 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Execution with Autoregressive Policies
Jun 11, 2026Real-time execution, enabled by asynchronous inference that ensures both smooth action trajectories and fast reactivity, is critical for realistic deployments of large-scale Vision-Language-Action models. However, recent work on real-time execution primarily focuses on variants of diffusion policies, even though it is more critical for autoregressive policies given their slower rollout speed in synchronous inference. In contrast, we demonstrate that autoregressive policies can achieve real-time execution by adjusting the tokenization horizon and applying constrained decoding, thereby guaranteeing strict latency bounds that enable multi-trajectory decoding to maximize performance. Across simulated and real-world environments, we find that the autoregressive policy consistently outperforms its equivalent-level flow-matching policy counterpart while achieving significantly improved task completion speeds from synchronous inference. Coupled with the inherent advantages of autoregressive policies, such as faster convergence and better generalizability in instruction-following, these results confirm that autoregressive policies can remain a competitive policy type supporting real-time execution.
Generative Neural Fields by Mixtures of Neural Implicit Functions
Oct 30, 2023



We propose a novel approach to learning the generative neural fields represented by linear combinations of implicit basis networks. Our algorithm learns basis networks in the form of implicit neural representations and their coefficients in a latent space by either conducting meta-learning or adopting auto-decoding paradigms. The proposed method easily enlarges the capacity of generative neural fields by increasing the number of basis networks while maintaining the size of a network for inference to be small through their weighted model averaging. Consequently, sampling instances using the model is efficient in terms of latency and memory footprint. Moreover, we customize denoising diffusion probabilistic model for a target task to sample latent mixture coefficients, which allows our final model to generate unseen data effectively. Experiments show that our approach achieves competitive generation performance on diverse benchmarks for images, voxel data, and NeRF scenes without sophisticated designs for specific modalities and domains.
Domain-Specific Batch Normalization for Unsupervised Domain Adaptation
May 27, 2019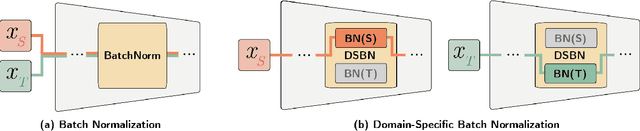
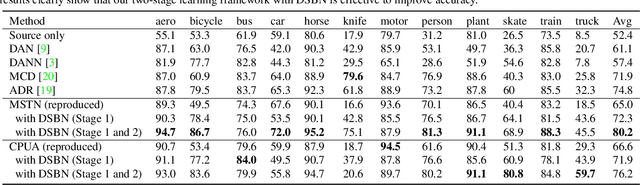
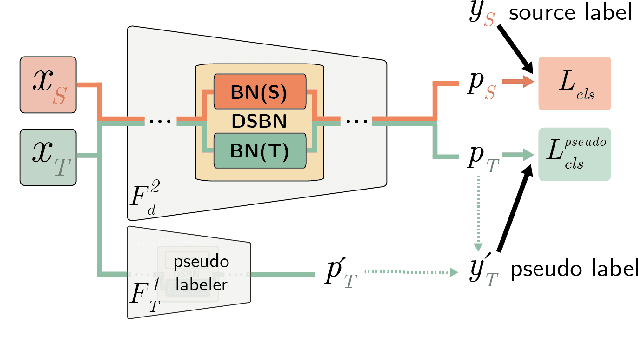
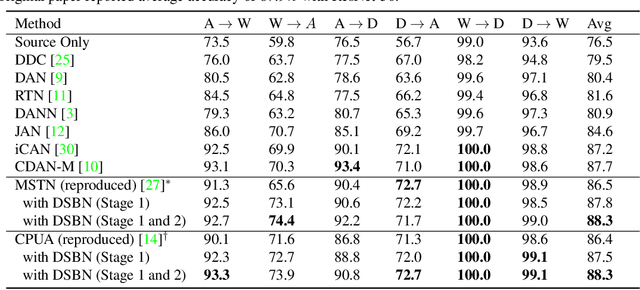
We propose a novel unsupervised domain adaptation framework based on domain-specific batch normalization in deep neural networks. We aim to adapt to both domains by specializing batch normalization layers in convolutional neural networks while allowing them to share all other model parameters, which is realized by a two-stage algorithm. In the first stage, we estimate pseudo-labels for the examples in the target domain using an external unsupervised domain adaptation algorithm---for example, MSTN or CPUA---integrating the proposed domain-specific batch normalization. The second stage learns the final models using a multi-task classification loss for the source and target domains. Note that the two domains have separate batch normalization layers in both stages. Our framework can be easily incorporated into the domain adaptation techniques based on deep neural networks with batch normalization layers. We also present that our approach can be extended to the problem with multiple source domains. The proposed algorithm is evaluated on multiple benchmark datasets and achieves the state-of-the-art accuracy in the standard setting and the multi-source domain adaption scenario.
