 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMi:dm 2.0 Korea-centric Bilingual Language Models
Jan 14, 2026We introduce Mi:dm 2.0, a bilingual large language model (LLM) specifically engineered to advance Korea-centric AI. This model goes beyond Korean text processing by integrating the values, reasoning patterns, and commonsense knowledge inherent to Korean society, enabling nuanced understanding of cultural contexts, emotional subtleties, and real-world scenarios to generate reliable and culturally appropriate responses. To address limitations of existing LLMs, often caused by insufficient or low-quality Korean data and lack of cultural alignment, Mi:dm 2.0 emphasizes robust data quality through a comprehensive pipeline that includes proprietary data cleansing, high-quality synthetic data generation, strategic data mixing with curriculum learning, and a custom Korean-optimized tokenizer to improve efficiency and coverage. To realize this vision, we offer two complementary configurations: Mi:dm 2.0 Base (11.5B parameters), built with a depth-up scaling strategy for general-purpose use, and Mi:dm 2.0 Mini (2.3B parameters), optimized for resource-constrained environments and specialized tasks. Mi:dm 2.0 achieves state-of-the-art performance on Korean-specific benchmarks, with top-tier zero-shot results on KMMLU and strong internal evaluation results across language, humanities, and social science tasks. The Mi:dm 2.0 lineup is released under the MIT license to support extensive research and commercial use. By offering accessible and high-performance Korea-centric LLMs, KT aims to accelerate AI adoption across Korean industries, public services, and education, strengthen the Korean AI developer community, and lay the groundwork for the broader vision of K-intelligence. Our models are available at https://huggingface.co/K-intelligence. For technical inquiries, please contact midm-llm@kt.com.
Roll Your Eyes: Gaze Redirection via Explicit 3D Eyeball Rotation
Aug 08, 2025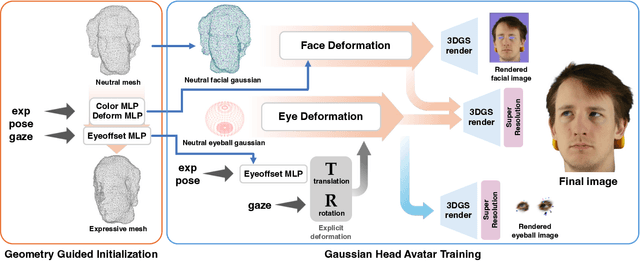
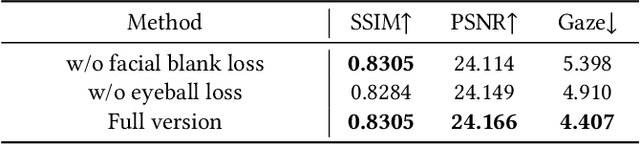
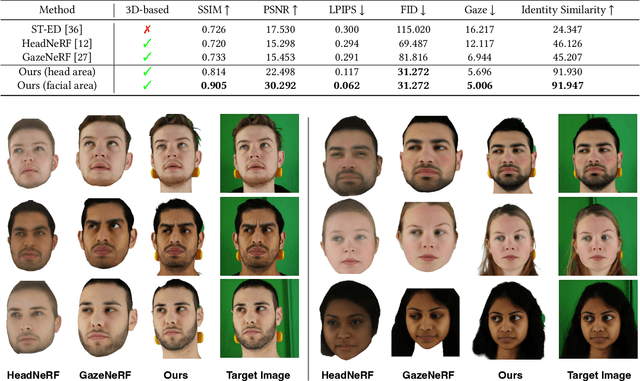

