 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Sign Language Translation based on Human Keypoint Estimation
Nov 28, 2018
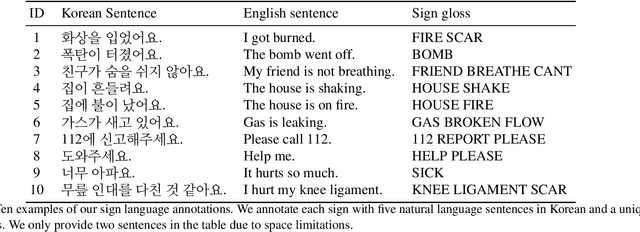
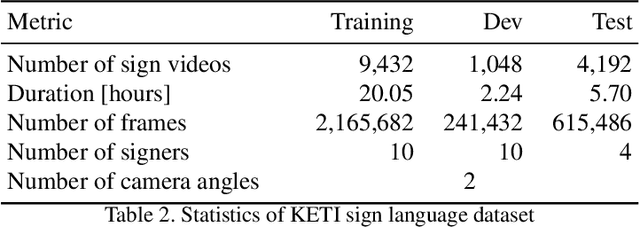

We propose a sign language translation system based on human keypoint estimation. It is well-known that many problems in the field of computer vision require a massive amount of dataset to train deep neural network models. The situation is even worse when it comes to the sign language translation problem as it is far more difficult to collect high-quality training data. In this paper, we introduce the KETI sign language dataset which consists of 11,578 videos of high resolution and quality. Considering the fact that each country has a different and unique sign language, the KETI sign language dataset can be the starting line for further research on the Korean sign language translation. Using the KETI sign language dataset, we develop a neural network model for translating sign videos into natural language sentences by utilizing the human keypoints extracted from a face, hands, and body parts. The obtained human keypoint vector is normalized by the mean and standard deviation of the keypoints and used as input to our translation model based on the sequence-to-sequence architecture. As a result, we show that our approach is robust even when the size of the training data is not sufficient. Our translation model achieves 94.6% (60.6%, respectively) translation accuracy on the validation set (test set, respectively) for 105 sentences that can be used in emergency situations. We compare several types of our neural sign translation models based on different attention mechanisms in terms of classical metrics for measuring the translation performance.
Distinctive-attribute Extraction for Image Captioning
Jul 25, 2018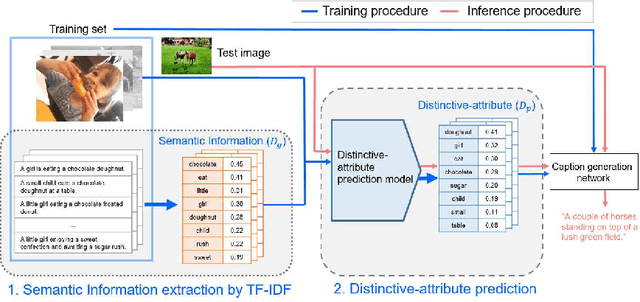
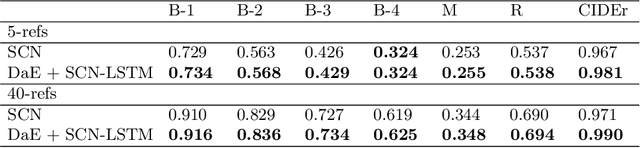

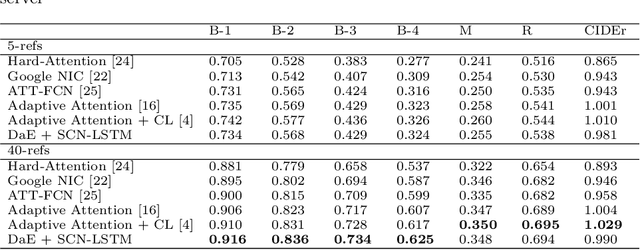
Image captioning, an open research issue, has been evolved with the progress of deep neural networks. Convolutional neural networks (CNNs) and recurrent neural networks (RNNs) are employed to compute image features and generate natural language descriptions in the research. In previous works, a caption involving semantic description can be generated by applying additional information into the RNNs. In this approach, we propose a distinctive-attribute extraction (DaE) which explicitly encourages significant meanings to generate an accurate caption describing the overall meaning of the image with their unique situation. Specifically, the captions of training images are analyzed by term frequency-inverse document frequency (TF-IDF), and the analyzed semantic information is trained to extract distinctive-attributes for inferring captions. The proposed scheme is evaluated on a challenge data, and it improves an objective performance while describing images in more detail.