 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Multi-Head Self-Attention with Linear Complexity
Feb 27, 2024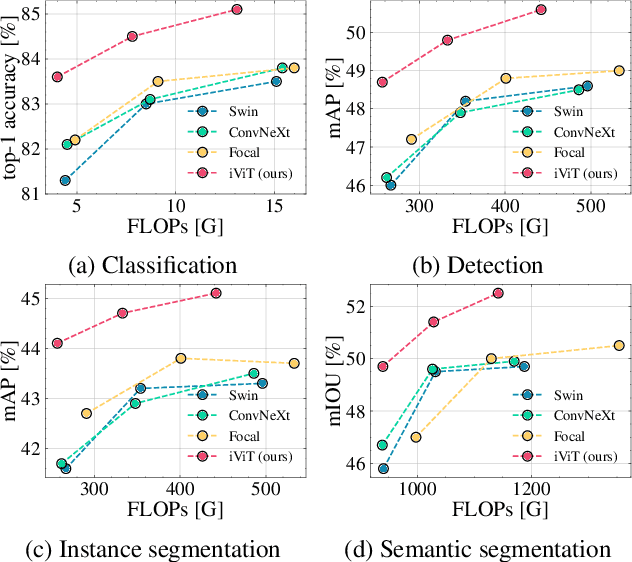

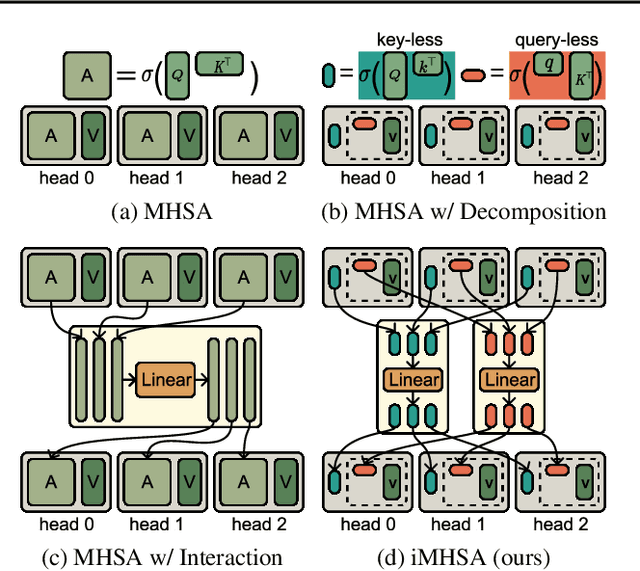
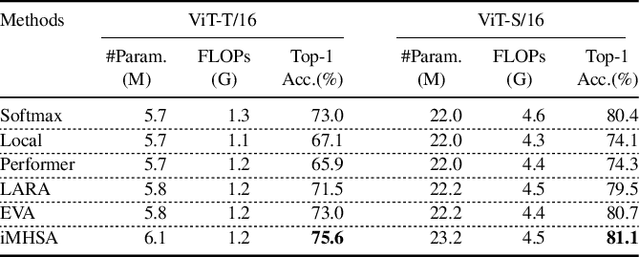
We propose an efficient interactive method for multi-head self-attention via decomposition. For existing methods using multi-head self-attention, the attention operation of each head is computed independently. However, we show that the interactions between cross-heads of the attention matrix enhance the information flow of the attention operation. Considering that the attention matrix of each head can be seen as a feature of networks, it is beneficial to establish connectivity between them to capture interactions better. However, a straightforward approach to capture the interactions between the cross-heads is computationally prohibitive as the complexity grows substantially with the high dimension of an attention matrix. In this work, we propose an effective method to decompose the attention operation into query- and key-less components. This will result in a more manageable size for the attention matrix, specifically for the cross-head interactions. Expensive experimental results show that the proposed cross-head interaction approach performs favorably against existing efficient attention methods and state-of-the-art backbone models.
