 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonaBooth: Personalized Text-to-Motion Generation
Mar 10, 2025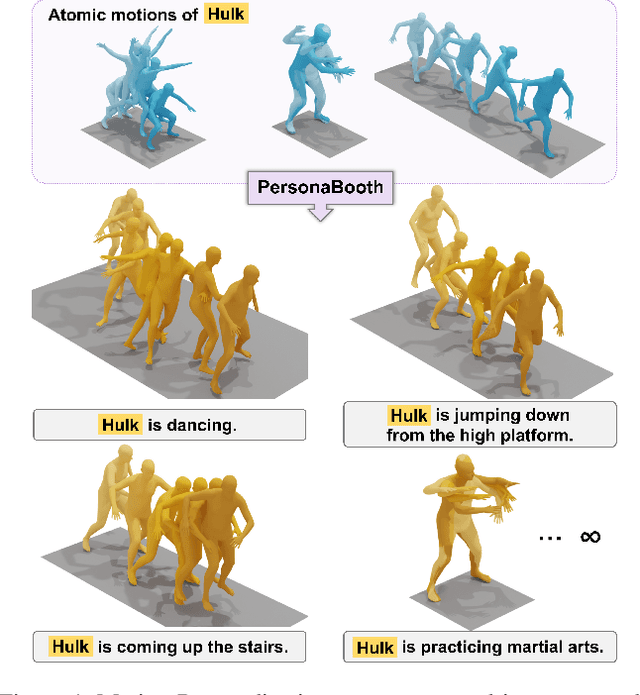



This paper introduces Motion Personalization, a new task that generates personalized motions aligned with text descriptions using several basic motions containing Persona. To support this novel task, we introduce a new large-scale motion dataset called PerMo (PersonaMotion), which captures the unique personas of multiple actors. We also propose a multi-modal finetuning method of a pretrained motion diffusion model called PersonaBooth. PersonaBooth addresses two main challenges: i) A significant distribution gap between the persona-focused PerMo dataset and the pretraining datasets, which lack persona-specific data, and ii) the difficulty of capturing a consistent persona from the motions vary in content (action type). To tackle the dataset distribution gap, we introduce a persona token to accept new persona features and perform multi-modal adaptation for both text and visuals during finetuning. To capture a consistent persona, we incorporate a contrastive learning technique to enhance intra-cohesion among samples with the same persona. Furthermore, we introduce a context-aware fusion mechanism to maximize the integration of persona cues from multiple input motions. PersonaBooth outperforms state-of-the-art motion style transfer methods, establishing a new benchmark for motion personalization.
Efficient Gradient-Based Inference for Manipulation Planning in Contact Factor Graphs
Mar 08, 2025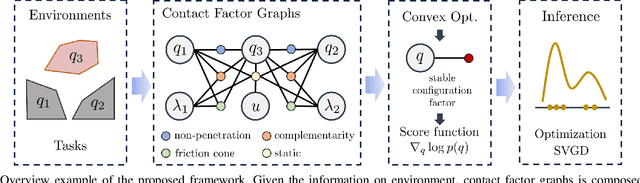



This paper presents a framework designed to tackle a range of planning problems arise in manipulation, which typically involve complex geometric-physical reasoning related to contact and dynamic constraints. We introduce the Contact Factor Graph (CFG) to graphically model these diverse factors, enabling us to perform inference on the graphs to approximate the distribution and sample appropriate solutions. We propose a novel approach that can incorporate various phenomena of contact manipulation as differentiable factors, and develop an efficient inference algorithm for CFG that leverages this differentiability along with the conditional probabilities arising from the structured nature of contact. Our results demonstrate the capability of our framework in generating viable samples and approximating posterior distributions for various manipulation scenarios.
