 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-Aware Test-Time Segmentation for Continual Domain Shifts
Dec 09, 2025Continual Test-Time Adaptation (CTTA) enables pre-trained models to adapt to continuously evolving domains. Existing methods have improved robustness but typically rely on fixed or batch-level thresholds, which cannot account for varying difficulty across classes and instances. This limitation is especially problematic in semantic segmentation, where each image requires dense, multi-class predictions. We propose an approach that adaptively adjusts pseudo labels to reflect the confidence distribution within each image and dynamically balances learning toward classes most affected by domain shifts. This fine-grained, class- and instance-aware adaptation produces more reliable supervision and mitigates error accumulation throughout continual adaptation. Extensive experiments across eight CTTA and TTA scenarios, including synthetic-to-real and long-term shifts, show that our method consistently outperforms state-of-the-art techniques, setting a new standard for semantic segmentation under evolving conditions.
PRIMT: Preference-based Reinforcement Learning with Multimodal Feedback and Trajectory Synthesis from Foundation Models
Sep 19, 2025Preference-based reinforcement learning (PbRL) has emerged as a promising paradigm for teaching robots complex behaviors without reward engineering. However, its effectiveness is often limited by two critical challenges: the reliance on extensive human input and the inherent difficulties in resolving query ambiguity and credit assignment during reward learning. In this paper, we introduce PRIMT, a PbRL framework designed to overcome these challenges by leveraging foundation models (FMs) for multimodal synthetic feedback and trajectory synthesis. Unlike prior approaches that rely on single-modality FM evaluations, PRIMT employs a hierarchical neuro-symbolic fusion strategy, integrating the complementary strengths of large language models and vision-language models in evaluating robot behaviors for more reliable and comprehensive feedback. PRIMT also incorporates foresight trajectory generation, which reduces early-stage query ambiguity by warm-starting the trajectory buffer with bootstrapped samples, and hindsight trajectory augmentation, which enables counterfactual reasoning with a causal auxiliary loss to improve credit assignment. We evaluate PRIMT on 2 locomotion and 6 manipulation tasks on various benchmarks, demonstrating superior performance over FM-based and scripted baselines.
Dynamic Rank Adjustment for Accurate and Efficient Neural Network Training
Aug 13, 2025Low-rank training methods reduce the number of trainable parameters by re-parameterizing the weights with matrix decompositions (e.g., singular value decomposition). However, enforcing a fixed low-rank structure caps the rank of the weight matrices and can hinder the model's ability to learn complex patterns. Furthermore, the effective rank of the model's weights tends to decline during training, and this drop is accelerated when the model is reparameterized into a low-rank structure. In this study, we argue that strategically interleaving full-rank training epochs within low-rank training epochs can effectively restore the rank of the model's weights. Based on our findings, we propose a general dynamic-rank training framework that is readily applicable to a wide range of neural-network tasks. We first describe how to adjust the rank of weight matrix to alleviate the inevitable rank collapse that arises during training, and then present extensive empirical results that validate our claims and demonstrate the efficacy of the proposed framework. Our empirical study shows that the proposed method achieves almost the same computational cost as SVD-based low-rank training while achieving a comparable accuracy to full-rank training across various benchmarks.
