 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLC-Flow: Learning Local Continuous Optical Flow and Confidence from events
May 23, 2026Event cameras capture brightness changes asynchronously with microsecond resolution, yet existing optical flow methods fail to fully exploit this temporal continuity. Frame-based approaches impose artificial accumulation latency and suffer from domain overfitting, while model-based local methods operate statelessly, discarding temporal history between predictions and yielding inaccurate flows. We propose \textbf{LC-Flow}, the first temporally continuous, learning-based optical flow estimator that operates purely from local events. At its core, a Continuous Local Recurrent Network maintains persistent hidden states per spatial grid, incrementally accumulating temporal context as events arrive. Unlike frame-based methods constrained to fixed accumulation windows, and unlike stateless model-based methods that recompute motion from scratch at each step, LC-Flow produces sparse local flow estimates at arbitrary timestamps with full motion history. To address the inherent ambiguity of local observations, we jointly learn a confidence score that quantifies the reliability of each prediction, explicitly handling event sparsity and the aperture problem. This confidence serves a dual role: filtering unreliable estimates for downstream tasks such as visual odometry, and providing principled weights for a multi-scale confidence-guided aggregation that reconstructs globally consistent flow from the sparse local outputs. LC-Flow achieves state-of-the-art performance among local methods on both MVSEC and DSEC, while the confidence-guided aggregation establishes a new overall state-of-the-art on the MVSEC benchmark, surpassing heavy frame-based networks that rely on global spatial priors.
Grasp-and-Lift: Executable 3D Hand-Object Interaction Reconstruction via Physics-in-the-Loop Optimization
Jan 26, 2026Dexterous hand manipulation increasingly relies on large-scale motion datasets with precise hand-object trajectory data. However, existing resources such as DexYCB and HO3D are primarily optimized for visual alignment but often yield physically implausible interactions when replayed in physics simulators, including penetration, missed contact, and unstable grasps. We propose a simulation-in-the-loop refinement framework that converts these visually aligned trajectories into physically executable ones. Our core contribution is to formulate this as a tractable black-box optimization problem. We parameterize the hand's motion using a low-dimensional, spline-based representation built on sparse temporal keyframes. This allows us to use a powerful gradient-free optimizer, CMA-ES, to treat the high-fidelity physics engine as a black-box objective function. Our method finds motions that simultaneously maximize physical success (e.g., stable grasp and lift) while minimizing deviation from the original human demonstration. Compared to MANIPTRANS-recent transfer pipelines, our approach achieves lower hand and object pose errors during replay and more accurately recovers hand-object physical interactions. Our approach provides a general and scalable method for converting visual demonstrations into physically valid trajectories, enabling the generation of high-fidelity data crucial for robust policy learning.
PanoGrounder: Bridging 2D and 3D with Panoramic Scene Representations for VLM-based 3D Visual Grounding
Dec 24, 20253D Visual Grounding (3DVG) is a critical bridge from vision-language perception to robotics, requiring both language understanding and 3D scene reasoning. Traditional supervised models leverage explicit 3D geometry but exhibit limited generalization, owing to the scarcity of 3D vision-language datasets and the limited reasoning capabilities compared to modern vision-language models (VLMs). We propose PanoGrounder, a generalizable 3DVG framework that couples multi-modal panoramic representation with pretrained 2D VLMs for strong vision-language reasoning. Panoramic renderings, augmented with 3D semantic and geometric features, serve as an intermediate representation between 2D and 3D, and offer two major benefits: (i) they can be directly fed to VLMs with minimal adaptation and (ii) they retain long-range object-to-object relations thanks to their 360-degree field of view. We devise a three-stage pipeline that places a compact set of panoramic viewpoints considering the scene layout and geometry, grounds a text query on each panoramic rendering with a VLM, and fuses per-view predictions into a single 3D bounding box via lifting. Our approach achieves state-of-the-art results on ScanRefer and Nr3D, and demonstrates superior generalization to unseen 3D datasets and text rephrasings.
