 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVERSA: Verified Event Data Format for Reliable Soccer Analytics
Jan 29, 2026Event stream data is a critical resource for fine-grained analysis across various domains, including financial transactions, system operations, and sports. In sports, it is actively used for fine-grained analyses such as quantifying player contributions and identifying tactical patterns. However, the reliability of these models is fundamentally limited by inherent data quality issues that cause logical inconsistencies (e.g., incorrect event ordering or missing events). To this end, this study proposes VERSA (Verified Event Data Format for Reliable Soccer Analytics), a systematic verification framework that ensures the integrity of event stream data within the soccer domain. VERSA is based on a state-transition model that defines valid event sequences, thereby enabling the automatic detection and correction of anomalous patterns within the event stream data. Notably, our examination of event data from the K League 1 (2024 season), provided by Bepro, detected that 18.81% of all recorded events exhibited logical inconsistencies. Addressing such integrity issues, our experiments demonstrate that VERSA significantly enhances cross-provider consistency, ensuring stable and unified data representation across heterogeneous sources. Furthermore, we demonstrate that data refined by VERSA significantly improves the robustness and performance of a downstream task called VAEP, which evaluates player contributions. These results highlight that the verification process is highly effective in increasing the reliability of data-driven analysis.
Learning Quadrupedal Locomotion for a Heavy Hydraulic Robot Using an Actuator Model
Jan 16, 2026The simulation-to-reality (sim-to-real) transfer of large-scale hydraulic robots presents a significant challenge in robotics because of the inherent slow control response and complex fluid dynamics. The complex dynamics result from the multiple interconnected cylinder structure and the difference in fluid rates of the cylinders. These characteristics complicate detailed simulation for all joints, making it unsuitable for reinforcement learning (RL) applications. In this work, we propose an analytical actuator model driven by hydraulic dynamics to represent the complicated actuators. The model predicts joint torques for all 12 actuators in under 1 microsecond, allowing rapid processing in RL environments. We compare our model with neural network-based actuator models and demonstrate the advantages of our model in data-limited scenarios. The locomotion policy trained in RL with our model is deployed on a hydraulic quadruped robot, which is over 300 kg. This work is the first demonstration of a successful transfer of stable and robust command-tracking locomotion with RL on a heavy hydraulic quadruped robot, demonstrating advanced sim-to-real transferability.
* 9 pages, Accepted to IEEE Robotics and Automation Letters (RA-L) 2025
Mi:dm 2.0 Korea-centric Bilingual Language Models
Jan 14, 2026We introduce Mi:dm 2.0, a bilingual large language model (LLM) specifically engineered to advance Korea-centric AI. This model goes beyond Korean text processing by integrating the values, reasoning patterns, and commonsense knowledge inherent to Korean society, enabling nuanced understanding of cultural contexts, emotional subtleties, and real-world scenarios to generate reliable and culturally appropriate responses. To address limitations of existing LLMs, often caused by insufficient or low-quality Korean data and lack of cultural alignment, Mi:dm 2.0 emphasizes robust data quality through a comprehensive pipeline that includes proprietary data cleansing, high-quality synthetic data generation, strategic data mixing with curriculum learning, and a custom Korean-optimized tokenizer to improve efficiency and coverage. To realize this vision, we offer two complementary configurations: Mi:dm 2.0 Base (11.5B parameters), built with a depth-up scaling strategy for general-purpose use, and Mi:dm 2.0 Mini (2.3B parameters), optimized for resource-constrained environments and specialized tasks. Mi:dm 2.0 achieves state-of-the-art performance on Korean-specific benchmarks, with top-tier zero-shot results on KMMLU and strong internal evaluation results across language, humanities, and social science tasks. The Mi:dm 2.0 lineup is released under the MIT license to support extensive research and commercial use. By offering accessible and high-performance Korea-centric LLMs, KT aims to accelerate AI adoption across Korean industries, public services, and education, strengthen the Korean AI developer community, and lay the groundwork for the broader vision of K-intelligence. Our models are available at https://huggingface.co/K-intelligence. For technical inquiries, please contact midm-llm@kt.com.