RA-Touch: Retrieval-Augmented Touch Understanding with Enriched Visual Data
May 20, 2025Visuo-tactile perception aims to understand an object's tactile properties, such as texture, softness, and rigidity. However, the field remains underexplored because collecting tactile data is costly and labor-intensive. We observe that visually distinct objects can exhibit similar surface textures or material properties. For example, a leather sofa and a leather jacket have different appearances but share similar tactile properties. This implies that tactile understanding can be guided by material cues in visual data, even without direct tactile supervision. In this paper, we introduce RA-Touch, a retrieval-augmented framework that improves visuo-tactile perception by leveraging visual data enriched with tactile semantics. We carefully recaption a large-scale visual dataset with tactile-focused descriptions, enabling the model to access tactile semantics typically absent from conventional visual datasets. A key challenge remains in effectively utilizing these tactile-aware external descriptions. RA-Touch addresses this by retrieving visual-textual representations aligned with tactile inputs and integrating them to focus on relevant textural and material properties. By outperforming prior methods on the TVL benchmark, our method demonstrates the potential of retrieval-based visual reuse for tactile understanding. Code is available at https://aim-skku.github.io/RA-Touch
Grasping Deformable Objects via Reinforcement Learning with Cross-Modal Attention to Visuo-Tactile Inputs
Apr 22, 2025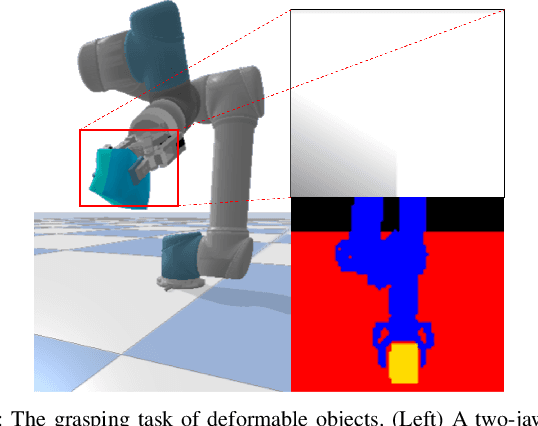
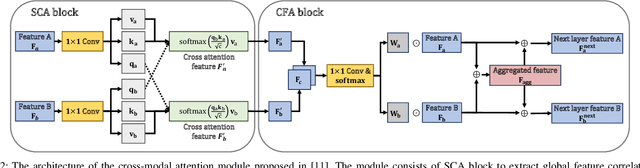
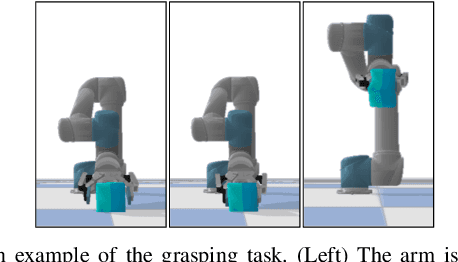
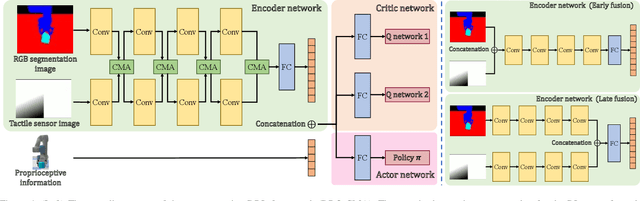
We consider the problem of grasping deformable objects with soft shells using a robotic gripper. Such objects have a center-of-mass that changes dynamically and are fragile so prone to burst. Thus, it is difficult for robots to generate appropriate control inputs not to drop or break the object while performing manipulation tasks. Multi-modal sensing data could help understand the grasping state through global information (e.g., shapes, pose) from visual data and local information around the contact (e.g., pressure) from tactile data. Although they have complementary information that can be beneficial to use together, fusing them is difficult owing to their different properties. We propose a method based on deep reinforcement learning (DRL) that generates control inputs of a simple gripper from visuo-tactile sensing information. Our method employs a cross-modal attention module in the encoder network and trains it in a self-supervised manner using the loss function of the RL agent. With the multi-modal fusion, the proposed method can learn the representation for the DRL agent from the visuo-tactile sensory data. The experimental result shows that cross-modal attention is effective to outperform other early and late data fusion methods across different environments including unseen robot motions and objects.
