 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultihopSpatial: Multi-hop Compositional Spatial Reasoning Benchmark for Vision-Language Model
Mar 19, 2026Spatial reasoning is foundational for Vision-Language Models (VLMs), particularly when deployed as Vision-Language-Action (VLA) agents in physical environments. However, existing benchmarks predominantly focus on elementary, single-hop relations, neglecting the multi-hop compositional reasoning and precise visual grounding essential for real-world scenarios. To address this, we introduce MultihopSpatial, offering three key contributions: (1) A comprehensive benchmark designed for multi-hop and compositional spatial reasoning, featuring 1- to 3-hop complex queries across diverse spatial perspectives. (2) Acc@50IoU, a complementary metric that simultaneously evaluates reasoning and visual grounding by requiring both answer selection and precise bounding box prediction - capabilities vital for robust VLA deployment. (3) MultihopSpatial-Train, a dedicated large-scale training corpus to foster spatial intelligence. Extensive evaluation of 37 state-of-the-art VLMs yields eight key insights, revealing that compositional spatial reasoning remains a formidable challenge. Finally, we demonstrate that reinforcement learning post-training on our corpus enhances both intrinsic VLM spatial reasoning and downstream embodied manipulation performance.
Instance-Aware Test-Time Segmentation for Continual Domain Shifts
Dec 09, 2025Continual Test-Time Adaptation (CTTA) enables pre-trained models to adapt to continuously evolving domains. Existing methods have improved robustness but typically rely on fixed or batch-level thresholds, which cannot account for varying difficulty across classes and instances. This limitation is especially problematic in semantic segmentation, where each image requires dense, multi-class predictions. We propose an approach that adaptively adjusts pseudo labels to reflect the confidence distribution within each image and dynamically balances learning toward classes most affected by domain shifts. This fine-grained, class- and instance-aware adaptation produces more reliable supervision and mitigates error accumulation throughout continual adaptation. Extensive experiments across eight CTTA and TTA scenarios, including synthetic-to-real and long-term shifts, show that our method consistently outperforms state-of-the-art techniques, setting a new standard for semantic segmentation under evolving conditions.
Task Vector Quantization for Memory-Efficient Model Merging
Mar 10, 2025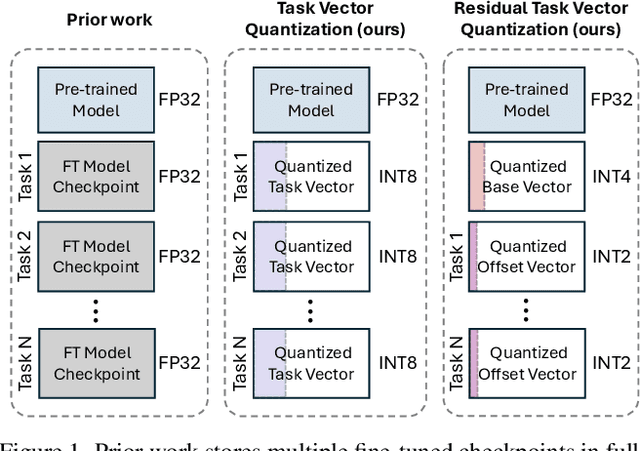
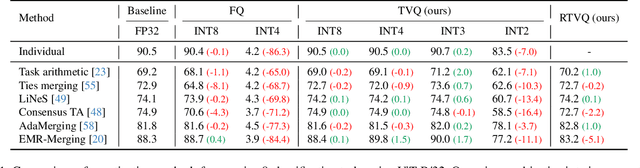
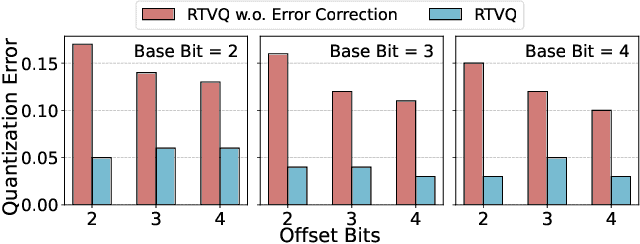
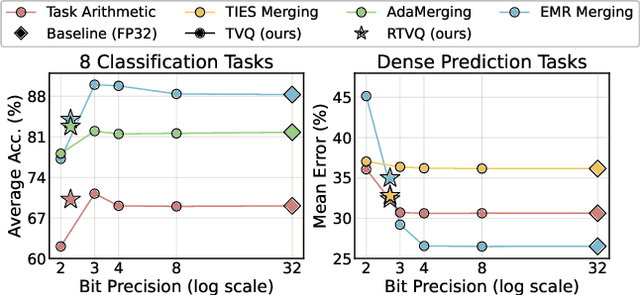
Model merging enables efficient multi-task models by combining task-specific fine-tuned checkpoints. However, storing multiple task-specific checkpoints requires significant memory, limiting scalability and restricting model merging to larger models and diverse tasks. In this paper, we propose quantizing task vectors (i.e., the difference between pre-trained and fine-tuned checkpoints) instead of quantizing fine-tuned checkpoints. We observe that task vectors exhibit a narrow weight range, enabling low precision quantization (up to 4 bit) within existing task vector merging frameworks. To further mitigate quantization errors within ultra-low bit precision (e.g., 2 bit), we introduce Residual Task Vector Quantization, which decomposes the task vector into a base vector and offset component. We allocate bits based on quantization sensitivity, ensuring precision while minimizing error within a memory budget. Experiments on image classification and dense prediction show our method maintains or improves model merging performance while using only 8% of the memory required for full-precision checkpoints.
