 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Spatial Frequency: Pixel-wise Temporal Frequency-based Deepfake Video Detection
Jul 03, 2025We introduce a deepfake video detection approach that exploits pixel-wise temporal inconsistencies, which traditional spatial frequency-based detectors often overlook. Traditional detectors represent temporal information merely by stacking spatial frequency spectra across frames, resulting in the failure to detect temporal artifacts in the pixel plane. Our approach performs a 1D Fourier transform on the time axis for each pixel, extracting features highly sensitive to temporal inconsistencies, especially in areas prone to unnatural movements. To precisely locate regions containing the temporal artifacts, we introduce an attention proposal module trained in an end-to-end manner. Additionally, our joint transformer module effectively integrates pixel-wise temporal frequency features with spatio-temporal context features, expanding the range of detectable forgery artifacts. Our framework represents a significant advancement in deepfake video detection, providing robust performance across diverse and challenging detection scenarios.
Model Merging is Secretly Certifiable: Non-Vacuous Generalisation Bounds for Low-Shot Learning
May 21, 2025Certifying the IID generalisation ability of deep networks is the first of many requirements for trusting AI in high-stakes applications from medicine to security. However, when instantiating generalisation bounds for deep networks it remains challenging to obtain non-vacuous guarantees, especially when applying contemporary large models on the small scale data prevalent in such high-stakes fields. In this paper, we draw a novel connection between a family of learning methods based on model fusion and generalisation certificates, and surprisingly show that with minor adjustment several existing learning strategies already provide non-trivial generalisation guarantees. Essentially, by focusing on data-driven learning of downstream tasks by fusion rather than fine-tuning, the certified generalisation gap becomes tiny and independent of the base network size, facilitating its certification. Our results show for the first time non-trivial generalisation guarantees for learning with as low as 100 examples, while using vision models such as VIT-B and language models such as mistral-7B. This observation is significant as it has immediate implications for facilitating the certification of existing systems as trustworthy, and opens up new directions for research at the intersection of practice and theory.
Future-Proof Yourself: An AI Era Survival Guide
Apr 06, 2025Future-Proof Yourself is a practical guide that helps readers navigate the fast-changing world of artificial intelligence in everyday life. The book begins by explaining how computers learn from data in simple, relatable terms, and gradually introduces the methods used in modern AI. It shows how basic ideas in machine learning evolve into advanced systems that can recognize images, understand language, and even make decisions. The guide also reviews the history of AI and highlights the major breakthroughs that have shaped its growth. Looking ahead, the book explores emerging trends such as the integration of AI with digital twins, wearable devices, and virtual environments. Designed for a general audience, the text avoids heavy technical jargon and presents complex ideas in clear, straightforward language so that anyone can gain a solid understanding of the technology that is set to transform our future.
Advancing ALS Applications with Large-Scale Pre-training: Dataset Development and Downstream Assessment
Jan 09, 2025



The pre-training and fine-tuning paradigm has revolutionized satellite remote sensing applications. However, this approach remains largely underexplored for airborne laser scanning (ALS), an important technology for applications such as forest management and urban planning. In this study, we address this gap by constructing a large-scale ALS point cloud dataset and evaluating its impact on downstream applications. Our dataset comprises ALS point clouds collected across the contiguous United States, provided by the United States Geological Survey's 3D Elevation Program. To ensure efficient data collection while capturing diverse land cover and terrain types, we introduce a geospatial sampling method that selects point cloud tiles based on land cover maps and digital elevation models. As a baseline self-supervised learning model, we adopt BEV-MAE, a state-of-the-art masked autoencoder for 3D outdoor point clouds, and pre-train it on the constructed dataset. The pre-trained models are subsequently fine-tuned for downstream tasks, including tree species classification, terrain scene recognition, and point cloud semantic segmentation. Our results show that the pre-trained models significantly outperform their scratch counterparts across all downstream tasks, demonstrating the transferability of the representations learned from the proposed dataset. Furthermore, we observe that scaling the dataset using our geospatial sampling method consistently enhances performance, whereas pre-training on datasets constructed with random sampling fails to achieve similar improvements. These findings highlight the utility of the constructed dataset and the effectiveness of our sampling strategy in the pre-training and fine-tuning paradigm. The source code and pre-trained models will be made publicly available at \url{https://github.com/martianxiu/ALS_pretraining}.
A 0.65-pJ/bit 3.6-TB/s/mm I/O Interface with XTalk Minimizing Affine Signaling for Next-Generation HBM with High Interconnect Density
Apr 08, 2024