We propose a novel 3D gaze redirection framework that leverages an explicit 3D eyeball structure. Existing gaze redirection methods are typically based on neural radiance fields, which employ implicit neural representations via volume rendering. Unlike these NeRF-based approaches, where the rotation and translation of 3D representations are not explicitly modeled, we introduce a dedicated 3D eyeball structure to represent the eyeballs with 3D Gaussian Splatting (3DGS). Our method generates photorealistic images that faithfully reproduce the desired gaze direction by explicitly rotating and translating the 3D eyeball structure. In addition, we propose an adaptive deformation module that enables the replication of subtle muscle movements around the eyes. Through experiments conducted on the ETH-XGaze dataset, we demonstrate that our framework is capable of generating diverse novel gaze images, achieving superior image quality and gaze estimation accuracy compared to previous state-of-the-art methods.
PersonaBooth: Personalized Text-to-Motion Generation
Mar 10, 2025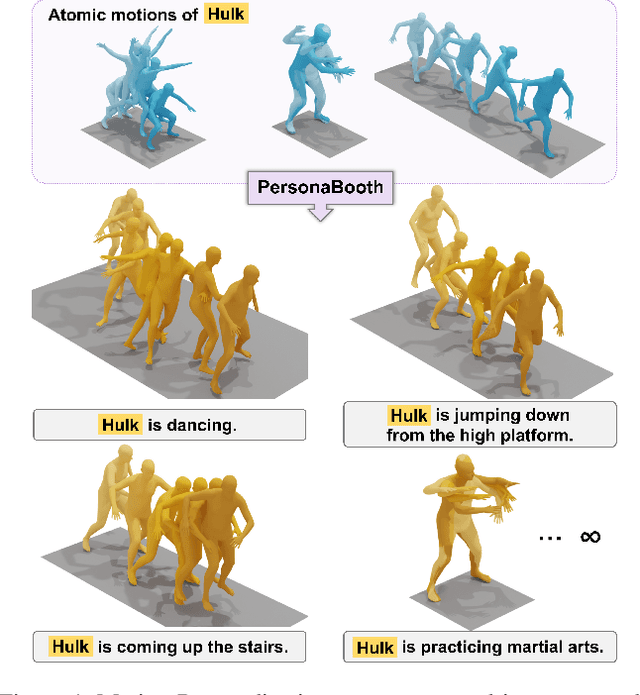



This paper introduces Motion Personalization, a new task that generates personalized motions aligned with text descriptions using several basic motions containing Persona. To support this novel task, we introduce a new large-scale motion dataset called PerMo (PersonaMotion), which captures the unique personas of multiple actors. We also propose a multi-modal finetuning method of a pretrained motion diffusion model called PersonaBooth. PersonaBooth addresses two main challenges: i) A significant distribution gap between the persona-focused PerMo dataset and the pretraining datasets, which lack persona-specific data, and ii) the difficulty of capturing a consistent persona from the motions vary in content (action type). To tackle the dataset distribution gap, we introduce a persona token to accept new persona features and perform multi-modal adaptation for both text and visuals during finetuning. To capture a consistent persona, we incorporate a contrastive learning technique to enhance intra-cohesion among samples with the same persona. Furthermore, we introduce a context-aware fusion mechanism to maximize the integration of persona cues from multiple input motions. PersonaBooth outperforms state-of-the-art motion style transfer methods, establishing a new benchmark for motion personalization.
MoST: Motion Style Transformer between Diverse Action Contents
Mar 20, 2024



While existing motion style transfer methods are effective between two motions with identical content, their performance significantly diminishes when transferring style between motions with different contents. This challenge lies in the lack of clear separation between content and style of a motion. To tackle this challenge, we propose a novel motion style transformer that effectively disentangles style from content and generates a plausible motion with transferred style from a source motion. Our distinctive approach to achieving the goal of disentanglement is twofold: (1) a new architecture for motion style transformer with `part-attentive style modulator across body parts' and `Siamese encoders that encode style and content features separately'; (2) style disentanglement loss. Our method outperforms existing methods and demonstrates exceptionally high quality, particularly in motion pairs with different contents, without the need for heuristic post-processing. Codes are available at https://github.com/Boeun-Kim/MoST.
Global-local Motion Transformer for Unsupervised Skeleton-based Action Learning
Jul 13, 2022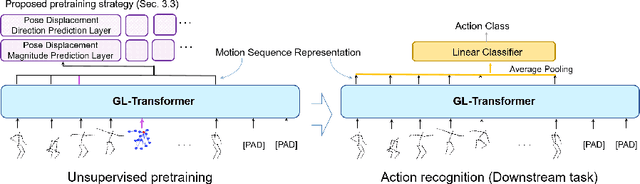