Tint Your Models Task-wise for Improved Multi-task Model Merging
Dec 26, 2024



Traditional model merging methods for multi-task learning (MTL) address task conflicts with straightforward strategies such as weight averaging, sign consensus, or minimal test-time adjustments. This presumably counts on the assumption that a merged encoder still retains abundant task knowledge from individual encoders, implying that its shared representation is sufficiently general across tasks. However, our insight is that adding just a single trainable task-specific layer further can bring striking performance gains, as demonstrated by our pilot study. Motivated by this finding, we propose Model Tinting, a new test-time approach that introduces a single task-specific layer for each task as trainable adjustments. Our method jointly trains merging coefficients and task-specific layers, which effectively reduces task conflicts with minimal additional costs. Additionally, we propose a sampling method that utilizes the difference in confidence levels of both merged and individual encoders. Extensive experiments demonstrate our method's effectiveness, which achieves state-of-the-art performance across both computer vision and natural language processing tasks and significantly surpasses prior works. Our code is available at https://github.com/AIM-SKKU/ModelTinting.
A Gated MLP Architecture for Learning Topological Dependencies in Spatio-Temporal Graphs
Jan 29, 2024Graph Neural Networks (GNNs) and Transformer have been increasingly adopted to learn the complex vector representations of spatio-temporal graphs, capturing intricate spatio-temporal dependencies crucial for applications such as traffic datasets. Although many existing methods utilize multi-head attention mechanisms and message-passing neural networks (MPNNs) to capture both spatial and temporal relations, these approaches encode temporal and spatial relations independently, and reflect the graph's topological characteristics in a limited manner. In this work, we introduce the Cycle to Mixer (Cy2Mixer), a novel spatio-temporal GNN based on topological non-trivial invariants of spatio-temporal graphs with gated multi-layer perceptrons (gMLP). The Cy2Mixer is composed of three blocks based on MLPs: A message-passing block for encapsulating spatial information, a cycle message-passing block for enriching topological information through cyclic subgraphs, and a temporal block for capturing temporal properties. We bolster the effectiveness of Cy2Mixer with mathematical evidence emphasizing that our cycle message-passing block is capable of offering differentiated information to the deep learning model compared to the message-passing block. Furthermore, empirical evaluations substantiate the efficacy of the Cy2Mixer, demonstrating state-of-the-art performances across various traffic benchmark datasets.