Gramian Attention Heads are Strong yet Efficient Vision Learners
Oct 25, 2023We introduce a novel architecture design that enhances expressiveness by incorporating multiple head classifiers (\ie, classification heads) instead of relying on channel expansion or additional building blocks. Our approach employs attention-based aggregation, utilizing pairwise feature similarity to enhance multiple lightweight heads with minimal resource overhead. We compute the Gramian matrices to reinforce class tokens in an attention layer for each head. This enables the heads to learn more discriminative representations, enhancing their aggregation capabilities. Furthermore, we propose a learning algorithm that encourages heads to complement each other by reducing correlation for aggregation. Our models eventually surpass state-of-the-art CNNs and ViTs regarding the accuracy-throughput trade-off on ImageNet-1K and deliver remarkable performance across various downstream tasks, such as COCO object instance segmentation, ADE20k semantic segmentation, and fine-grained visual classification datasets. The effectiveness of our framework is substantiated by practical experimental results and further underpinned by generalization error bound. We release the code publicly at: https://github.com/Lab-LVM/imagenet-models.
Towards long-tailed, multi-label disease classification from chest X-ray: Overview of the CXR-LT challenge
Oct 24, 2023



Many real-world image recognition problems, such as diagnostic medical imaging exams, are "long-tailed" $\unicode{x2013}$ there are a few common findings followed by many more relatively rare conditions. In chest radiography, diagnosis is both a long-tailed and multi-label problem, as patients often present with multiple findings simultaneously. While researchers have begun to study the problem of long-tailed learning in medical image recognition, few have studied the interaction of label imbalance and label co-occurrence posed by long-tailed, multi-label disease classification. To engage with the research community on this emerging topic, we conducted an open challenge, CXR-LT, on long-tailed, multi-label thorax disease classification from chest X-rays (CXRs). We publicly release a large-scale benchmark dataset of over 350,000 CXRs, each labeled with at least one of 26 clinical findings following a long-tailed distribution. We synthesize common themes of top-performing solutions, providing practical recommendations for long-tailed, multi-label medical image classification. Finally, we use these insights to propose a path forward involving vision-language foundation models for few- and zero-shot disease classification.
Fine-Grained Self-Supervised Learning with Jigsaw Puzzles for Medical Image Classification
Aug 10, 2023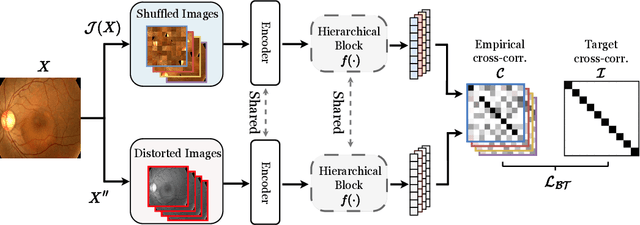
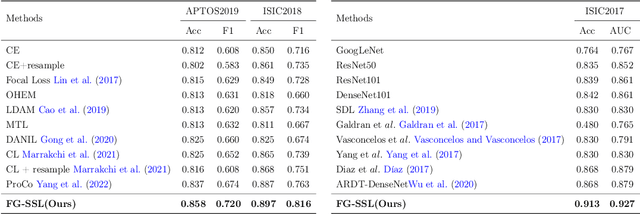
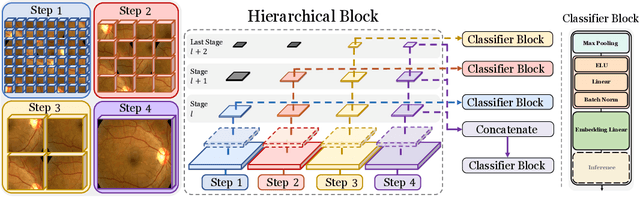
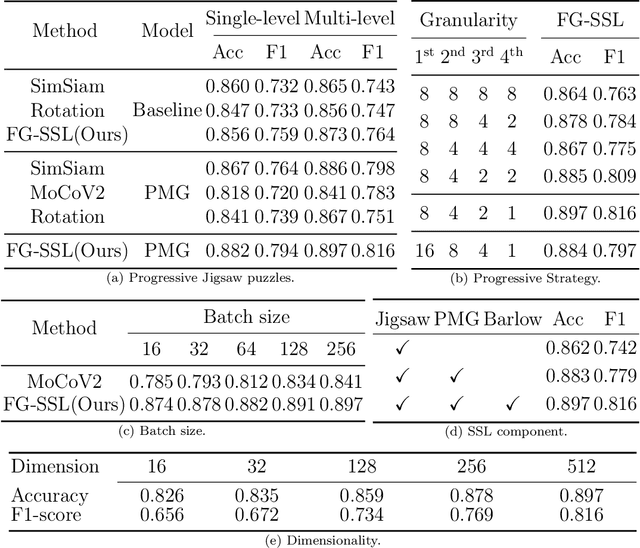
Classifying fine-grained lesions is challenging due to minor and subtle differences in medical images. This is because learning features of fine-grained lesions with highly minor differences is very difficult in training deep neural networks. Therefore, in this paper, we introduce Fine-Grained Self-Supervised Learning(FG-SSL) method for classifying subtle lesions in medical images. The proposed method progressively learns the model through hierarchical block such that the cross-correlation between the fine-grained Jigsaw puzzle and regularized original images is close to the identity matrix. We also apply hierarchical block for progressive fine-grained learning, which extracts different information in each step, to supervised learning for discovering subtle differences. Our method does not require an asymmetric model, nor does a negative sampling strategy, and is not sensitive to batch size. We evaluate the proposed fine-grained self-supervised learning method on comprehensive experiments using various medical image recognition datasets. In our experiments, the proposed method performs favorably compared to existing state-of-the-art approaches on the widely-used ISIC2018, APTOS2019, and ISIC2017 datasets.