Task Vector Quantization for Memory-Efficient Model Merging
Mar 10, 2025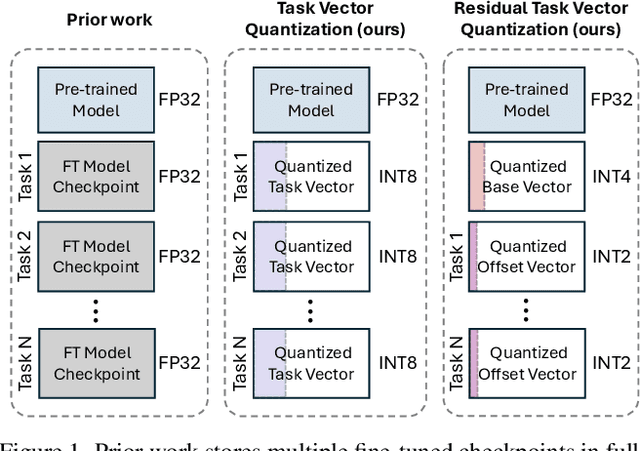
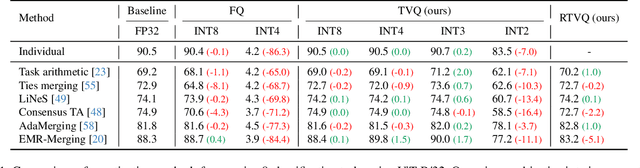
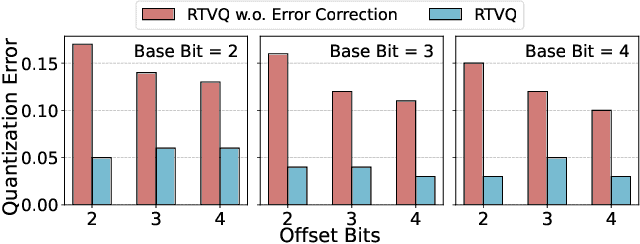
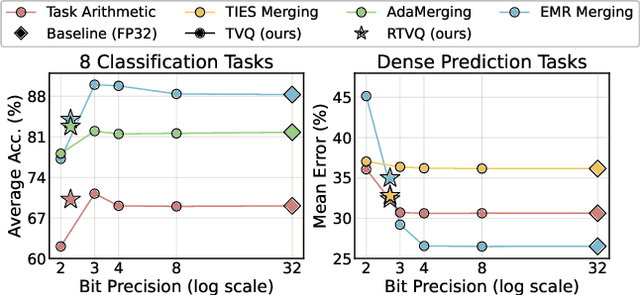
Model merging enables efficient multi-task models by combining task-specific fine-tuned checkpoints. However, storing multiple task-specific checkpoints requires significant memory, limiting scalability and restricting model merging to larger models and diverse tasks. In this paper, we propose quantizing task vectors (i.e., the difference between pre-trained and fine-tuned checkpoints) instead of quantizing fine-tuned checkpoints. We observe that task vectors exhibit a narrow weight range, enabling low precision quantization (up to 4 bit) within existing task vector merging frameworks. To further mitigate quantization errors within ultra-low bit precision (e.g., 2 bit), we introduce Residual Task Vector Quantization, which decomposes the task vector into a base vector and offset component. We allocate bits based on quantization sensitivity, ensuring precision while minimizing error within a memory budget. Experiments on image classification and dense prediction show our method maintains or improves model merging performance while using only 8% of the memory required for full-precision checkpoints.
Question-Aware Gaussian Experts for Audio-Visual Question Answering
Mar 07, 2025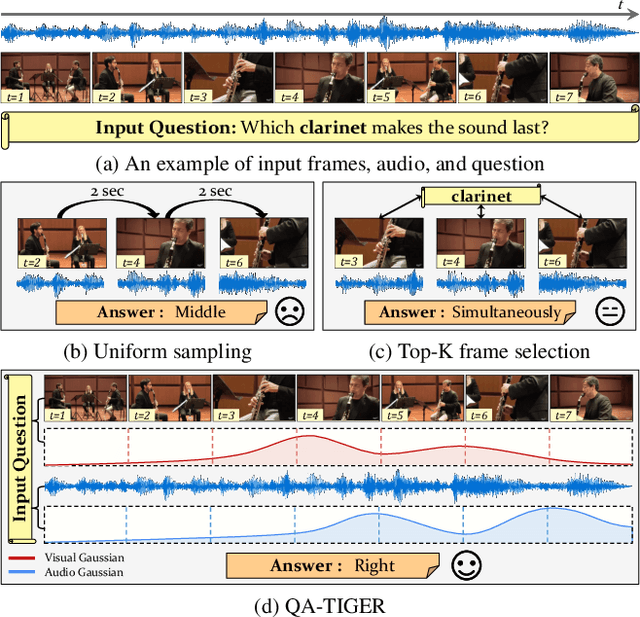

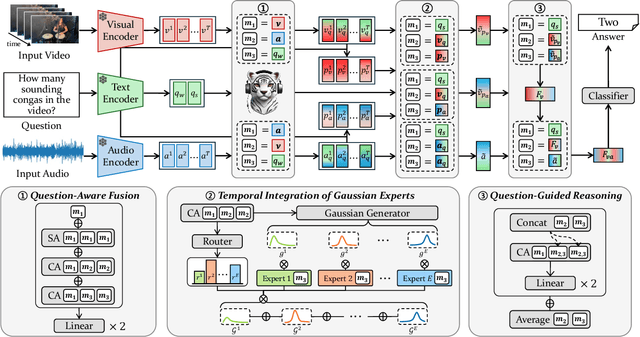
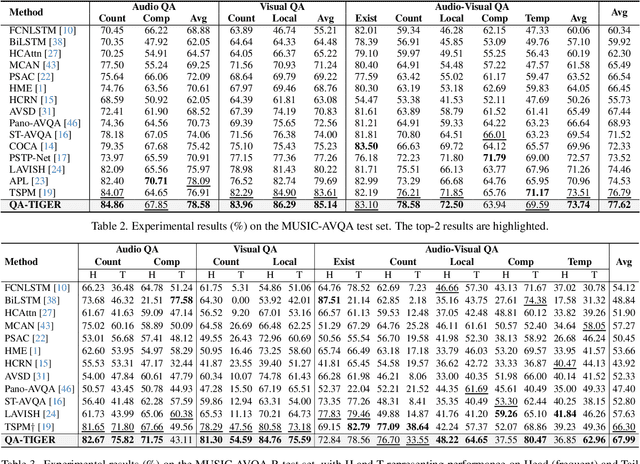
Audio-Visual Question Answering (AVQA) requires not only question-based multimodal reasoning but also precise temporal grounding to capture subtle dynamics for accurate prediction. However, existing methods mainly use question information implicitly, limiting focus on question-specific details. Furthermore, most studies rely on uniform frame sampling, which can miss key question-relevant frames. Although recent Top-K frame selection methods aim to address this, their discrete nature still overlooks fine-grained temporal details. This paper proposes QA-TIGER, a novel framework that explicitly incorporates question information and models continuous temporal dynamics. Our key idea is to use Gaussian-based modeling to adaptively focus on both consecutive and non-consecutive frames based on the question, while explicitly injecting question information and applying progressive refinement. We leverage a Mixture of Experts (MoE) to flexibly implement multiple Gaussian models, activating temporal experts specifically tailored to the question. Extensive experiments on multiple AVQA benchmarks show that QA-TIGER consistently achieves state-of-the-art performance. Code is available at https://aim-skku.github.io/QA-TIGER/