Diffusion Inertial Poser: Human Motion Reconstruction from Arbitrary Sparse IMU Configurations
Aug 31, 2023



Motion capture from a limited number of inertial measurement units (IMUs) has important applications in health, human performance, and virtual reality. Real-world limitations and application-specific goals dictate different IMU configurations (i.e., number of IMUs and chosen attachment body segments), trading off accuracy and practicality. Although recent works were successful in accurately reconstructing whole-body motion from six IMUs, these systems only work with a specific IMU configuration. Here we propose a single diffusion generative model, Diffusion Inertial Poser (DiffIP), which reconstructs human motion in real-time from arbitrary IMU configurations. We show that DiffIP has the benefit of flexibility with respect to the IMU configuration while being as accurate as the state-of-the-art for the commonly used six IMU configuration. Our system enables selecting an optimal configuration for different applications without retraining the model. For example, when only four IMUs are available, DiffIP found that the configuration that minimizes errors in joint kinematics instruments the thighs and forearms. However, global translation reconstruction is better when instrumenting the feet instead of the thighs. Although our approach is agnostic to the underlying model, we built DiffIP based on physiologically realistic musculoskeletal models to enable use in biomedical research and health applications.
FastSurf: Fast Neural RGB-D Surface Reconstruction using Per-Frame Intrinsic Refinement and TSDF Fusion Prior Learning
Mar 08, 2023



We introduce FastSurf, an accelerated neural radiance field (NeRF) framework that incorporates depth information for 3D reconstruction. A dense feature grid and shallow multi-layer perceptron are used for fast and accurate surface optimization of the entire scene. Our per-frame intrinsic refinement scheme corrects the frame-specific errors that cannot be handled by global optimization. Furthermore, FastSurf utilizes a classical real-time 3D surface reconstruction method, the truncated signed distance field (TSDF) Fusion, as prior knowledge to pretrain the feature grid to accelerate the training. The quantitative and qualitative experiments comparing the performances of FastSurf against prior work indicate that our method is capable of quickly and accurately reconstructing a scene with high-frequency details. We also demonstrate the effectiveness of our per-frame intrinsic refinement and TSDF Fusion prior learning techniques via an ablation study.
NoiseTransfer: Image Noise Generation with Contrastive Embeddings
Jan 31, 2023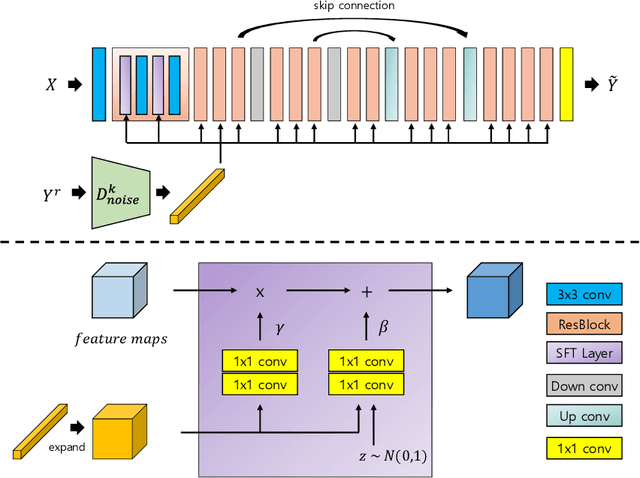
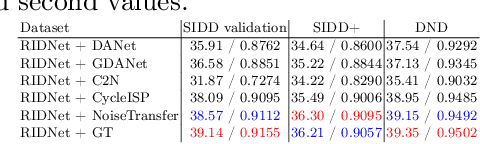
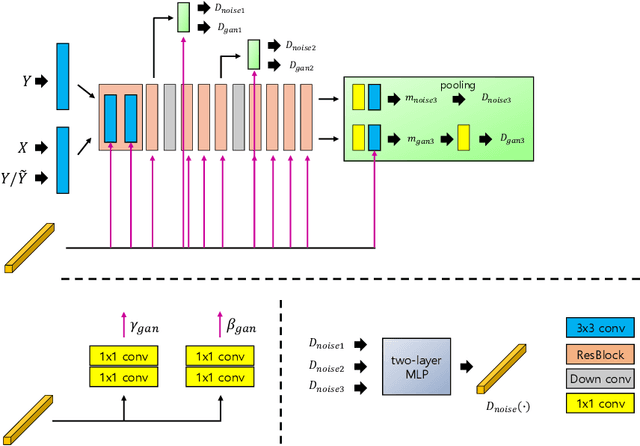

Deep image denoising networks have achieved impressive success with the help of a considerably large number of synthetic train datasets. However, real-world denoising is a still challenging problem due to the dissimilarity between distributions of real and synthetic noisy datasets. Although several real-world noisy datasets have been presented, the number of train datasets (i.e., pairs of clean and real noisy images) is limited, and acquiring more real noise datasets is laborious and expensive. To mitigate this problem, numerous attempts to simulate real noise models using generative models have been studied. Nevertheless, previous works had to train multiple networks to handle multiple different noise distributions. By contrast, we propose a new generative model that can synthesize noisy images with multiple different noise distributions. Specifically, we adopt recent contrastive learning to learn distinguishable latent features of the noise. Moreover, our model can generate new noisy images by transferring the noise characteristics solely from a single reference noisy image. We demonstrate the accuracy and the effectiveness of our noise model for both known and unknown noise removal.