SMF-VO: Direct Ego-Motion Estimation via Sparse Motion Fields
Nov 12, 2025Traditional Visual Odometry (VO) and Visual Inertial Odometry (VIO) methods rely on a 'pose-centric' paradigm, which computes absolute camera poses from the local map thus requires large-scale landmark maintenance and continuous map optimization. This approach is computationally expensive, limiting their real-time performance on resource-constrained devices. To overcome these limitations, we introduce Sparse Motion Field Visual Odometry (SMF-VO), a lightweight, 'motion-centric' framework. Our approach directly estimates instantaneous linear and angular velocity from sparse optical flow, bypassing the need for explicit pose estimation or expensive landmark tracking. We also employed a generalized 3D ray-based motion field formulation that works accurately with various camera models, including wide-field-of-view lenses. SMF-VO demonstrates superior efficiency and competitive accuracy on benchmark datasets, achieving over 100 FPS on a Raspberry Pi 5 using only a CPU. Our work establishes a scalable and efficient alternative to conventional methods, making it highly suitable for mobile robotics and wearable devices.
SC-Lane: Slope-aware and Consistent Road Height Estimation Framework for 3D Lane Detection
Aug 14, 2025In this paper, we introduce SC-Lane, a novel slope-aware and temporally consistent heightmap estimation framework for 3D lane detection. Unlike previous approaches that rely on fixed slope anchors, SC-Lane adaptively determines the fusion of slope-specific height features, improving robustness to diverse road geometries. To achieve this, we propose a Slope-Aware Adaptive Feature module that dynamically predicts the appropriate weights from image cues for integrating multi-slope representations into a unified heightmap. Additionally, a Height Consistency Module enforces temporal coherence, ensuring stable and accurate height estimation across consecutive frames, which is crucial for real-world driving scenarios. To evaluate the effectiveness of SC-Lane, we employ three standardized metrics-Mean Absolute Error(MAE), Root Mean Squared Error (RMSE), and threshold-based accuracy-which, although common in surface and depth estimation, have been underutilized for road height assessment. Using the LiDAR-derived heightmap dataset introduced in prior work [20], we benchmark our method under these metrics, thereby establishing a rigorous standard for future comparisons. Extensive experiments on the OpenLane benchmark demonstrate that SC-Lane significantly improves both height estimation and 3D lane detection, achieving state-of-the-art performance with an F-score of 64.3%, outperforming existing methods by a notable margin. For detailed results and a demonstration video, please refer to our project page:https://parkchaesong.github.io/sclane/
4D Gaussian Splatting in the Wild with Uncertainty-Aware Regularization
Nov 13, 2024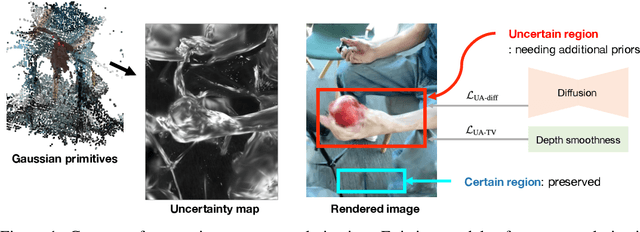
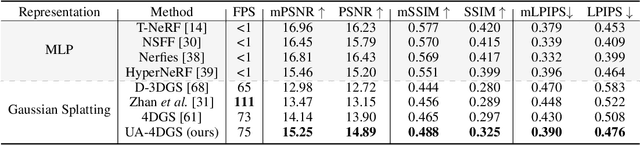
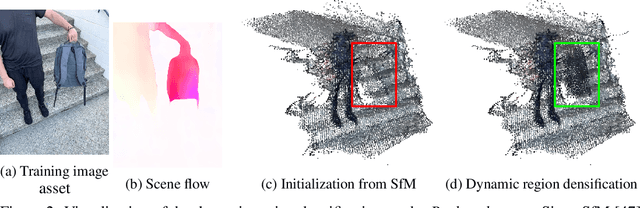
