 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Matches as Language: A Generative Transformer Approach for Counterfactual Player Valuation in Football
Mar 16, 2026Evaluating football player transfers is challenging because player actions depend strongly on tactical systems, teammates, and match context. Despite this complexity, recruitment decisions often rely on static statistics and subjective expert judgment, which do not fully account for these contextual factors. This limitation stems largely from the absence of counterfactual simulation mechanisms capable of predicting outcomes in hypothetical scenarios. To address these challenges, we propose ScoutGPT, a generative model that treats football match events as sequential tokens within a language modeling framework. Utilizing a NanoGPT-based Transformer architecture trained on next-token prediction, ScoutGPT learns the dynamics of match event sequences to simulate event sequences under hypothetical lineups, demonstrating superior predictive performance compared to existing baseline models. Leveraging this capability, the model employs Monte Carlo sampling to enable counterfactual simulation, allowing for the assessment of unobserved scenarios. Experiments on K League data show that simulated player transfers lead to measurable changes in offensive progression and goal probabilities, indicating that ScoutGPT captures player-specific impact beyond traditional static metrics.
PathCRF: Ball-Free Soccer Event Detection via Possession Path Inference from Player Trajectories
Feb 12, 2026Despite recent advances in AI, event data collection in soccer still relies heavily on labor-intensive manual annotation. Although prior work has explored automatic event detection using player and ball trajectories, ball tracking also remains difficult to scale due to high infrastructural and operational costs. As a result, comprehensive data collection in soccer is largely confined to top-tier competitions, limiting the broader adoption of data-driven analysis in this domain. To address this challenge, this paper proposes PathCRF, a framework for detecting on-ball soccer events using only player tracking data. We model player trajectories as a fully connected dynamic graph and formulate event detection as the problem of selecting exactly one edge corresponding to the current possession state at each time step. To ensure logical consistency of the resulting edge sequence, we employ a Conditional Random Field (CRF) that forbids impossible transitions between consecutive edges. Both emission and transition scores dynamically computed from edge embeddings produced by a Set Attention-based backbone architecture. During inference, the most probable edge sequence is obtained via Viterbi decoding, and events such as ball controls or passes are detected whenever the selected edge changes between adjacent time steps. Experiments show that PathCRF produces accurate, logically consistent possession paths, enabling reliable downstream analyses while substantially reducing the need for manual event annotation. The source code is available at https://github.com/hyunsungkim-ds/pathcrf.git.
VERSA: Verified Event Data Format for Reliable Soccer Analytics
Jan 29, 2026Event stream data is a critical resource for fine-grained analysis across various domains, including financial transactions, system operations, and sports. In sports, it is actively used for fine-grained analyses such as quantifying player contributions and identifying tactical patterns. However, the reliability of these models is fundamentally limited by inherent data quality issues that cause logical inconsistencies (e.g., incorrect event ordering or missing events). To this end, this study proposes VERSA (Verified Event Data Format for Reliable Soccer Analytics), a systematic verification framework that ensures the integrity of event stream data within the soccer domain. VERSA is based on a state-transition model that defines valid event sequences, thereby enabling the automatic detection and correction of anomalous patterns within the event stream data. Notably, our examination of event data from the K League 1 (2024 season), provided by Bepro, detected that 18.81% of all recorded events exhibited logical inconsistencies. Addressing such integrity issues, our experiments demonstrate that VERSA significantly enhances cross-provider consistency, ensuring stable and unified data representation across heterogeneous sources. Furthermore, we demonstrate that data refined by VERSA significantly improves the robustness and performance of a downstream task called VAEP, which evaluates player contributions. These results highlight that the verification process is highly effective in increasing the reliability of data-driven analysis.
ScoutGPT: Capturing Player Impact from Team Action Sequences Using GPT-Based Framework
Dec 23, 2025



