 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistinctive-attribute Extraction for Image Captioning
Paper and Code
Jul 25, 2018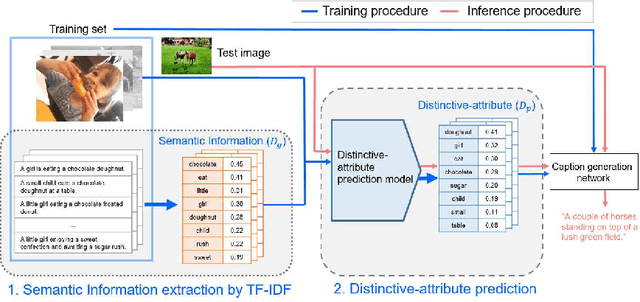
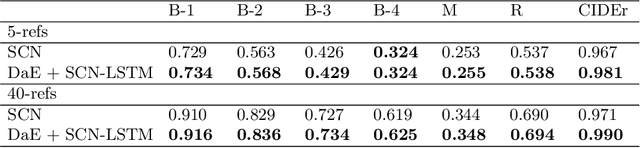

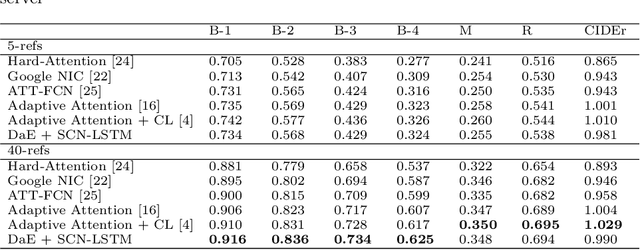
Image captioning, an open research issue, has been evolved with the progress of deep neural networks. Convolutional neural networks (CNNs) and recurrent neural networks (RNNs) are employed to compute image features and generate natural language descriptions in the research. In previous works, a caption involving semantic description can be generated by applying additional information into the RNNs. In this approach, we propose a distinctive-attribute extraction (DaE) which explicitly encourages significant meanings to generate an accurate caption describing the overall meaning of the image with their unique situation. Specifically, the captions of training images are analyzed by term frequency-inverse document frequency (TF-IDF), and the analyzed semantic information is trained to extract distinctive-attributes for inferring captions. The proposed scheme is evaluated on a challenge data, and it improves an objective performance while describing images in more detail.