ScoutGPT: Capturing Player Impact from Team Action Sequences Using GPT-Based Framework
Dec 23, 2025



Transfers play a pivotal role in shaping a football club's success, yet forecasting whether a transfer will succeed remains difficult due to the strong context-dependence of on-field performance. Existing evaluation practices often rely on static summary statistics or post-hoc value models, which fail to capture how a player's contribution adapts to a new tactical environment or different teammates. To address this gap, we introduce EventGPT, a player-conditioned, value-aware next-event prediction model built on a GPT-style autoregressive transformer. Our model treats match play as a sequence of discrete tokens, jointly learning to predict the next on-ball action's type, location, timing, and its estimated residual On-Ball Value (rOBV) based on the preceding context and player identity. A key contribution of this framework is the ability to perform counterfactual simulations. By substituting learned player embeddings into new event sequences, we can simulate how a player's behavioral distribution and value profile would change when placed in a different team or tactical structure. Evaluated on five seasons of Premier League event data, EventGPT outperforms existing sequence-based baselines in next-event prediction accuracy and spatial precision. Furthermore, we demonstrate the model's practical utility for transfer analysis through case studies-such as comparing striker performance across different systems and identifying stylistic replacements for specific roles-showing that our approach provides a principled method for evaluating transfer fit.
ICML Topological Deep Learning Challenge 2024: Beyond the Graph Domain
Sep 08, 2024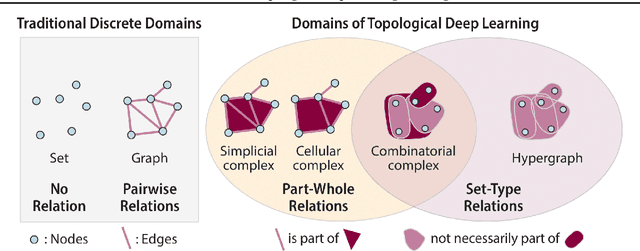
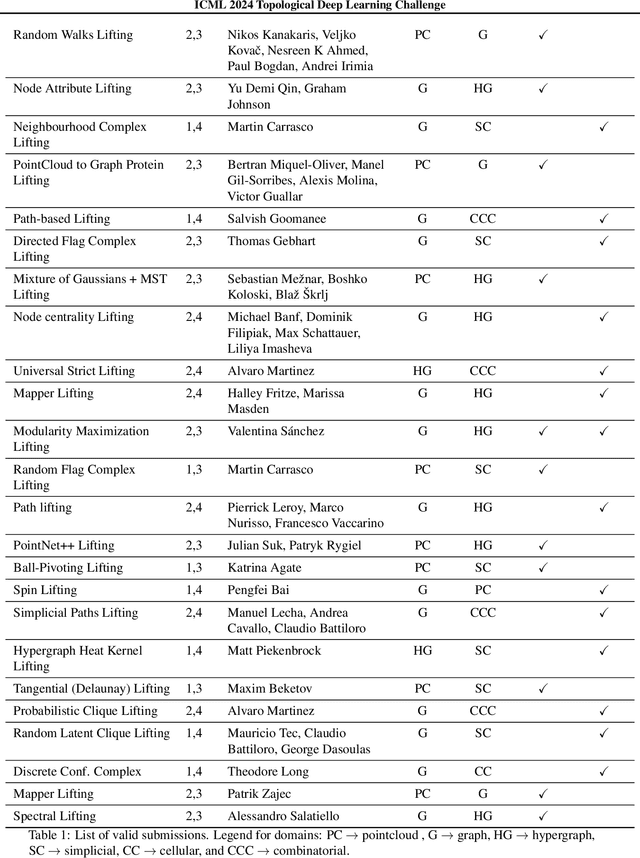
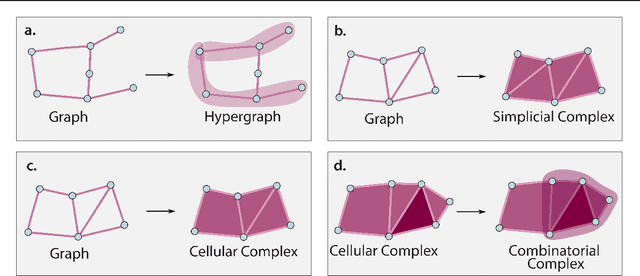
This paper describes the 2nd edition of the ICML Topological Deep Learning Challenge that was hosted within the ICML 2024 ELLIS Workshop on Geometry-grounded Representation Learning and Generative Modeling (GRaM). The challenge focused on the problem of representing data in different discrete topological domains in order to bridge the gap between Topological Deep Learning (TDL) and other types of structured datasets (e.g. point clouds, graphs). Specifically, participants were asked to design and implement topological liftings, i.e. mappings between different data structures and topological domains --like hypergraphs, or simplicial/cell/combinatorial complexes. The challenge received 52 submissions satisfying all the requirements. This paper introduces the main scope of the challenge, and summarizes the main results and findings.