Robust Asymmetric Loss for Multi-Label Long-Tailed Learning
Aug 10, 2023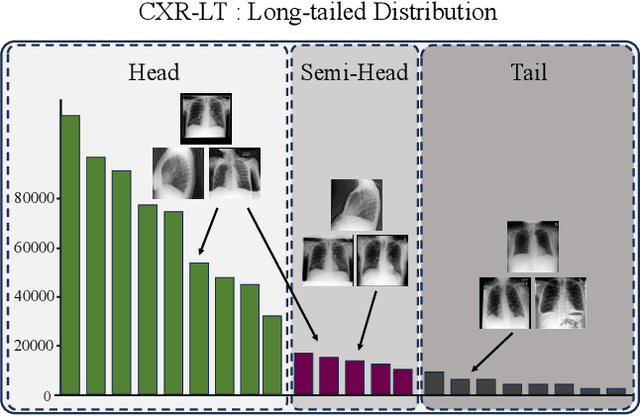
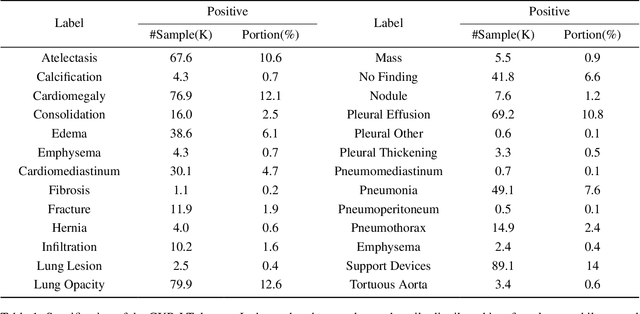
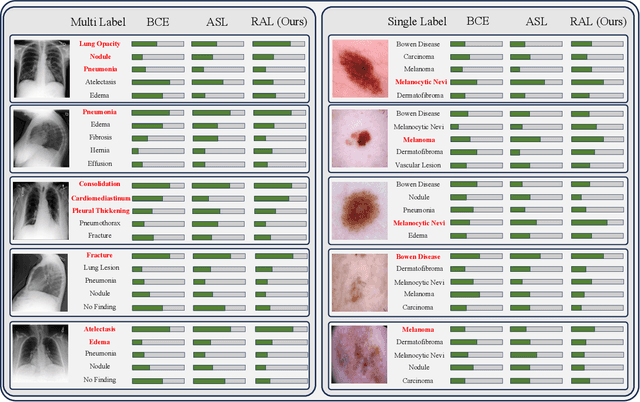
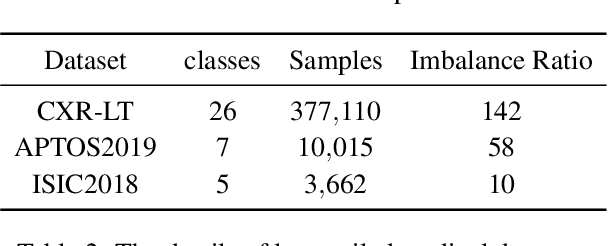
In real medical data, training samples typically show long-tailed distributions with multiple labels. Class distribution of the medical data has a long-tailed shape, in which the incidence of different diseases is quite varied, and at the same time, it is not unusual for images taken from symptomatic patients to be multi-label diseases. Therefore, in this paper, we concurrently address these two issues by putting forth a robust asymmetric loss on the polynomial function. Since our loss tackles both long-tailed and multi-label classification problems simultaneously, it leads to a complex design of the loss function with a large number of hyper-parameters. Although a model can be highly fine-tuned due to a large number of hyper-parameters, it is difficult to optimize all hyper-parameters at the same time, and there might be a risk of overfitting a model. Therefore, we regularize the loss function using the Hill loss approach, which is beneficial to be less sensitive against the numerous hyper-parameters so that it reduces the risk of overfitting the model. For this reason, the proposed loss is a generic method that can be applied to most medical image classification tasks and does not make the training process more time-consuming. We demonstrate that the proposed robust asymmetric loss performs favorably against the long-tailed with multi-label medical image classification in addition to the various long-tailed single-label datasets. Notably, our method achieves Top-5 results on the CXR-LT dataset of the ICCV CVAMD 2023 competition. We opensource our implementation of the robust asymmetric loss in the public repository: https://github.com/kalelpark/RAL.