Bayesian Optimization over Sets
May 23, 2019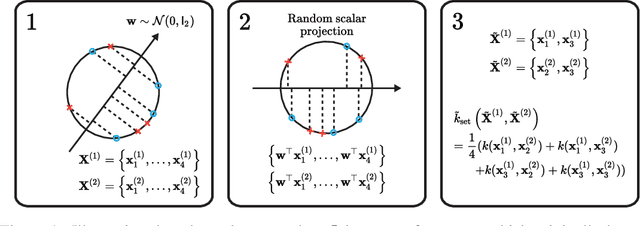
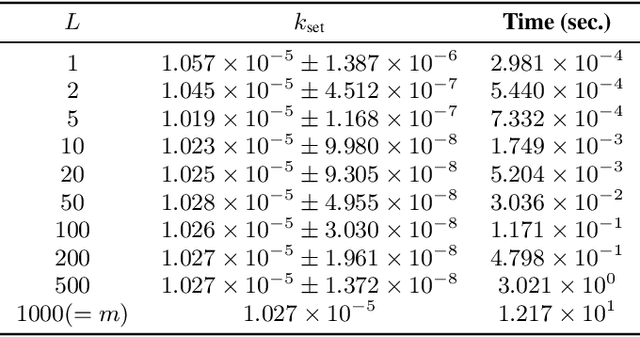
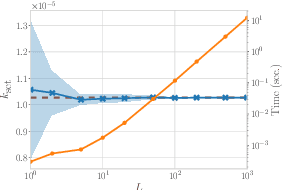
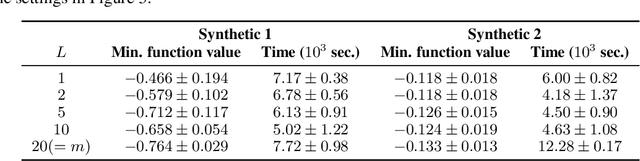
We propose a Bayesian optimization method over sets, to minimize a black-box function that can take a set as single input. Because set inputs are permutation-invariant and variable-length, traditional Gaussian process-based Bayesian optimization strategies which assume vector inputs can fall short. To address this, we develop a Bayesian optimization method with \emph{set kernel} that is used to build surrogate functions. This kernel accumulates similarity over set elements to enforce permutation-invariance and permit sets of variable size, but this comes at a greater computational cost. To reduce this burden, we propose a more efficient probabilistic approximation which we prove is still positive definite and is an unbiased estimator of the true set kernel. Finally, we present several numerical experiments which demonstrate that our method outperforms other methods in various applications.
Regularizing Deep Neural Networks by Noise: Its Interpretation and Optimization
Nov 09, 2017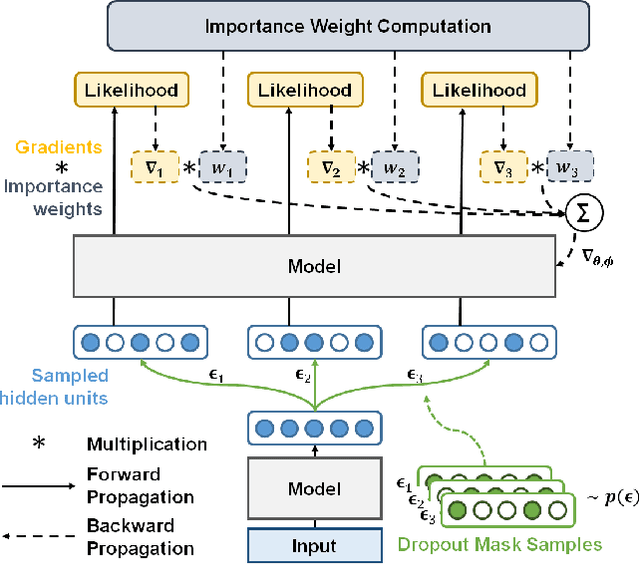

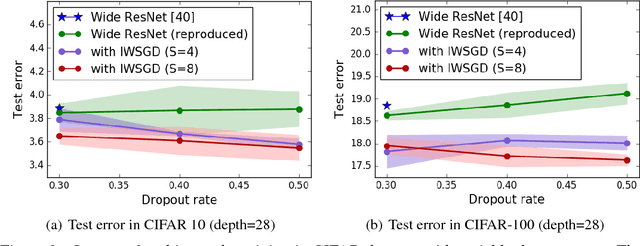

Overfitting is one of the most critical challenges in deep neural networks, and there are various types of regularization methods to improve generalization performance. Injecting noises to hidden units during training, e.g., dropout, is known as a successful regularizer, but it is still not clear enough why such training techniques work well in practice and how we can maximize their benefit in the presence of two conflicting objectives---optimizing to true data distribution and preventing overfitting by regularization. This paper addresses the above issues by 1) interpreting that the conventional training methods with regularization by noise injection optimize the lower bound of the true objective and 2) proposing a technique to achieve a tighter lower bound using multiple noise samples per training example in a stochastic gradient descent iteration. We demonstrate the effectiveness of our idea in several computer vision applications.