DBHP: Trajectory Imputation in Multi-Agent Sports Using Derivative-Based Hybrid Prediction
Aug 20, 2024



Many spatiotemporal domains handle multi-agent trajectory data, but in real-world scenarios, collected trajectory data are often partially missing due to various reasons. While existing approaches demonstrate good performance in trajectory imputation, they face challenges in capturing the complex dynamics and interactions between agents due to a lack of physical constraints that govern realistic trajectories, leading to suboptimal results. To address this issue, the paper proposes a Derivative-Based Hybrid Prediction (DBHP) framework that can effectively impute multiple agents' missing trajectories. First, a neural network equipped with Set Transformers produces a naive prediction of missing trajectories while satisfying the permutation-equivariance in terms of the order of input agents. Then, the framework makes alternative predictions leveraging velocity and acceleration information and combines all the predictions with properly determined weights to provide final imputed trajectories. In this way, our proposed framework not only accurately predicts position, velocity, and acceleration values but also enforces the physical relationship between them, eventually improving both the accuracy and naturalness of the predicted trajectories. Accordingly, the experiment results about imputing player trajectories in team sports show that our framework significantly outperforms existing imputation baselines.
Discrete Dictionary-based Decomposition Layer for Structured Representation Learning
Jun 11, 2024



Neuro-symbolic neural networks have been extensively studied to integrate symbolic operations with neural networks, thereby improving systematic generalization. Specifically, Tensor Product Representation (TPR) framework enables neural networks to perform differentiable symbolic operations by encoding the symbolic structure of data within vector spaces. However, TPR-based neural networks often struggle to decompose unseen data into structured TPR representations, undermining their symbolic operations. To address this decomposition problem, we propose a Discrete Dictionary-based Decomposition (D3) layer designed to enhance the decomposition capabilities of TPR-based models. D3 employs discrete, learnable key-value dictionaries trained to capture symbolic features essential for decomposition operations. It leverages the prior knowledge acquired during training to generate structured TPR representations by mapping input data to pre-learned symbolic features within these dictionaries. D3 is a straightforward drop-in layer that can be seamlessly integrated into any TPR-based model without modifications. Our experimental results demonstrate that D3 significantly improves the systematic generalization of various TPR-based models while requiring fewer additional parameters. Notably, D3 outperforms baseline models on the synthetic task that demands the systematic decomposition of unseen combinatorial data.
Attention-based Iterative Decomposition for Tensor Product Representation
Jun 03, 2024



In recent research, Tensor Product Representation (TPR) is applied for the systematic generalization task of deep neural networks by learning the compositional structure of data. However, such prior works show limited performance in discovering and representing the symbolic structure from unseen test data because their decomposition to the structural representations was incomplete. In this work, we propose an Attention-based Iterative Decomposition (AID) module designed to enhance the decomposition operations for the structured representations encoded from the sequential input data with TPR. Our AID can be easily adapted to any TPR-based model and provides enhanced systematic decomposition through a competitive attention mechanism between input features and structured representations. In our experiments, AID shows effectiveness by significantly improving the performance of TPR-based prior works on the series of systematic generalization tasks. Moreover, in the quantitative and qualitative evaluations, AID produces more compositional and well-bound structural representations than other works.