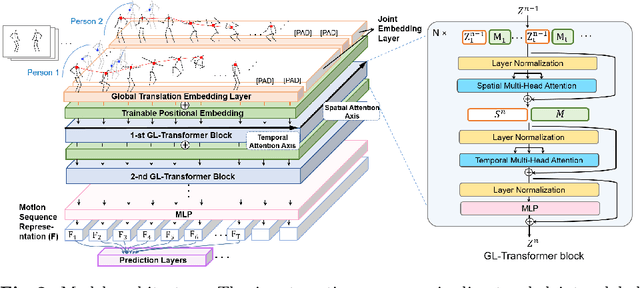

We propose a new transformer model for the task of unsupervised learning of skeleton motion sequences. The existing transformer model utilized for unsupervised skeleton-based action learning is learned the instantaneous velocity of each joint from adjacent frames without global motion information. Thus, the model has difficulties in learning the attention globally over whole-body motions and temporally distant joints. In addition, person-to-person interactions have not been considered in the model. To tackle the learning of whole-body motion, long-range temporal dynamics, and person-to-person interactions, we design a global and local attention mechanism, where, global body motions and local joint motions pay attention to each other. In addition, we propose a novel pretraining strategy, multi-interval pose displacement prediction, to learn both global and local attention in diverse time ranges. The proposed model successfully learns local dynamics of the joints and captures global context from the motion sequences. Our model outperforms state-of-the-art models by notable margins in the representative benchmarks. Codes are available at https://github.com/Boeun-Kim/GL-Transformer.
Distinctive-attribute Extraction for Image Captioning
Jul 25, 2018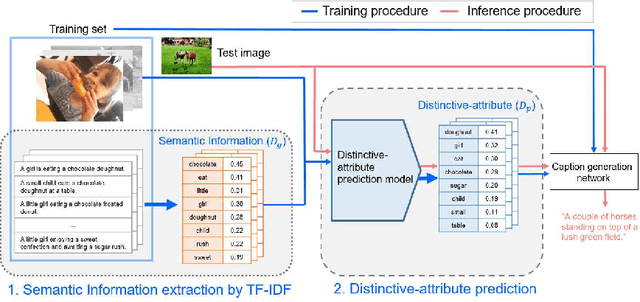
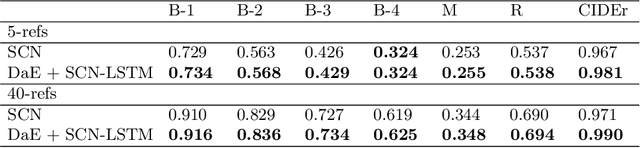

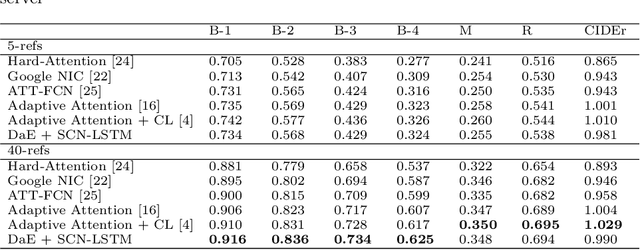
Image captioning, an open research issue, has been evolved with the progress of deep neural networks. Convolutional neural networks (CNNs) and recurrent neural networks (RNNs) are employed to compute image features and generate natural language descriptions in the research. In previous works, a caption involving semantic description can be generated by applying additional information into the RNNs. In this approach, we propose a distinctive-attribute extraction (DaE) which explicitly encourages significant meanings to generate an accurate caption describing the overall meaning of the image with their unique situation. Specifically, the captions of training images are analyzed by term frequency-inverse document frequency (TF-IDF), and the analyzed semantic information is trained to extract distinctive-attributes for inferring captions. The proposed scheme is evaluated on a challenge data, and it improves an objective performance while describing images in more detail.