Online Tracking by Learning Discriminative Saliency Map with Convolutional Neural Network
Feb 24, 2015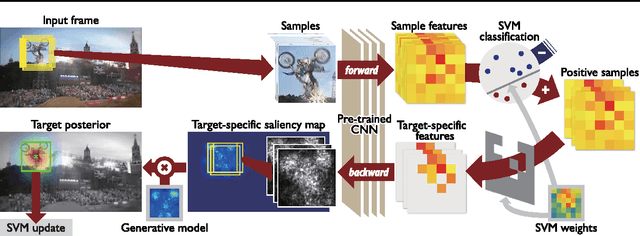
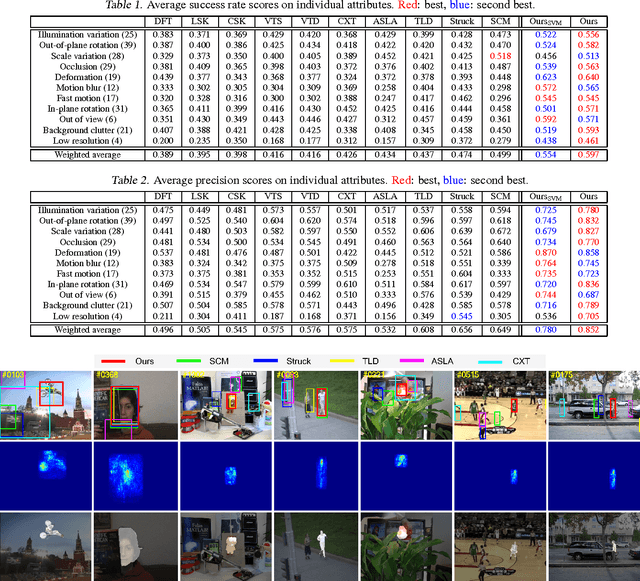

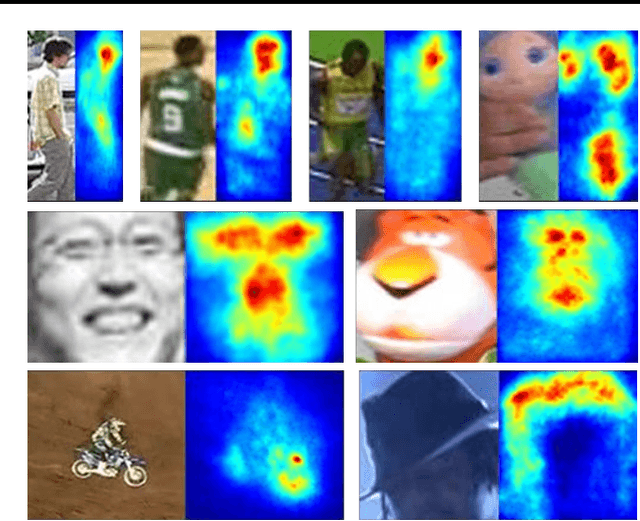
We propose an online visual tracking algorithm by learning discriminative saliency map using Convolutional Neural Network (CNN). Given a CNN pre-trained on a large-scale image repository in offline, our algorithm takes outputs from hidden layers of the network as feature descriptors since they show excellent representation performance in various general visual recognition problems. The features are used to learn discriminative target appearance models using an online Support Vector Machine (SVM). In addition, we construct target-specific saliency map by backpropagating CNN features with guidance of the SVM, and obtain the final tracking result in each frame based on the appearance model generatively constructed with the saliency map. Since the saliency map visualizes spatial configuration of target effectively, it improves target localization accuracy and enable us to achieve pixel-level target segmentation. We verify the effectiveness of our tracking algorithm through extensive experiment on a challenging benchmark, where our method illustrates outstanding performance compared to the state-of-the-art tracking algorithms.