Punctuation Restoration Improves Structure Understanding without Supervision
Feb 21, 2024



Unsupervised learning objectives like language modeling and de-noising constitute a significant part in producing pre-trained models that perform various downstream applications from natural language understanding to conversational tasks. However, despite impressive generative capabilities of recent large language models, their abilities to capture syntactic or semantic structure within text lag behind. We hypothesize that the mismatch between linguistic performance and competence in machines is attributable to insufficient transfer of linguistic structure knowledge to computational systems with currently popular pre-training objectives. We show that punctuation restoration as a learning objective improves in- and out-of-distribution performance on structure-related tasks like named entity recognition, open information extraction, chunking, and part-of-speech tagging. Punctuation restoration is an effective learning objective that can improve structure understanding and yield a more robust structure-aware representations of natural language.
Structured Language Generation Model for Robust Structure Prediction
Feb 19, 2024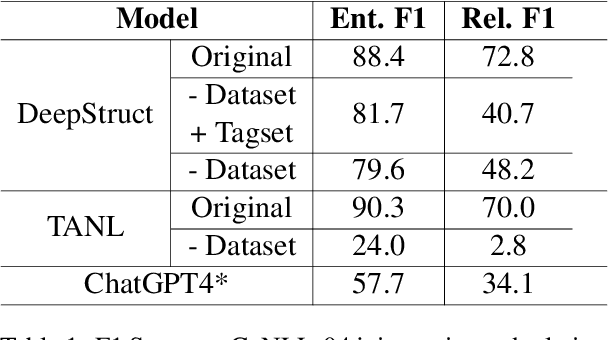

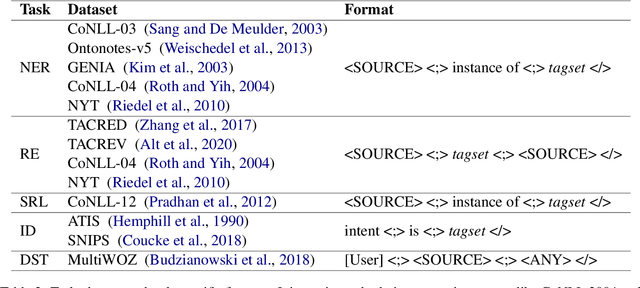
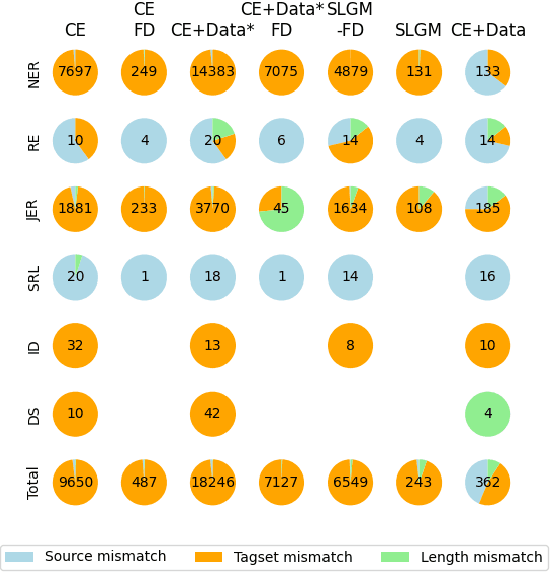
Previous work in structured prediction (e.g. NER, information extraction) using single model make use of explicit dataset information, which helps boost in-distribution performance but is orthogonal to robust generalization in real-world situations. To overcome this limitation, we propose the Structured Language Generation Model (SLGM), a framework that reduces sequence-to-sequence problems to classification problems via methodologies in loss calibration and decoding method. Our experimental results show that SLGM is able to maintain performance without explicit dataset information, follow and potentially replace dataset-specific fine-tuning.