Spatial Bias for Attention-free Non-local Neural Networks
Feb 24, 2023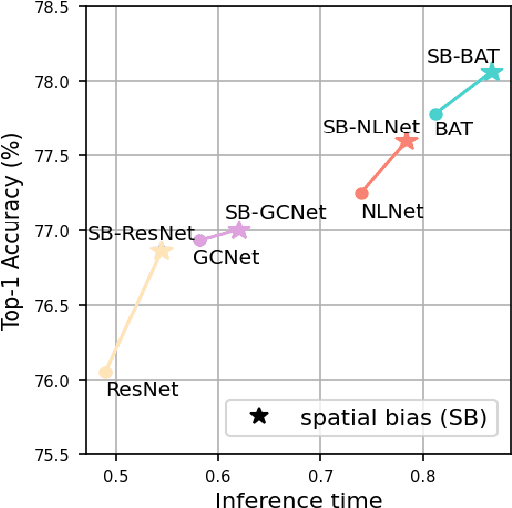
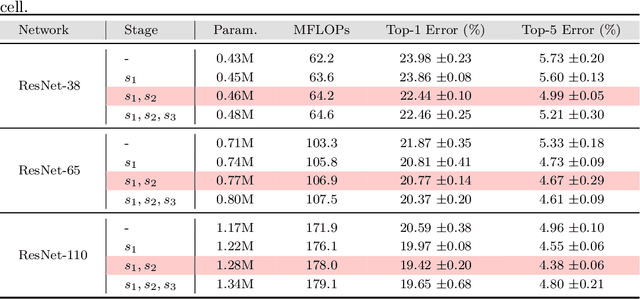
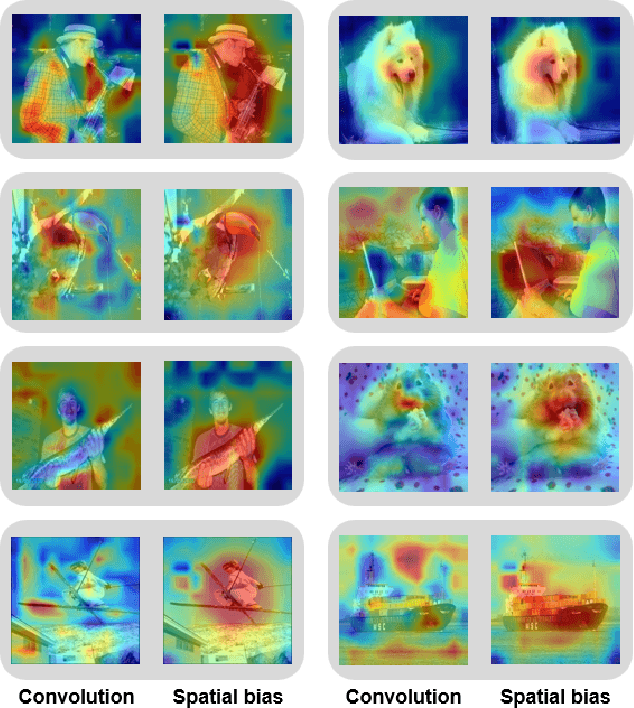
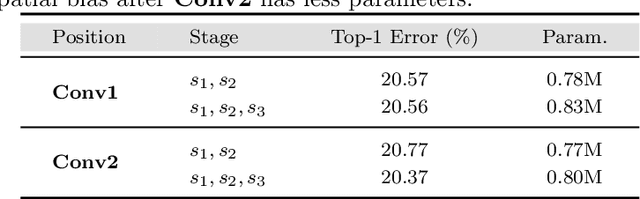
In this paper, we introduce the spatial bias to learn global knowledge without self-attention in convolutional neural networks. Owing to the limited receptive field, conventional convolutional neural networks suffer from learning long-range dependencies. Non-local neural networks have struggled to learn global knowledge, but unavoidably have too heavy a network design due to the self-attention operation. Therefore, we propose a fast and lightweight spatial bias that efficiently encodes global knowledge without self-attention on convolutional neural networks. Spatial bias is stacked on the feature map and convolved together to adjust the spatial structure of the convolutional features. Therefore, we learn the global knowledge on the convolution layer directly with very few additional resources. Our method is very fast and lightweight due to the attention-free non-local method while improving the performance of neural networks considerably. Compared to non-local neural networks, the spatial bias use about 10 times fewer parameters while achieving comparable performance with 1.6 ~ 3.3 times more throughput on a very little budget. Furthermore, the spatial bias can be used with conventional non-local neural networks to further improve the performance of the backbone model. We show that the spatial bias achieves competitive performance that improves the classification accuracy by +0.79% and +1.5% on ImageNet-1K and cifar100 datasets. Additionally, we validate our method on the MS-COCO and ADE20K datasets for downstream tasks involving object detection and semantic segmentation.