Transfers play a pivotal role in shaping a football club's success, yet forecasting whether a transfer will succeed remains difficult due to the strong context-dependence of on-field performance. Existing evaluation practices often rely on static summary statistics or post-hoc value models, which fail to capture how a player's contribution adapts to a new tactical environment or different teammates. To address this gap, we introduce EventGPT, a player-conditioned, value-aware next-event prediction model built on a GPT-style autoregressive transformer. Our model treats match play as a sequence of discrete tokens, jointly learning to predict the next on-ball action's type, location, timing, and its estimated residual On-Ball Value (rOBV) based on the preceding context and player identity. A key contribution of this framework is the ability to perform counterfactual simulations. By substituting learned player embeddings into new event sequences, we can simulate how a player's behavioral distribution and value profile would change when placed in a different team or tactical structure. Evaluated on five seasons of Premier League event data, EventGPT outperforms existing sequence-based baselines in next-event prediction accuracy and spatial precision. Furthermore, we demonstrate the model's practical utility for transfer analysis through case studies-such as comparing striker performance across different systems and identifying stylistic replacements for specific roles-showing that our approach provides a principled method for evaluating transfer fit.
LogiCase: Effective Test Case Generation from Logical Description in Competitive Programming
May 21, 2025Automated Test Case Generation (ATCG) is crucial for evaluating software reliability, particularly in competitive programming where robust algorithm assessments depend on diverse and accurate test cases. However, existing ATCG methods often fail to meet complex specifications or generate effective corner cases, limiting their utility. In this work, we introduce Context-Free Grammars with Counters (CCFGs), a formalism that captures both syntactic and semantic structures in input specifications. Using a fine-tuned CodeT5 model, we translate natural language input specifications into CCFGs, enabling the systematic generation of high-quality test cases. Experiments on the CodeContests dataset demonstrate that CCFG-based test cases outperform baseline methods in identifying incorrect algorithms, achieving significant gains in validity and effectiveness. Our approach provides a scalable and reliable grammar-driven framework for enhancing automated competitive programming evaluations.
SPECTra: Scalable Multi-Agent Reinforcement Learning with Permutation-Free Networks
Mar 14, 2025



In cooperative multi-agent reinforcement learning (MARL), the permutation problem where the state space grows exponentially with the number of agents reduces sample efficiency. Additionally, many existing architectures struggle with scalability, relying on a fixed structure tied to a specific number of agents, limiting their applicability to environments with a variable number of entities. While approaches such as graph neural networks (GNNs) and self-attention mechanisms have progressed in addressing these challenges, they have significant limitations as dense GNNs and self-attention mechanisms incur high computational costs. To overcome these limitations, we propose a novel agent network and a non-linear mixing network that ensure permutation-equivariance and scalability, allowing them to generalize to environments with various numbers of agents. Our agent network significantly reduces computational complexity, and our scalable hypernetwork enables efficient weight generation for non-linear mixing. Additionally, we introduce curriculum learning to improve training efficiency. Experiments on SMACv2 and Google Research Football (GRF) demonstrate that our approach achieves superior learning performance compared to existing methods. By addressing both permutation-invariance and scalability in MARL, our work provides a more efficient and adaptable framework for cooperative MARL. Our code is available at https://github.com/funny-rl/SPECTra.
MPruner: Optimizing Neural Network Size with CKA-Based Mutual Information Pruning
Aug 24, 2024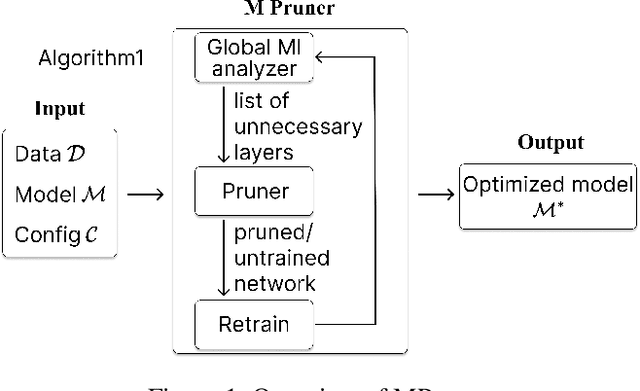