IAM: Enhancing RGB-D Instance Segmentation with New Benchmarks
Jan 03, 2025



Image segmentation is a vital task for providing human assistance and enhancing autonomy in our daily lives. In particular, RGB-D segmentation-leveraging both visual and depth cues-has attracted increasing attention as it promises richer scene understanding than RGB-only methods. However, most existing efforts have primarily focused on semantic segmentation and thus leave a critical gap. There is a relative scarcity of instance-level RGB-D segmentation datasets, which restricts current methods to broad category distinctions rather than fully capturing the fine-grained details required for recognizing individual objects. To bridge this gap, we introduce three RGB-D instance segmentation benchmarks, distinguished at the instance level. These datasets are versatile, supporting a wide range of applications from indoor navigation to robotic manipulation. In addition, we present an extensive evaluation of various baseline models on these benchmarks. This comprehensive analysis identifies both their strengths and shortcomings, guiding future work toward more robust, generalizable solutions. Finally, we propose a simple yet effective method for RGB-D data integration. Extensive evaluations affirm the effectiveness of our approach, offering a robust framework for advancing toward more nuanced scene understanding.
Tint Your Models Task-wise for Improved Multi-task Model Merging
Dec 26, 2024



Traditional model merging methods for multi-task learning (MTL) address task conflicts with straightforward strategies such as weight averaging, sign consensus, or minimal test-time adjustments. This presumably counts on the assumption that a merged encoder still retains abundant task knowledge from individual encoders, implying that its shared representation is sufficiently general across tasks. However, our insight is that adding just a single trainable task-specific layer further can bring striking performance gains, as demonstrated by our pilot study. Motivated by this finding, we propose Model Tinting, a new test-time approach that introduces a single task-specific layer for each task as trainable adjustments. Our method jointly trains merging coefficients and task-specific layers, which effectively reduces task conflicts with minimal additional costs. Additionally, we propose a sampling method that utilizes the difference in confidence levels of both merged and individual encoders. Extensive experiments demonstrate our method's effectiveness, which achieves state-of-the-art performance across both computer vision and natural language processing tasks and significantly surpasses prior works. Our code is available at https://github.com/AIM-SKKU/ModelTinting.
