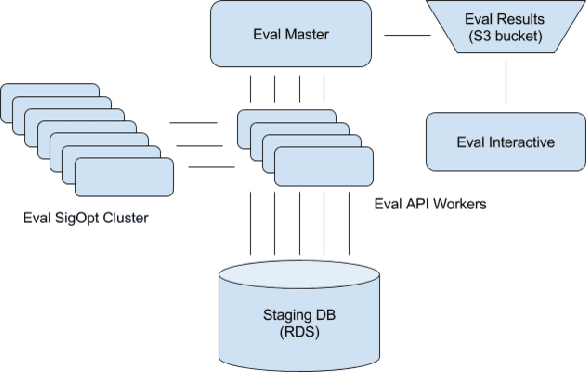
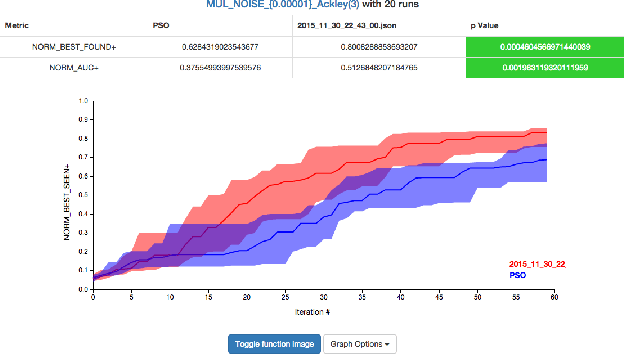
Bayesian optimization is an elegant solution to the hyperparameter optimization problem in machine learning. Building a reliable and robust Bayesian optimization service requires careful testing methodology and sound statistical analysis. In this talk we will outline our development of an evaluation framework to rigorously test and measure the impact of changes to the SigOpt optimization service. We present an overview of our evaluation system and discuss how this framework empowers our research engineers to confidently and quickly make changes to our core optimization engine
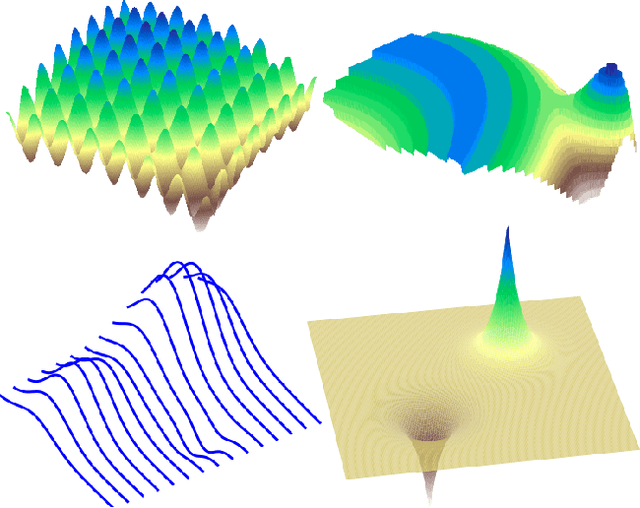
A Stratified Analysis of Bayesian Optimization Methods
Mar 31, 2016


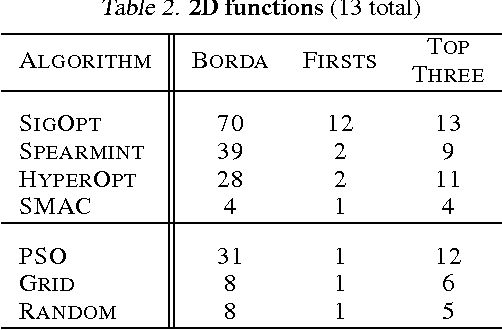
Empirical analysis serves as an important complement to theoretical analysis for studying practical Bayesian optimization. Often empirical insights expose strengths and weaknesses inaccessible to theoretical analysis. We define two metrics for comparing the performance of Bayesian optimization methods and propose a ranking mechanism for summarizing performance within various genres or strata of test functions. These test functions serve to mimic the complexity of hyperparameter optimization problems, the most prominent application of Bayesian optimization, but with a closed form which allows for rapid evaluation and more predictable behavior. This offers a flexible and efficient way to investigate functions with specific properties of interest, such as oscillatory behavior or an optimum on the domain boundary.