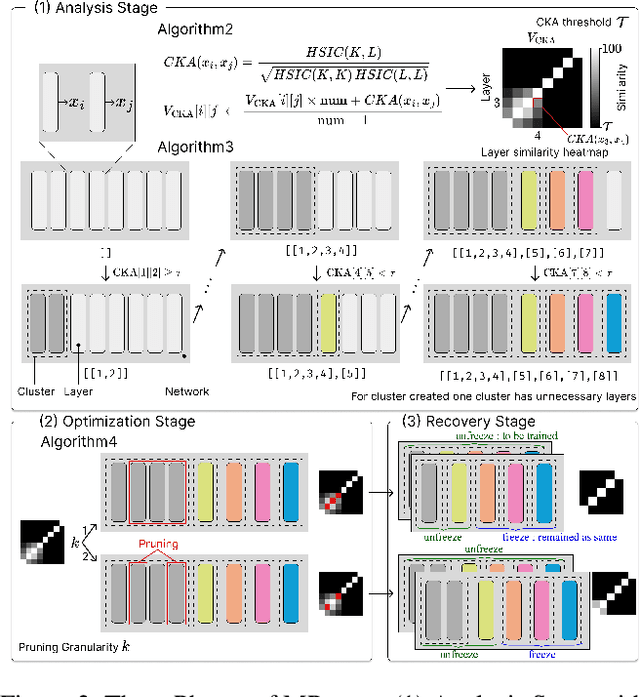
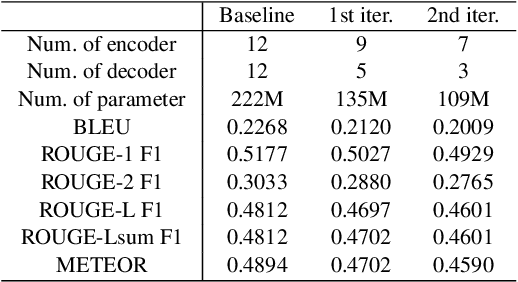
Determining the optimal size of a neural network is critical, as it directly impacts runtime performance and memory usage. Pruning is a well-established model compression technique that reduces the size of neural networks while mathematically guaranteeing accuracy preservation. However, many recent pruning methods overlook the global contributions of individual model components, making it difficult to ensure that a pruned model meets the desired dataset and performance requirements. To address these challenges, we developed a new pruning algorithm, MPruner, that leverages mutual information through vector similarity. MPruner utilizes layer clustering with the Centered Kernel Alignment (CKA) similarity metric, allowing us to incorporate global information from the neural network for more precise and efficient layer-wise pruning. We evaluated MPruner across various architectures and configurations, demonstrating its versatility and providing practical guidelines. MPruner achieved up to a 50% reduction in parameters and memory usage for CNN and transformer-based models, with minimal to no loss in accuracy.
DBHP: Trajectory Imputation in Multi-Agent Sports Using Derivative-Based Hybrid Prediction
Aug 20, 2024



Many spatiotemporal domains handle multi-agent trajectory data, but in real-world scenarios, collected trajectory data are often partially missing due to various reasons. While existing approaches demonstrate good performance in trajectory imputation, they face challenges in capturing the complex dynamics and interactions between agents due to a lack of physical constraints that govern realistic trajectories, leading to suboptimal results. To address this issue, the paper proposes a Derivative-Based Hybrid Prediction (DBHP) framework that can effectively impute multiple agents' missing trajectories. First, a neural network equipped with Set Transformers produces a naive prediction of missing trajectories while satisfying the permutation-equivariance in terms of the order of input agents. Then, the framework makes alternative predictions leveraging velocity and acceleration information and combines all the predictions with properly determined weights to provide final imputed trajectories. In this way, our proposed framework not only accurately predicts position, velocity, and acceleration values but also enforces the physical relationship between them, eventually improving both the accuracy and naturalness of the predicted trajectories. Accordingly, the experiment results about imputing player trajectories in team sports show that our framework significantly outperforms existing imputation baselines.
Towards Efficient Formal Verification of Spiking Neural Network
Aug 20, 2024



Recently, AI research has primarily focused on large language models (LLMs), and increasing accuracy often involves scaling up and consuming more power. The power consumption of AI has become a significant societal issue; in this context, spiking neural networks (SNNs) offer a promising solution. SNNs operate event-driven, like the human brain, and compress information temporally. These characteristics allow SNNs to significantly reduce power consumption compared to perceptron-based artificial neural networks (ANNs), highlighting them as a next-generation neural network technology. However, societal concerns regarding AI go beyond power consumption, with the reliability of AI models being a global issue. For instance, adversarial attacks on AI models are a well-studied problem in the context of traditional neural networks. Despite their importance, the stability and property verification of SNNs remains in the early stages of research. Most SNN verification methods are time-consuming and barely scalable, making practical applications challenging. In this paper, we introduce temporal encoding to achieve practical performance in verifying the adversarial robustness of SNNs. We conduct a theoretical analysis of this approach and demonstrate its success in verifying SNNs at previously unmanageable scales. Our contribution advances SNN verification to a practical level, facilitating the safer application of SNNs.
Contextual Sprint Classification in Soccer Based on Deep Learning
Jun 21, 2024The analysis of high-intensity runs (or sprints) in soccer has long been a topic of interest for sports science researchers and practitioners. In particular, recent studies suggested contextualizing sprints based on their tactical purposes to better understand the physical-tactical requirements of modern match-play. However, they have a limitation in scalability, as human experts have to manually classify hundreds of sprints for every match. To address this challenge, this paper proposes a deep learning framework for automatically classifying sprints in soccer into contextual categories. The proposed model covers the permutation-invariant and sequential nature of multi-agent trajectories in soccer by deploying Set Transformers and a bidirectional GRU. We train the model with category labels made through the collaboration of human annotators and a rule-based classifier. Experimental results show that our model classifies sprints in the test dataset into 15 categories with the accuracy of 77.65%, implying the potential of the proposed framework for facilitating the integrated analysis of soccer sprints at scale.