Collaborative Training of Balanced Random Forests for Open Set Domain Adaptation
Feb 10, 2020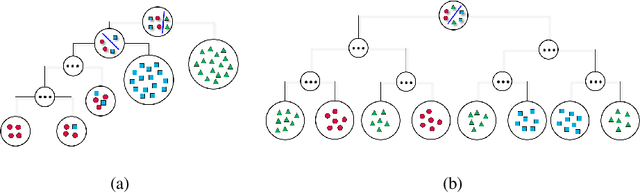

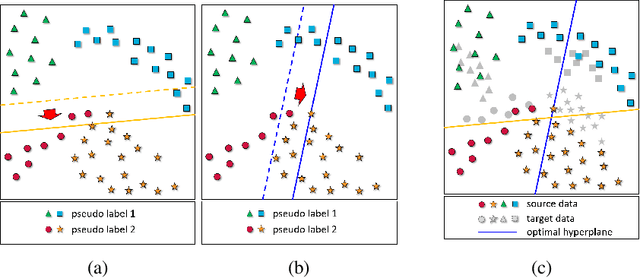

In this paper, we introduce a collaborative training algorithm of balanced random forests with convolutional neural networks for domain adaptation tasks. In real scenarios, most domain adaptation algorithms face the challenges from noisy, insufficient training data and open set categorization. In such cases, conventional methods suffer from overfitting and fail to successfully transfer the knowledge of the source to the target domain. To address these issues, the following two techniques are proposed. First, we introduce the optimized decision tree construction method with convolutional neural networks, in which the data at each node are split into equal sizes while maximizing the information gain. It generates balanced decision trees on deep features because of the even-split constraint, which contributes to enhanced discrimination power and reduced overfitting problem. Second, to tackle the domain misalignment problem, we propose the domain alignment loss which penalizes uneven splits of the source and target domain data. By collaboratively optimizing the information gain of the labeled source data as well as the entropy of unlabeled target data distributions, the proposed CoBRF algorithm achieves significantly better performance than the state-of-the-art methods.