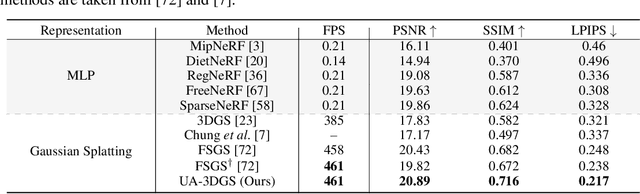
Novel view synthesis of dynamic scenes is becoming important in various applications, including augmented and virtual reality. We propose a novel 4D Gaussian Splatting (4DGS) algorithm for dynamic scenes from casually recorded monocular videos. To overcome the overfitting problem of existing work for these real-world videos, we introduce an uncertainty-aware regularization that identifies uncertain regions with few observations and selectively imposes additional priors based on diffusion models and depth smoothness on such regions. This approach improves both the performance of novel view synthesis and the quality of training image reconstruction. We also identify the initialization problem of 4DGS in fast-moving dynamic regions, where the Structure from Motion (SfM) algorithm fails to provide reliable 3D landmarks. To initialize Gaussian primitives in such regions, we present a dynamic region densification method using the estimated depth maps and scene flow. Our experiments show that the proposed method improves the performance of 4DGS reconstruction from a video captured by a handheld monocular camera and also exhibits promising results in few-shot static scene reconstruction.
HeightLane: BEV Heightmap guided 3D Lane Detection
Aug 15, 2024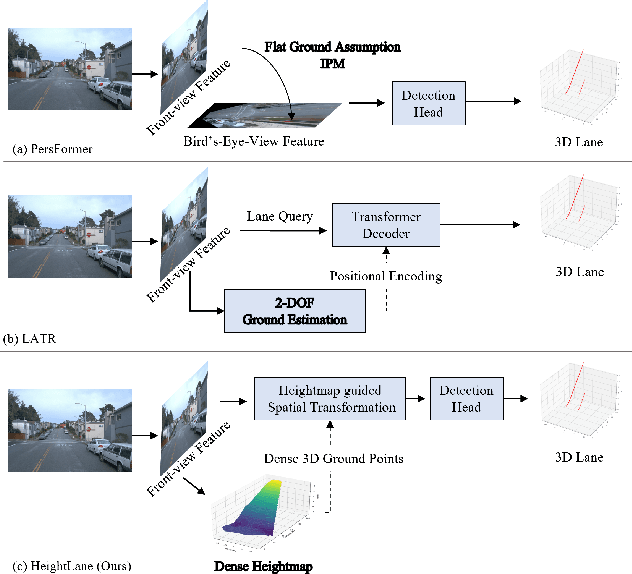
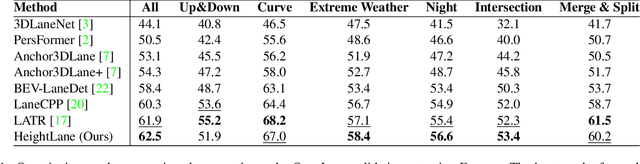
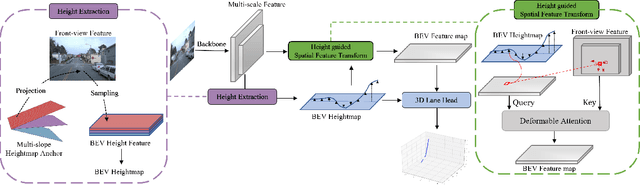
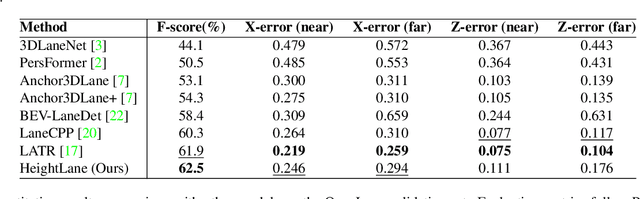
Accurate 3D lane detection from monocular images presents significant challenges due to depth ambiguity and imperfect ground modeling. Previous attempts to model the ground have often used a planar ground assumption with limited degrees of freedom, making them unsuitable for complex road environments with varying slopes. Our study introduces HeightLane, an innovative method that predicts a height map from monocular images by creating anchors based on a multi-slope assumption. This approach provides a detailed and accurate representation of the ground. HeightLane employs the predicted heightmap along with a deformable attention-based spatial feature transform framework to efficiently convert 2D image features into 3D bird's eye view (BEV) features, enhancing spatial understanding and lane structure recognition. Additionally, the heightmap is used for the positional encoding of BEV features, further improving their spatial accuracy. This explicit view transformation bridges the gap between front-view perceptions and spatially accurate BEV representations, significantly improving detection performance. To address the lack of the necessary ground truth (GT) height map in the original OpenLane dataset, we leverage the Waymo dataset and accumulate its LiDAR data to generate a height map for the drivable area of each scene. The GT heightmaps are used to train the heightmap extraction module from monocular images. Extensive experiments on the OpenLane validation set show that HeightLane achieves state-of-the-art performance in terms of F-score, highlighting its potential in real-world applications.