DisCoRD: Discrete Tokens to Continuous Motion via Rectified Flow Decoding
Dec 02, 2024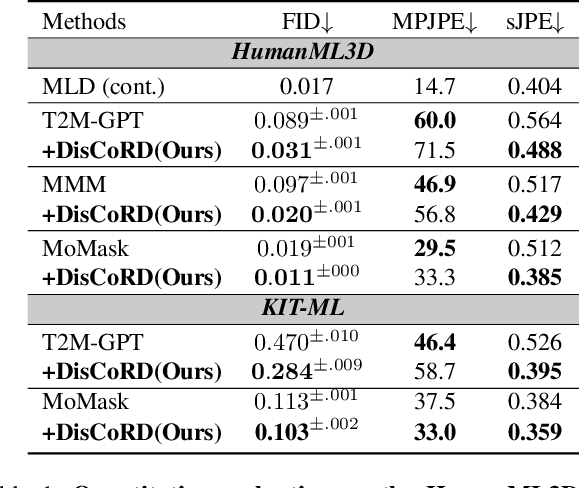
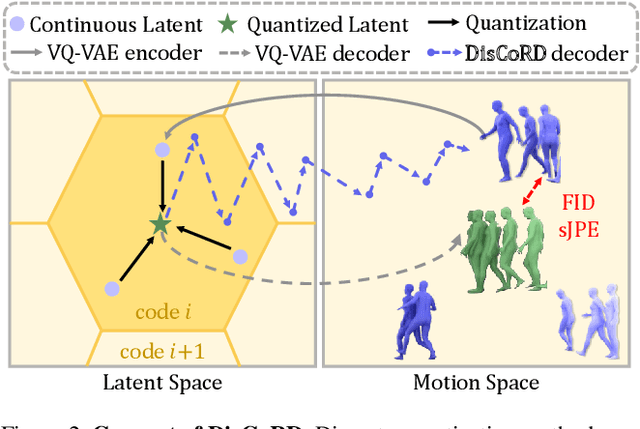
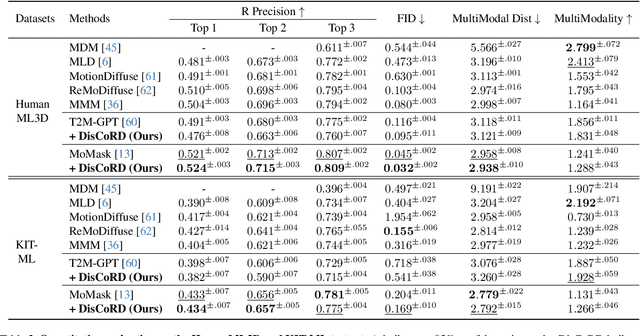
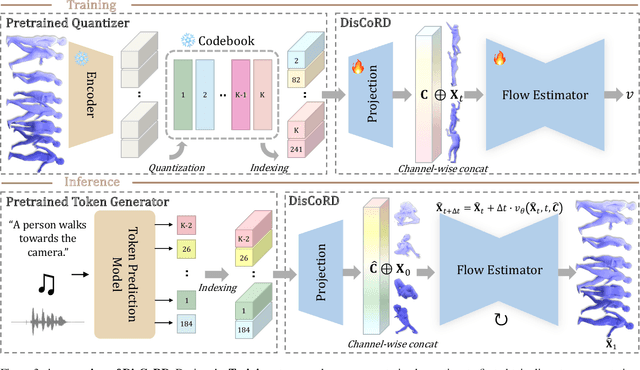
Human motion, inherently continuous and dynamic, presents significant challenges for generative models. Despite their dominance, discrete quantization methods, such as VQ-VAEs, suffer from inherent limitations, including restricted expressiveness and frame-wise noise artifacts. Continuous approaches, while producing smoother and more natural motions, often falter due to high-dimensional complexity and limited training data. To resolve this "discord" between discrete and continuous representations, we introduce DisCoRD: Discrete Tokens to Continuous Motion via Rectified Flow Decoding, a novel method that decodes discrete motion tokens into continuous motion through rectified flow. By employing an iterative refinement process in the continuous space, DisCoRD captures fine-grained dynamics and ensures smoother and more natural motions. Compatible with any discrete-based framework, our method enhances naturalness without compromising faithfulness to the conditioning signals. Extensive evaluations demonstrate that DisCoRD achieves state-of-the-art performance, with FID of 0.032 on HumanML3D and 0.169 on KIT-ML. These results solidify DisCoRD as a robust solution for bridging the divide between discrete efficiency and continuous realism. Our project page is available at: https://whwjdqls.github.io/discord.github.io/.