Variations of Augmented Lagrangian for Robotic Multi-Contact Simulation
Feb 24, 2025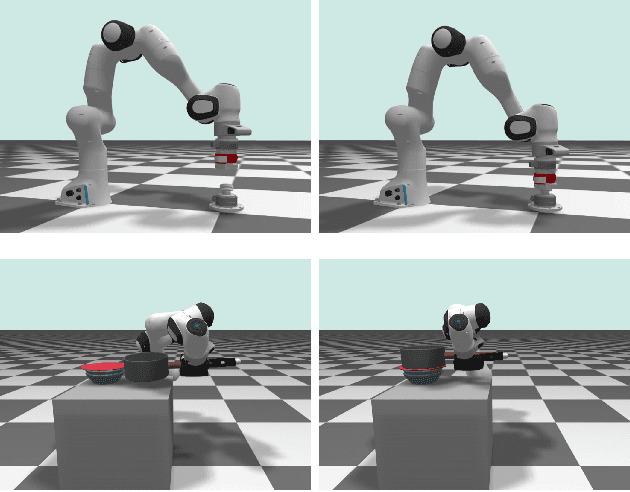



The multi-contact nonlinear complementarity problem (NCP) is a naturally arising challenge in robotic simulations. Achieving high performance in terms of both accuracy and efficiency remains a significant challenge, particularly in scenarios involving intensive contacts and stiff interactions. In this article, we introduce a new class of multi-contact NCP solvers based on the theory of the Augmented Lagrangian (AL). We detail how the standard derivation of AL in convex optimization can be adapted to handle multi-contact NCP through the iteration of surrogate problem solutions and the subsequent update of primal-dual variables. Specifically, we present two tailored variations of AL for robotic simulations: the Cascaded Newton-based Augmented Lagrangian (CANAL) and the Subsystem-based Alternating Direction Method of Multipliers (SubADMM). We demonstrate how CANAL can manage multi-contact NCP in an accurate and robust manner, while SubADMM offers superior computational speed, scalability, and parallelizability for high degrees-of-freedom multibody systems with numerous contacts. Our results showcase the effectiveness of the proposed solver framework, illustrating its advantages in various robotic manipulation scenarios.
Narrow Passage Path Planning using Collision Constraint Interpolation
Oct 28, 2024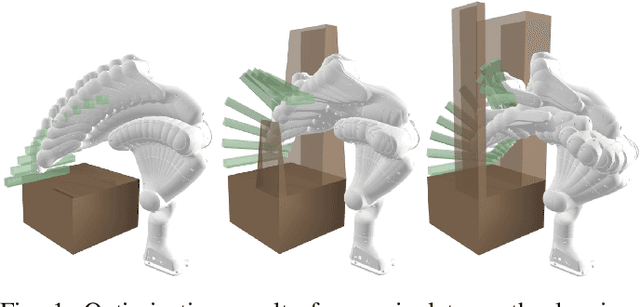
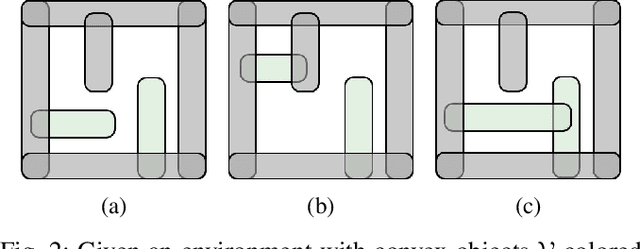

Narrow passage path planning is a prevalent problem from industrial to household sites, often facing difficulties in finding feasible paths or requiring excessive computational resources. Given that deep penetration into the environment can cause optimization failure, we propose a framework to ensure feasibility throughout the process using a series of subproblems tailored for narrow passage problem. We begin by decomposing the environment into convex objects and initializing collision constraints with a subset of these objects. By continuously interpolating the collision constraints through the process of sequentially introducing remaining objects, our proposed framework generates subproblems that guide the optimization toward solving the narrow passage problem. Several examples are presented to demonstrate how the proposed framework addresses narrow passage path planning problems.
