 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBall Trajectory Inference from Multi-Agent Sports Contexts Using Set Transformer and Hierarchical Bi-LSTM
Jun 14, 2023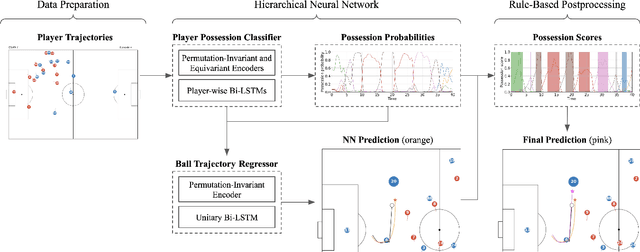
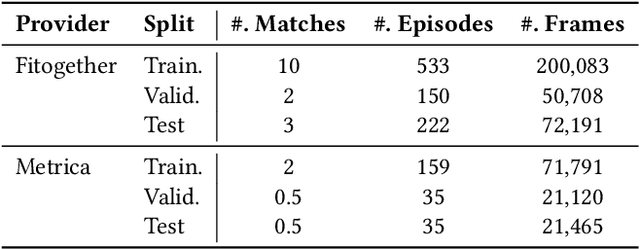
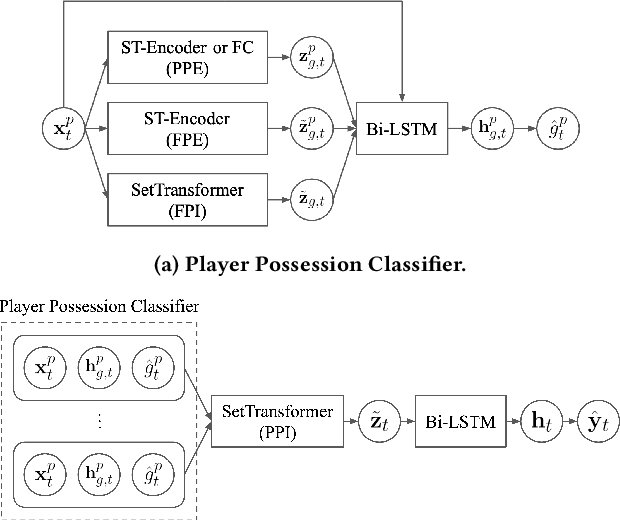
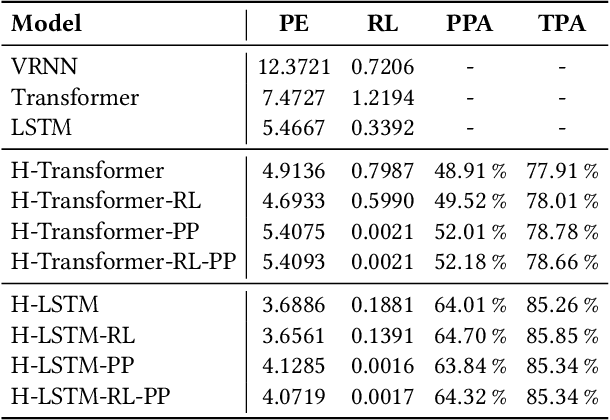
As artificial intelligence spreads out to numerous fields, the application of AI to sports analytics is also in the spotlight. However, one of the major challenges is the difficulty of automated acquisition of continuous movement data during sports matches. In particular, it is a conundrum to reliably track a tiny ball on a wide soccer pitch with obstacles such as occlusion and imitations. Tackling the problem, this paper proposes an inference framework of ball trajectory from player trajectories as a cost-efficient alternative to ball tracking. We combine Set Transformers to get permutation-invariant and equivariant representations of the multi-agent contexts with a hierarchical architecture that intermediately predicts the player ball possession to support the final trajectory inference. Also, we introduce the reality loss term and postprocessing to secure the estimated trajectories to be physically realistic. The experimental results show that our model provides natural and accurate trajectories as well as admissible player ball possession at the same time. Lastly, we suggest several practical applications of our framework including missing trajectory imputation, semi-automated pass annotation, automated zoom-in for match broadcasting, and calculating possession-wise running performance metrics.
Neural Sign Language Translation based on Human Keypoint Estimation
Nov 28, 2018
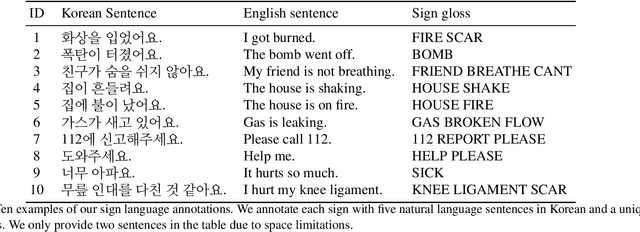
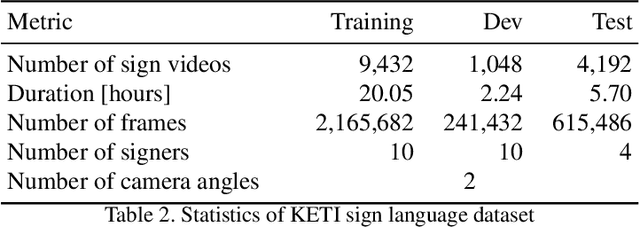

We propose a sign language translation system based on human keypoint estimation. It is well-known that many problems in the field of computer vision require a massive amount of dataset to train deep neural network models. The situation is even worse when it comes to the sign language translation problem as it is far more difficult to collect high-quality training data. In this paper, we introduce the KETI sign language dataset which consists of 11,578 videos of high resolution and quality. Considering the fact that each country has a different and unique sign language, the KETI sign language dataset can be the starting line for further research on the Korean sign language translation. Using the KETI sign language dataset, we develop a neural network model for translating sign videos into natural language sentences by utilizing the human keypoints extracted from a face, hands, and body parts. The obtained human keypoint vector is normalized by the mean and standard deviation of the keypoints and used as input to our translation model based on the sequence-to-sequence architecture. As a result, we show that our approach is robust even when the size of the training data is not sufficient. Our translation model achieves 94.6% (60.6%, respectively) translation accuracy on the validation set (test set, respectively) for 105 sentences that can be used in emergency situations. We compare several types of our neural sign translation models based on different attention mechanisms in terms of classical metrics for measuring the translation performance.