Generating 3D Bio-Printable Patches Using Wound Segmentation and Reconstruction to Treat Diabetic Foot Ulcers
Mar 08, 2022
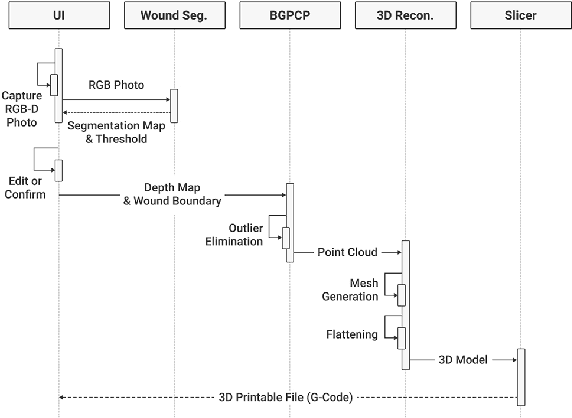
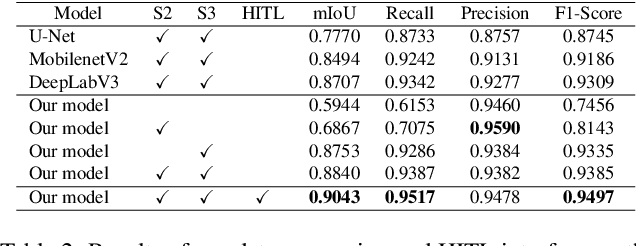
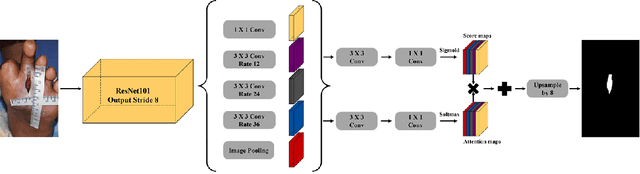
We introduce AiD Regen, a novel system that generates 3D wound models combining 2D semantic segmentation with 3D reconstruction so that they can be printed via 3D bio-printers during the surgery to treat diabetic foot ulcers (DFUs). AiD Regen seamlessly binds the full pipeline, which includes RGB-D image capturing, semantic segmentation, boundary-guided point-cloud processing, 3D model reconstruction, and 3D printable G-code generation, into a single system that can be used out of the box. We developed a multi-stage data preprocessing method to handle small and unbalanced DFU image datasets. AiD Regen's human-in-the-loop machine learning interface enables clinicians to not only create 3D regenerative patches with just a few touch interactions but also customize and confirm wound boundaries. As evidenced by our experiments, our model outperforms prior wound segmentation models and our reconstruction algorithm is capable of generating 3D wound models with compelling accuracy. We further conducted a case study on a real DFU patient and demonstrated the effectiveness of AiD Regen in treating DFU wounds.
