 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGP-4DGS: Probabilistic 4D Gaussian Splatting from Monocular Video via Variational Gaussian Processes
Apr 03, 2026We present GP-4DGS, a novel framework that integrates Gaussian Processes (GPs) into 4D Gaussian Splatting (4DGS) for principled probabilistic modeling of dynamic scenes. While existing 4DGS methods focus on deterministic reconstruction, they are inherently limited in capturing motion ambiguity and lack mechanisms to assess prediction reliability. By leveraging the kernel-based probabilistic nature of GPs, our approach introduces three key capabilities: (i) uncertainty quantification for motion predictions, (ii) motion estimation for unobserved or sparsely sampled regions, and (iii) temporal extrapolation beyond observed training frames. To scale GPs to the large number of Gaussian primitives in 4DGS, we design spatio-temporal kernels that capture the correlation structure of deformation fields and adopt variational Gaussian Processes with inducing points for tractable inference. Our experiments show that GP-4DGS enhances reconstruction quality while providing reliable uncertainty estimates that effectively identify regions of high motion ambiguity. By addressing these challenges, our work takes a meaningful step toward bridging probabilistic modeling and neural graphics.
4D Gaussian Splatting in the Wild with Uncertainty-Aware Regularization
Nov 13, 2024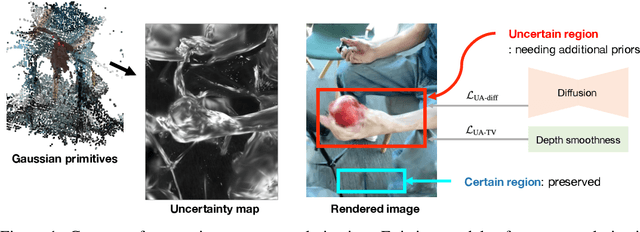
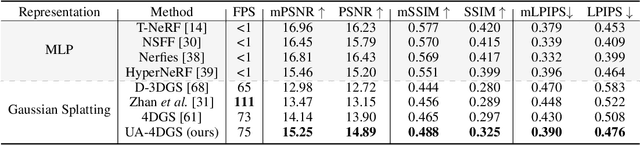
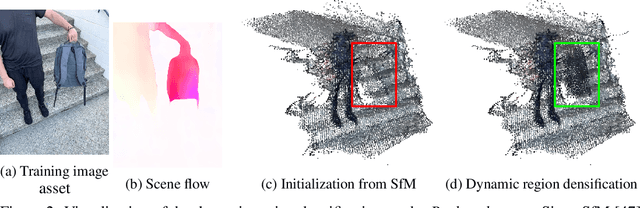
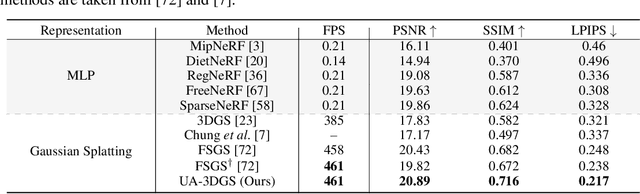
Novel view synthesis of dynamic scenes is becoming important in various applications, including augmented and virtual reality. We propose a novel 4D Gaussian Splatting (4DGS) algorithm for dynamic scenes from casually recorded monocular videos. To overcome the overfitting problem of existing work for these real-world videos, we introduce an uncertainty-aware regularization that identifies uncertain regions with few observations and selectively imposes additional priors based on diffusion models and depth smoothness on such regions. This approach improves both the performance of novel view synthesis and the quality of training image reconstruction. We also identify the initialization problem of 4DGS in fast-moving dynamic regions, where the Structure from Motion (SfM) algorithm fails to provide reliable 3D landmarks. To initialize Gaussian primitives in such regions, we present a dynamic region densification method using the estimated depth maps and scene flow. Our experiments show that the proposed method improves the performance of 4DGS reconstruction from a video captured by a handheld monocular camera and also exhibits promising results in few-shot static scene reconstruction.
Generative Neural Fields by Mixtures of Neural Implicit Functions
Oct 30, 2023



We propose a novel approach to learning the generative neural fields represented by linear combinations of implicit basis networks. Our algorithm learns basis networks in the form of implicit neural representations and their coefficients in a latent space by either conducting meta-learning or adopting auto-decoding paradigms. The proposed method easily enlarges the capacity of generative neural fields by increasing the number of basis networks while maintaining the size of a network for inference to be small through their weighted model averaging. Consequently, sampling instances using the model is efficient in terms of latency and memory footprint. Moreover, we customize denoising diffusion probabilistic model for a target task to sample latent mixture coefficients, which allows our final model to generate unseen data effectively. Experiments show that our approach achieves competitive generation performance on diverse benchmarks for images, voxel data, and NeRF scenes without sophisticated designs for specific modalities and domains.
InfoNeRF: Ray Entropy Minimization for Few-Shot Neural Volume Rendering
Dec 31, 2021



We present an information-theoretic regularization technique for few-shot novel view synthesis based on neural implicit representation. The proposed approach minimizes potential reconstruction inconsistency that happens due to insufficient viewpoints by imposing the entropy constraint of the density in each ray. In addition, to alleviate the potential degenerate issue when all training images are acquired from almost redundant viewpoints, we further incorporate the spatially smoothness constraint into the estimated images by restricting information gains from a pair of rays with slightly different viewpoints. The main idea of our algorithm is to make reconstructed scenes compact along individual rays and consistent across rays in the neighborhood. The proposed regularizers can be plugged into most of existing neural volume rendering techniques based on NeRF in a straightforward way. Despite its simplicity, we achieve consistently improved performance compared to existing neural view synthesis methods by large margins on multiple standard benchmarks. Our project website is available at \url{http://cvlab.snu.ac.kr/research/InfoNeRF}.