Uncertain Pose Estimation during Contact Tasks using Differentiable Contact Features
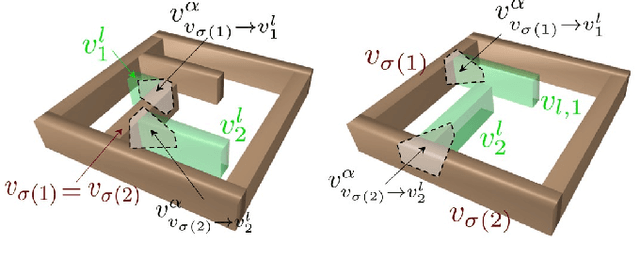
May 26, 2023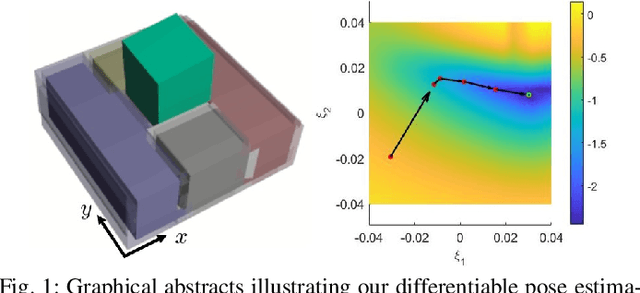
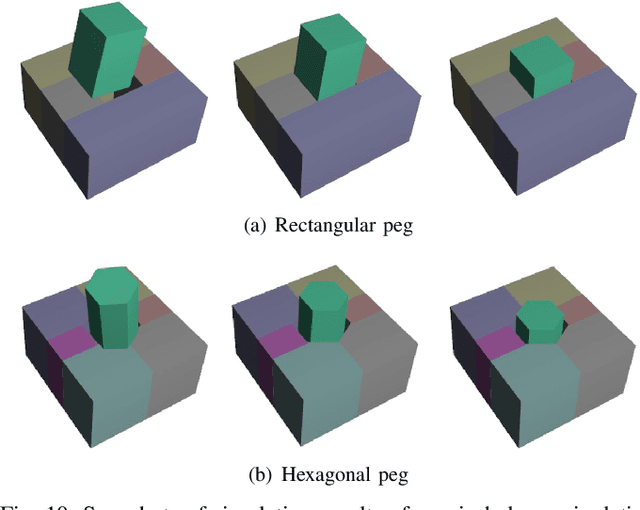
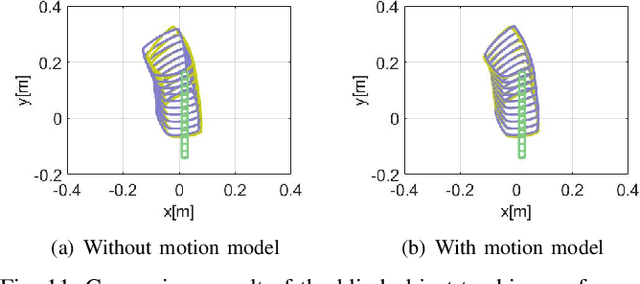

For many robotic manipulation and contact tasks, it is crucial to accurately estimate uncertain object poses, for which certain geometry and sensor information are fused in some optimal fashion. Previous results for this problem primarily adopt sampling-based or end-to-end learning methods, which yet often suffer from the issues of efficiency and generalizability. In this paper, we propose a novel differentiable framework for this uncertain pose estimation during contact, so that it can be solved in an efficient and accurate manner with gradient-based solver. To achieve this, we introduce a new geometric definition that is highly adaptable and capable of providing differentiable contact features. Then we approach the problem from a bi-level perspective and utilize the gradient of these contact features along with differentiable optimization to efficiently solve for the uncertain pose. Several scenarios are implemented to demonstrate how the proposed framework can improve existing methods.
RAMiT: Reciprocal Attention Mixing Transformer for Lightweight Image Restoration
May 22, 2023
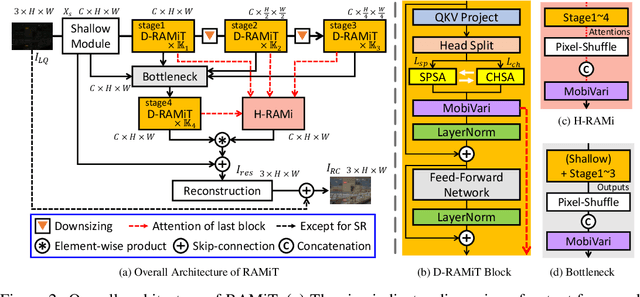
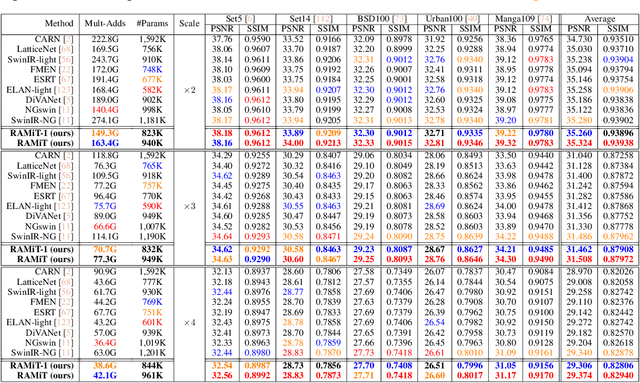
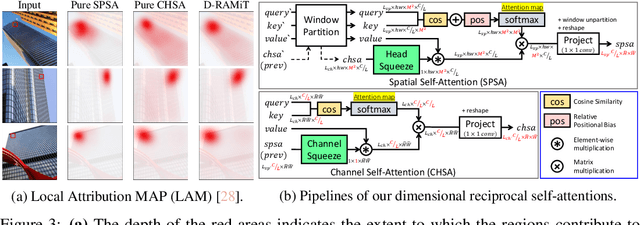
Although many recent works have made advancements in the image restoration (IR) field, they often suffer from an excessive number of parameters. Another issue is that most Transformer-based IR methods focus only on either local or global features, leading to limited receptive fields or deficient parameter issues. To address these problems, we propose a lightweight IR network, Reciprocal Attention Mixing Transformer (RAMiT). It employs our proposed dimensional reciprocal attention mixing Transformer (D-RAMiT) blocks, which compute bi-dimensional (spatial and channel) self-attentions in parallel with different numbers of multi-heads. The bi-dimensional attentions help each other to complement their counterpart's drawbacks and are then mixed. Additionally, we introduce a hierarchical reciprocal attention mixing (H-RAMi) layer that compensates for pixel-level information losses and utilizes semantic information while maintaining an efficient hierarchical structure. Furthermore, we revisit and modify MobileNet V1 and V2 to attach efficient convolutions to our proposed components. The experimental results demonstrate that RAMiT achieves state-of-the-art performance on multiple lightweight IR tasks, including super-resolution, color denoising, grayscale denoising, low-light enhancement, and deraining. Codes will be available soon.
Modular and Parallelizable Multibody Physics Simulation via Subsystem-Based ADMM
Feb 28, 2023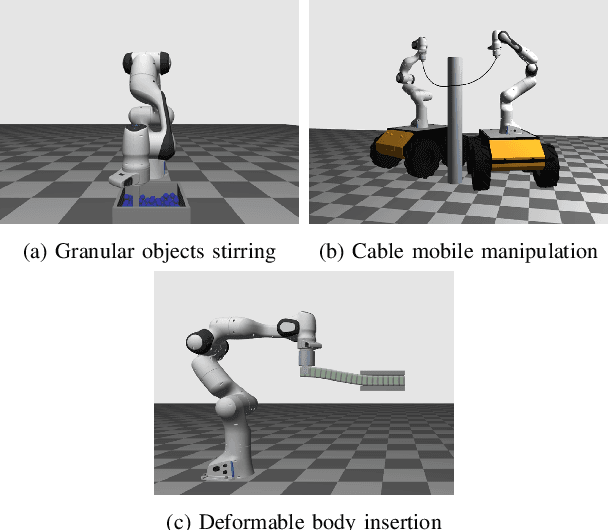
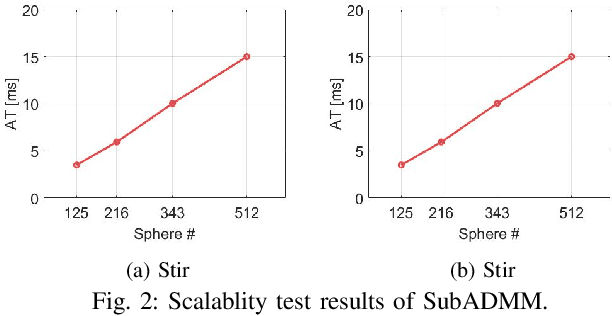
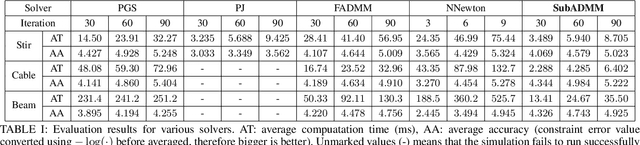
In this paper, we present a new multibody physics simulation framework that utilizes the subsystem-based structure and the Alternating Direction Method of Multiplier (ADMM). The major challenge in simulating complex high degree of freedom systems is a large number of coupled constraints and large-sized matrices. To address this challenge, we first split the multibody into several subsystems and reformulate the dynamics equation into a subsystem perspective based on the structure of their interconnection. Then we utilize ADMM with our novel subsystem-based variable splitting scheme to solve the equation, which allows parallelizable and modular architecture. The resulting algorithm is fast, scalable, versatile, and converges well while maintaining solution consistency. Several illustrative examples are implemented with performance evaluation results showing advantages over other state-of-the-art algorithms.