This paper presents an I/O interface with Xtalk Minimizing Affine Signaling (XMAS), which is designed to support high-speed data transmission in die-to-die communication over silicon interposers or similar high-density interconnects susceptible to crosstalk. The operating principles of XMAS are elucidated through rigorous analyses, and its advantages over existing signaling are validated through numerical experiments. XMAS not only demonstrates exceptional crosstalk removing capabilities but also exhibits robustness against noise, especially simultaneous switching noise. Fabricated in a 28-nm CMOS process, the prototype XMAS transceiver achieves an edge density of 3.6TB/s/mm and an energy efficiency of 0.65pJ/b. Compared to the single-ended signaling, the crosstalk-induced peak-to-peak jitter of the received eye with XMAS is reduced by 75% at 10GS/s/pin data rate, and the horizontal eye opening extends to 0.2UI at a bit error rate < 10$^{-12}$.
OurDB: Ouroboric Domain Bridging for Multi-Target Domain Adaptive Semantic Segmentation
Mar 18, 2024

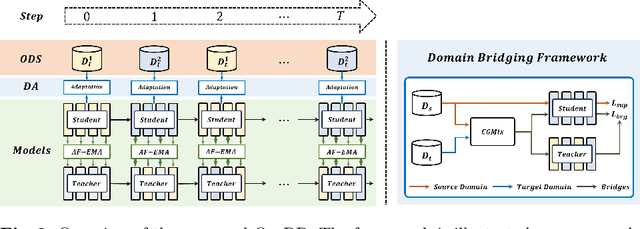

Multi-target domain adaptation (MTDA) for semantic segmentation poses a significant challenge, as it involves multiple target domains with varying distributions. The goal of MTDA is to minimize the domain discrepancies among a single source and multi-target domains, aiming to train a single model that excels across all target domains. Previous MTDA approaches typically employ multiple teacher architectures, where each teacher specializes in one target domain to simplify the task. However, these architectures hinder the student model from fully assimilating comprehensive knowledge from all target-specific teachers and escalate training costs with increasing target domains. In this paper, we propose an ouroboric domain bridging (OurDB) framework, offering an efficient solution to the MTDA problem using a single teacher architecture. This framework dynamically cycles through multiple target domains, aligning each domain individually to restrain the biased alignment problem, and utilizes Fisher information to minimize the forgetting of knowledge from previous target domains. We also propose a context-guided class-wise mixup (CGMix) that leverages contextual information tailored to diverse target contexts in MTDA. Experimental evaluations conducted on four urban driving datasets (i.e., GTA5, Cityscapes, IDD, and Mapillary) demonstrate the superiority of our method over existing state-of-the-art approaches.
D3T: Distinctive Dual-Domain Teacher Zigzagging Across RGB-Thermal Gap for Domain-Adaptive Object Detection
Mar 14, 2024
Domain adaptation for object detection typically entails transferring knowledge from one visible domain to another visible domain. However, there are limited studies on adapting from the visible to the thermal domain, because the domain gap between the visible and thermal domains is much larger than expected, and traditional domain adaptation can not successfully facilitate learning in this situation. To overcome this challenge, we propose a Distinctive Dual-Domain Teacher (D3T) framework that employs distinct training paradigms for each domain. Specifically, we segregate the source and target training sets for building dual-teachers and successively deploy exponential moving average to the student model to individual teachers of each domain. The framework further incorporates a zigzag learning method between dual teachers, facilitating a gradual transition from the visible to thermal domains during training. We validate the superiority of our method through newly designed experimental protocols with well-known thermal datasets, i.e., FLIR and KAIST. Source code is available at https://github.com/EdwardDo69/D3T .
Exploiting Style Latent Flows for Generalizing Deepfake Detection Video Detection
Mar 11, 2024