Cycled Compositional Learning between Images and Text
Jul 24, 2021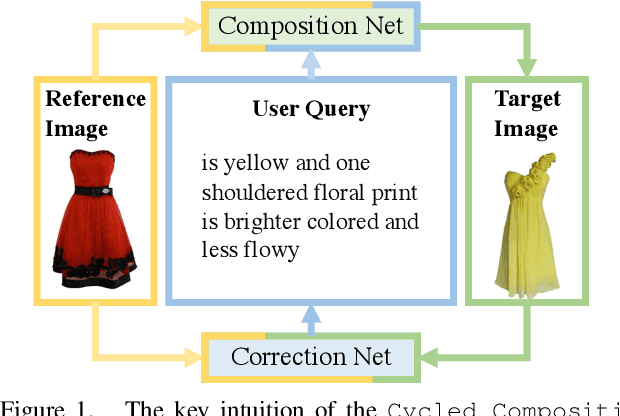
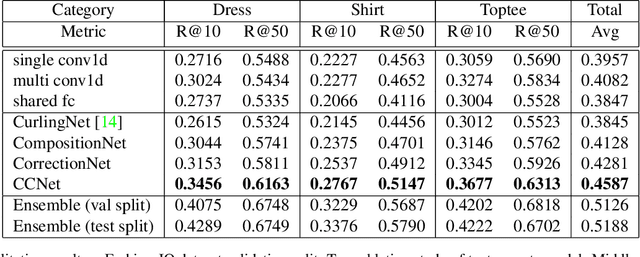
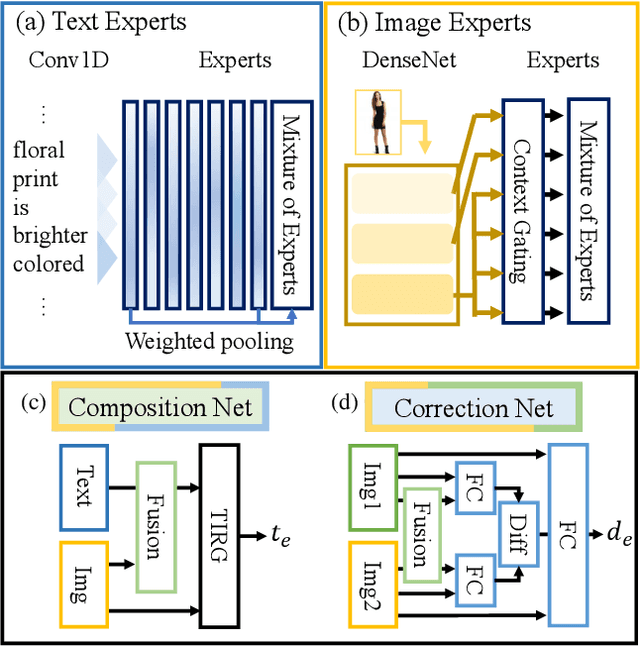
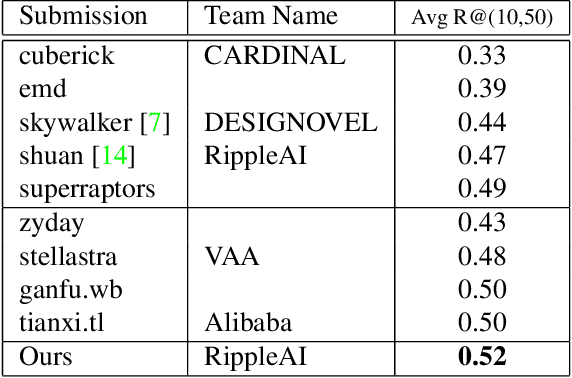
We present an approach named the Cycled Composition Network that can measure the semantic distance of the composition of image-text embedding. First, the Composition Network transit a reference image to target image in an embedding space using relative caption. Second, the Correction Network calculates a difference between reference and retrieved target images in the embedding space and match it with a relative caption. Our goal is to learn a Composition mapping with the Composition Network. Since this one-way mapping is highly under-constrained, we couple it with an inverse relation learning with the Correction Network and introduce a cycled relation for given Image We participate in Fashion IQ 2020 challenge and have won the first place with the ensemble of our model.