Integrating Meshes and 3D Gaussians for Indoor Scene Reconstruction with SAM Mask Guidance
Jul 23, 2024We present a novel approach for 3D indoor scene reconstruction that combines 3D Gaussian Splatting (3DGS) with mesh representations. We use meshes for the room layout of the indoor scene, such as walls, ceilings, and floors, while employing 3D Gaussians for other objects. This hybrid approach leverages the strengths of both representations, offering enhanced flexibility and ease of editing. However, joint training of meshes and 3D Gaussians is challenging because it is not clear which primitive should affect which part of the rendered image. Objects close to the room layout often struggle during training, particularly when the room layout is textureless, which can lead to incorrect optimizations and unnecessary 3D Gaussians. To overcome these challenges, we employ Segment Anything Model (SAM) to guide the selection of primitives. The SAM mask loss enforces each instance to be represented by either Gaussians or meshes, ensuring clear separation and stable training. Furthermore, we introduce an additional densification stage without resetting the opacity after the standard densification. This stage mitigates the degradation of image quality caused by a limited number of 3D Gaussians after the standard densification.
Unbiased Estimator for Distorted Conics in Camera Calibration
Mar 10, 2024In the literature, points and conics have been major features for camera geometric calibration. Although conics are more informative features than points, the loss of the conic property under distortion has critically limited the utility of conic features in camera calibration. Many existing approaches addressed conic-based calibration by ignoring distortion or introducing 3D spherical targets to circumvent this limitation. In this paper, we present a novel formulation for conic-based calibration using moments. Our derivation is based on the mathematical finding that the first moment can be estimated without bias even under distortion. This allows us to track moment changes during projection and distortion, ensuring the preservation of the first moment of the distorted conic. With an unbiased estimator, the circular patterns can be accurately detected at the sub-pixel level and can now be fully exploited for an entire calibration pipeline, resulting in significantly improved calibration. The entire code is readily available from https://github.com/ChaehyeonSong/discocal.
TSDF-Sampling: Efficient Sampling for Neural Surface Field using Truncated Signed Distance Field
Nov 29, 2023Multi-view neural surface reconstruction has exhibited impressive results. However, a notable limitation is the prohibitively slow inference time when compared to traditional techniques, primarily attributed to the dense sampling, required to maintain the rendering quality. This paper introduces a novel approach that substantially reduces the number of samplings by incorporating the Truncated Signed Distance Field (TSDF) of the scene. While prior works have proposed importance sampling, their dependence on initial uniform samples over the entire space makes them unable to avoid performance degradation when trying to use less number of samples. In contrast, our method leverages the TSDF volume generated only by the trained views, and it proves to provide a reasonable bound on the sampling from upcoming novel views. As a result, we achieve high rendering quality by fully exploiting the continuous neural SDF estimation within the bounds given by the TSDF volume. Notably, our method is the first approach that can be robustly plug-and-play into a diverse array of neural surface field models, as long as they use the volume rendering technique. Our empirical results show an 11-fold increase in inference speed without compromising performance. The result videos are available at our project page: https://tsdf-sampling.github.io/