N-Gram in Swin Transformers for Efficient Lightweight Image Super-Resolution
Nov 21, 2022While some studies have proven that Swin Transformer (SwinT) with window self-attention (WSA) is suitable for single image super-resolution (SR), SwinT ignores the broad regions for reconstructing high-resolution images due to window and shift size. In addition, many deep learning SR methods suffer from intensive computations. To address these problems, we introduce the N-Gram context to the image domain for the first time in history. We define N-Gram as neighboring local windows in SwinT, which differs from text analysis that views N-Gram as consecutive characters or words. N-Grams interact with each other by sliding-WSA, expanding the regions seen to restore degraded pixels. Using the N-Gram context, we propose NGswin, an efficient SR network with SCDP bottleneck taking all outputs of the hierarchical encoder. Experimental results show that NGswin achieves competitive performance while keeping an efficient structure, compared with previous leading methods. Moreover, we also improve other SwinT-based SR methods with the N-Gram context, thereby building an enhanced model: SwinIR-NG. Our improved SwinIR-NG outperforms the current best lightweight SR approaches and establishes state-of-the-art results. Codes will be available soon.
Large-Dimensional Multibody Dynamics Simulation Using Contact Nodalization and Diagonalization
Jan 23, 2022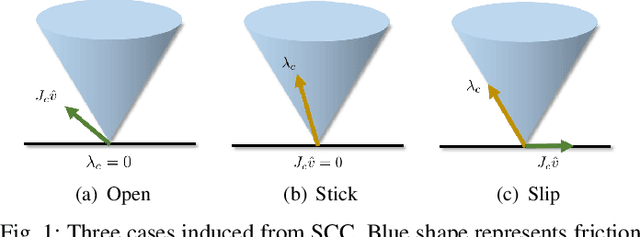
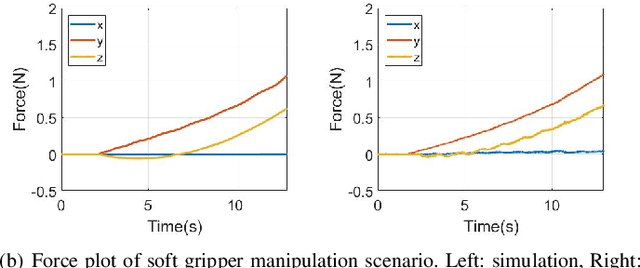
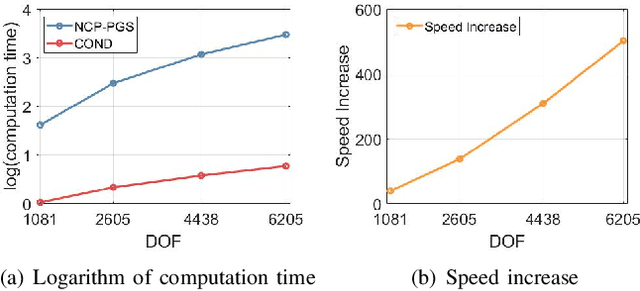
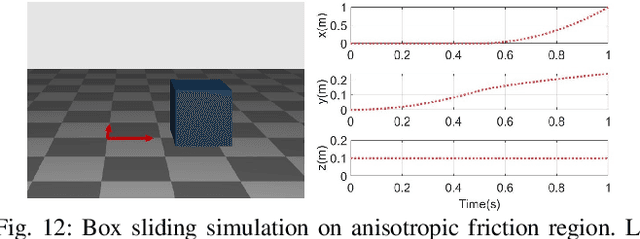
We propose a novel multibody dynamics simulation framework that can efficiently deal with large-dimensionality and complementarity multi-contact conditions. Typical contact simulation approaches perform contact impulse-level fixed-point iteration (IL-FPI), which has high time-complexity from large-size matrix inversion and multiplication, as well as susceptibility to ill-conditioned contact situations. To circumvent this, we propose a novel framework based on velocity-level fixed-point iteration (VL-FPI), which, by utilizing a certain surrogate dynamics and contact nodalization (with virtual nodes), can achieve not only inter-contact decoupling but also their inter-axes decoupling (i.e., contact diagonalization). This then enables us to one-shot/parallel-solve the contact problem during each VL-FPI iteration-loop, while the surrogate dynamics structure allows us to circumvent large-size/dense matrix inversion/multiplication, thereby, significantly speeding up the simulation time with improved convergence property. We theoretically show that the solution of our framework is consistent with that of the original problem and, further, elucidate mathematical conditions for the convergence of our proposed solver. Performance and properties of our proposed simulation framework are also demonstrated and experimentally-validated for various large-dimensional/multi-contact scenarios including deformable objects.