This paper presents a new approach for the detection of fake videos, based on the analysis of style latent vectors and their abnormal behavior in temporal changes in the generated videos. We discovered that the generated facial videos suffer from the temporal distinctiveness in the temporal changes of style latent vectors, which are inevitable during the generation of temporally stable videos with various facial expressions and geometric transformations. Our framework utilizes the StyleGRU module, trained by contrastive learning, to represent the dynamic properties of style latent vectors. Additionally, we introduce a style attention module that integrates StyleGRU-generated features with content-based features, enabling the detection of visual and temporal artifacts. We demonstrate our approach across various benchmark scenarios in deepfake detection, showing its superiority in cross-dataset and cross-manipulation scenarios. Through further analysis, we also validate the importance of using temporal changes of style latent vectors to improve the generality of deepfake video detection.
NICE: CVPR 2023 Challenge on Zero-shot Image Captioning
Sep 11, 2023



In this report, we introduce NICE (New frontiers for zero-shot Image Captioning Evaluation) project and share the results and outcomes of 2023 challenge. This project is designed to challenge the computer vision community to develop robust image captioning models that advance the state-of-the-art both in terms of accuracy and fairness. Through the challenge, the image captioning models were tested using a new evaluation dataset that includes a large variety of visual concepts from many domains. There was no specific training data provided for the challenge, and therefore the challenge entries were required to adapt to new types of image descriptions that had not been seen during training. This report includes information on the newly proposed NICE dataset, evaluation methods, challenge results, and technical details of top-ranking entries. We expect that the outcomes of the challenge will contribute to the improvement of AI models on various vision-language tasks.
RAMiT: Reciprocal Attention Mixing Transformer for Lightweight Image Restoration
May 22, 2023
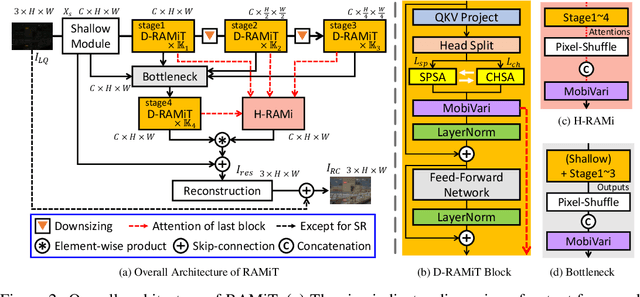
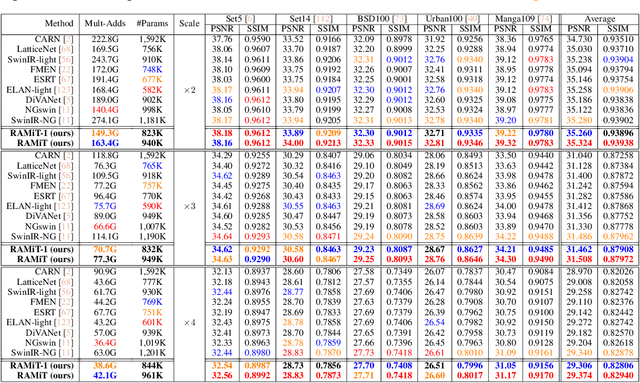
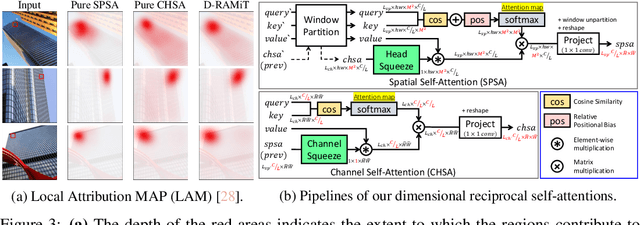
Although many recent works have made advancements in the image restoration (IR) field, they often suffer from an excessive number of parameters. Another issue is that most Transformer-based IR methods focus only on either local or global features, leading to limited receptive fields or deficient parameter issues. To address these problems, we propose a lightweight IR network, Reciprocal Attention Mixing Transformer (RAMiT). It employs our proposed dimensional reciprocal attention mixing Transformer (D-RAMiT) blocks, which compute bi-dimensional (spatial and channel) self-attentions in parallel with different numbers of multi-heads. The bi-dimensional attentions help each other to complement their counterpart's drawbacks and are then mixed. Additionally, we introduce a hierarchical reciprocal attention mixing (H-RAMi) layer that compensates for pixel-level information losses and utilizes semantic information while maintaining an efficient hierarchical structure. Furthermore, we revisit and modify MobileNet V1 and V2 to attach efficient convolutions to our proposed components. The experimental results demonstrate that RAMiT achieves state-of-the-art performance on multiple lightweight IR tasks, including super-resolution, color denoising, grayscale denoising, low-light enhancement, and deraining. Codes will be available soon.