OmniMVS: End-to-End Learning for Omnidirectional Stereo Matching
Aug 17, 2019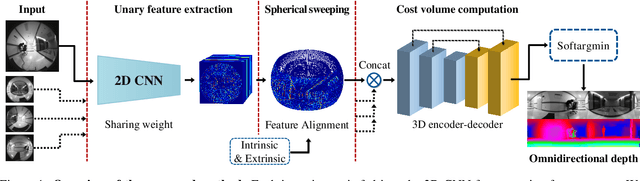
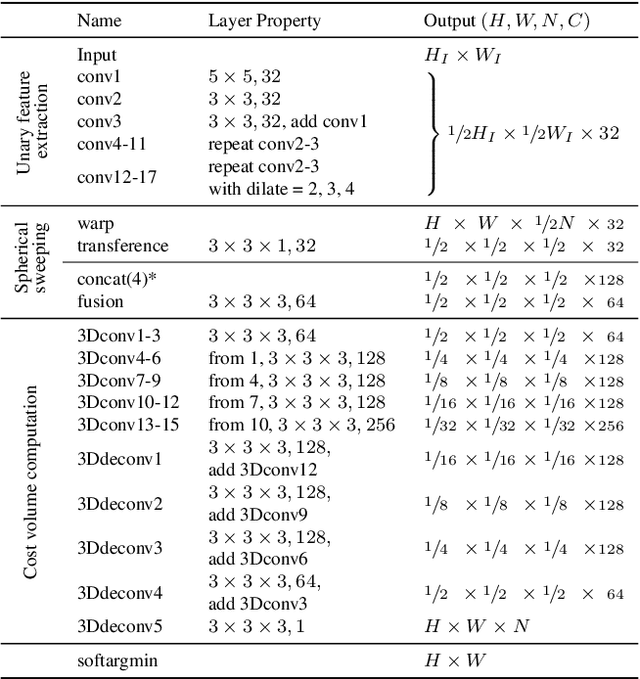

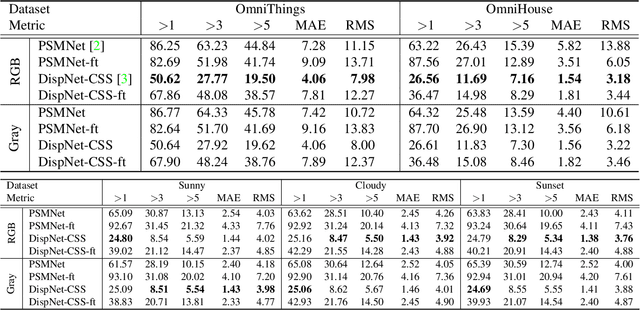
In this paper, we propose a novel end-to-end deep neural network model for omnidirectional depth estimation from a wide-baseline multi-view stereo setup. The images captured with ultra wide field-of-view (FOV) cameras on an omnidirectional rig are processed by the feature extraction module, and then the deep feature maps are warped onto the concentric spheres swept through all candidate depths using the calibrated camera parameters. The 3D encoder-decoder block takes the aligned feature volume to produce the omnidirectional depth estimate with regularization on uncertain regions utilizing the global context information. In addition, we present large-scale synthetic datasets for training and testing omnidirectional multi-view stereo algorithms. Our datasets consist of 11K ground-truth depth maps and 45K fisheye images in four orthogonal directions with various objects and environments. Experimental results show that the proposed method generates excellent results in both synthetic and real-world environments, and it outperforms the prior art and the omnidirectional versions of the state-of-the-art conventional stereo algorithms.
SweepNet: Wide-baseline Omnidirectional Depth Estimation
Feb 28, 2019
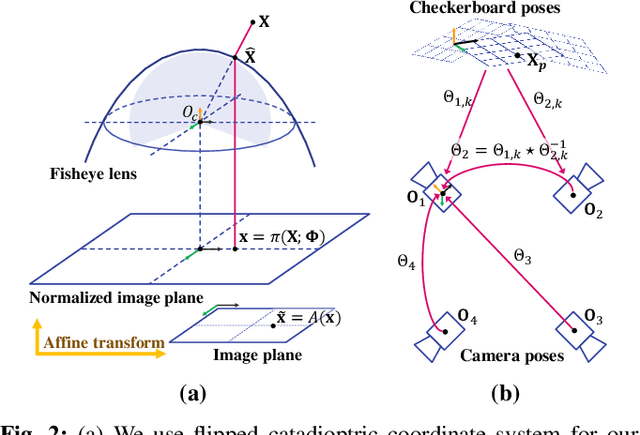
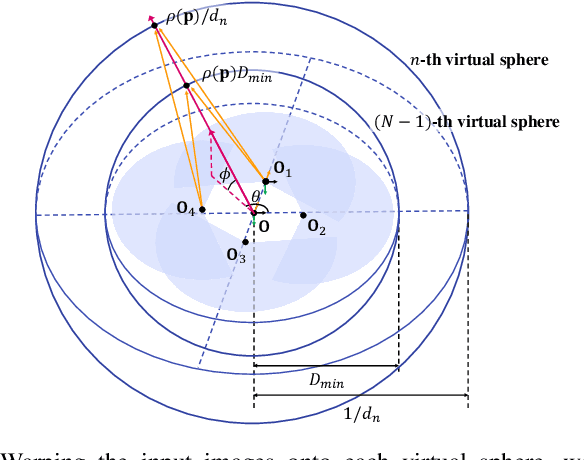
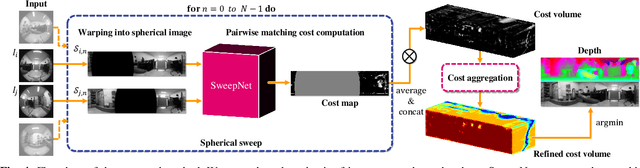
Omnidirectional depth sensing has its advantage over the conventional stereo systems since it enables us to recognize the objects of interest in all directions without any blind regions. In this paper, we propose a novel wide-baseline omnidirectional stereo algorithm which computes the dense depth estimate from the fisheye images using a deep convolutional neural network. The capture system consists of multiple cameras mounted on a wide-baseline rig with ultrawide field of view (FOV) lenses, and we present the calibration algorithm for the extrinsic parameters based on the bundle