Event-guided Deblurring of Unknown Exposure Time Videos
Dec 17, 2021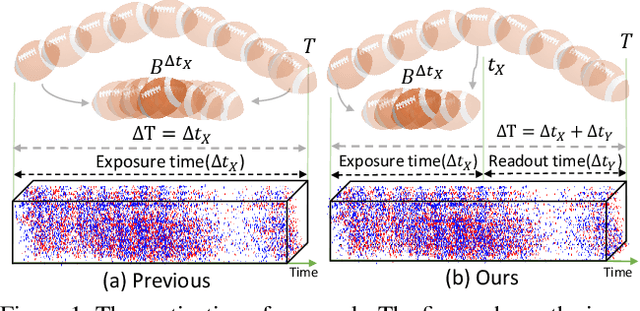

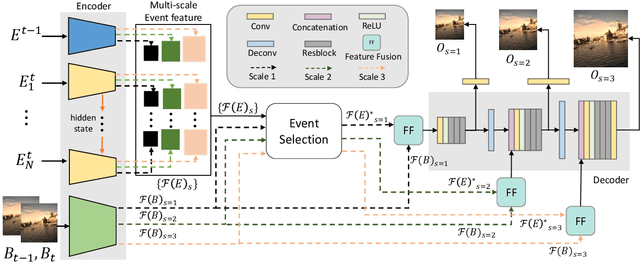
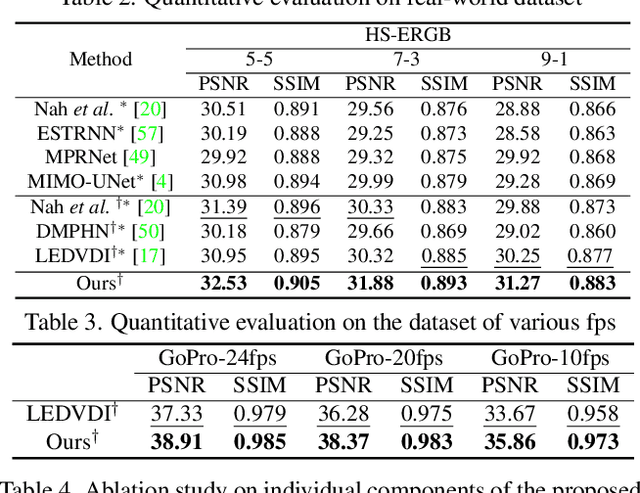
Video deblurring is a highly ill-posed problem due to the loss of motion information in the blur degradation process. Since event cameras can capture apparent motion with a high temporal resolution, several attempts have explored the potential of events for guiding video deblurring. These methods generally assume that the exposure time is the same as the reciprocal of the video frame rate. However,this is not true in real situations, and the exposure time might be unknown and dynamically varies depending on the video shooting environment(e.g., illumination condition). In this paper, we address the event-guided video deblurring assuming dynamically variable unknown exposure time of the frame-based camera. To this end, we first derive a new formulation for event-guided video deblurring by considering the exposure and readout time in the video frame acquisition process. We then propose a novel end-toend learning framework for event-guided video deblurring. In particular, we design a novel Exposure Time-based Event Selection(ETES) module to selectively use event features by estimating the cross-modal correlation between the features from blurred frames and the events. Moreover, we propose a feature fusion module to effectively fuse the selected features from events and blur frames. We conduct extensive experiments on various datasets and demonstrate that our method achieves state-of-the-art performance. Our project code and pretrained models will be available.