adjustment. Instead of estimating depth maps from multiple sets of rectified images and stitching them, our approach directly generates one dense omnidirectional depth map with full 360-degree coverage at the rig global coordinate system. To this end, the proposed neural network is designed to output the cost volume from the warped images in the sphere sweeping method, and the final depth map is estimated by taking the minimum cost indices of the aggregated cost volume by SGM. For training the deep neural network and testing the entire system, realistic synthetic urban datasets are rendered using Blender. The experiments using the synthetic and real-world datasets show that our algorithm outperforms the conventional depth estimation methods and generate highly accurate depth maps.
SSPP-DAN: Deep Domain Adaptation Network for Face Recognition with Single Sample Per Person
Apr 28, 2018
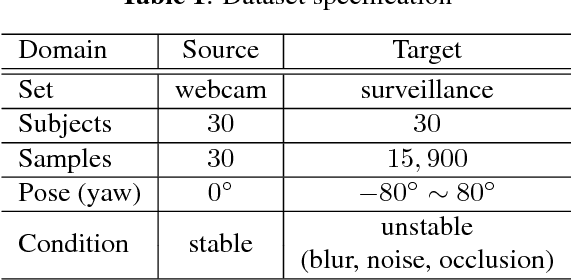
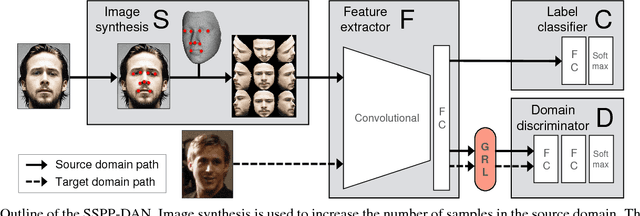
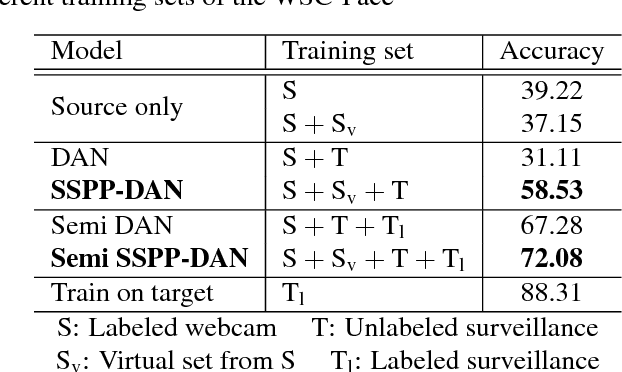
Real-world face recognition using a single sample per person (SSPP) is a challenging task. The problem is exacerbated if the conditions under which the gallery image and the probe set are captured are completely different. To address these issues from the perspective of domain adaptation, we introduce an SSPP domain adaptation network (SSPP-DAN). In the proposed approach, domain adaptation, feature extraction, and classification are performed jointly using a deep architecture with domain-adversarial training. However, the SSPP characteristic of one training sample per class is insufficient to train the deep architecture. To overcome this shortage, we generate synthetic images with varying poses using a 3D face model. Experimental evaluations using a realistic SSPP dataset show that deep domain adaptation and image synthesis complement each other and dramatically improve accuracy. Experiments on a benchmark dataset using the proposed approach show state-of-the-art performance. All the dataset and the source code can be found in our online repository (https://github.com/csehong/SSPP-DAN).