 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 4x32Gb/s 1.8pJ/bit Collaborative Baud-Rate CDR with Background Eye-Climbing Algorithm and Low-Power Global Clock Distribution
Apr 10, 2024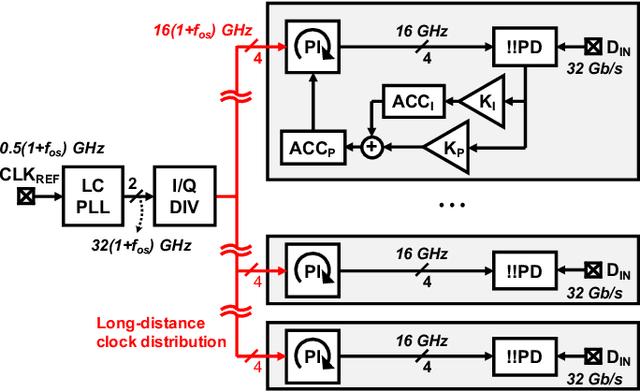
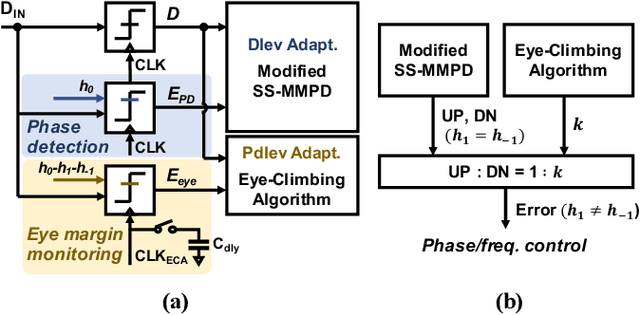
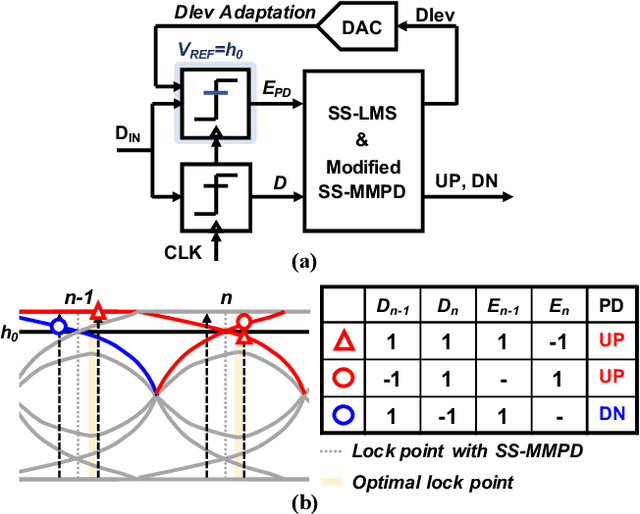
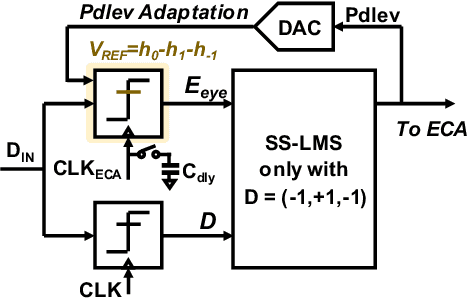
This paper presents design techniques for an energy-efficient multi-lane receiver (RX) with baud-rate clock and data recovery (CDR), which is essential for high-throughput low-latency communication in high-performance computing systems. The proposed low-power global clock distribution not only significantly reduces power consumption across multi-lane RXs but is capable of compensating for the frequency offset without any phase interpolators. To this end, a fractional divider controlled by CDR is placed close to the global phase locked loop. Moreover, in order to address the sub-optimal lock point of conventional baud-rate phase detectors, the proposed CDR employs a background eye-climbing algorithm, which optimizes the sampling phase and maximizes the vertical eye margin (VEM). Fabricated in a 28nm CMOS process, the proposed 4x32Gb/s RX shows a low integrated fractional spur of -40.4dBc at a 2500ppm frequency offset. Furthermore, it improves bit-error-rate performance by increasing the VEM by 17%. The entire RX achieves the energy efficiency of 1.8pJ/bit with the aggregate data rate of 128Gb/s.
A 0.65-pJ/bit 3.6-TB/s/mm I/O Interface with XTalk Minimizing Affine Signaling for Next-Generation HBM with High Interconnect Density
Apr 08, 2024



This paper presents an I/O interface with Xtalk Minimizing Affine Signaling (XMAS), which is designed to support high-speed data transmission in die-to-die communication over silicon interposers or similar high-density interconnects susceptible to crosstalk. The operating principles of XMAS are elucidated through rigorous analyses, and its advantages over existing signaling are validated through numerical experiments. XMAS not only demonstrates exceptional crosstalk removing capabilities but also exhibits robustness against noise, especially simultaneous switching noise. Fabricated in a 28-nm CMOS process, the prototype XMAS transceiver achieves an edge density of 3.6TB/s/mm and an energy efficiency of 0.65pJ/b. Compared to the single-ended signaling, the crosstalk-induced peak-to-peak jitter of the received eye with XMAS is reduced by 75% at 10GS/s/pin data rate, and the horizontal eye opening extends to 0.2UI at a bit error rate < 10$^{-12}$.
NeuralEQ: Neural-Network-Based Equalizer for High-Speed Wireline Communication
Aug 04, 2023



With the growing demand for high-bandwidth applications like video streaming and cloud services, the data transfer rates required for wireline communication keeps increasing, making the channel loss a major obstacle in achieving low bit error rate (BER). Equalization techniques such as feed-forward equalizer (FFE) and decision feedback equalizer (DFE) are commonly used to compensate for channel loss in wireline communication, but they have limitations in terms of noise boosting and timing constraints. On the other hand, the forward-backward algorithm can achieve better BER performance, but its high complexity makes it impractical for wireline communication. In this work, we propose a novel neural network, NeuralEQ, that effectively mimics the forward-backward algorithm and performs better than FFE and DFE while reducing complexity of the forward-backward algorithm. Performance of NeuralEQ is verified through simulations using real channels.
A Context-Aware Readout System for Sparse Touch Sensing Array Using Ultra-low-power Always-on Event Detection
Mar 13, 2022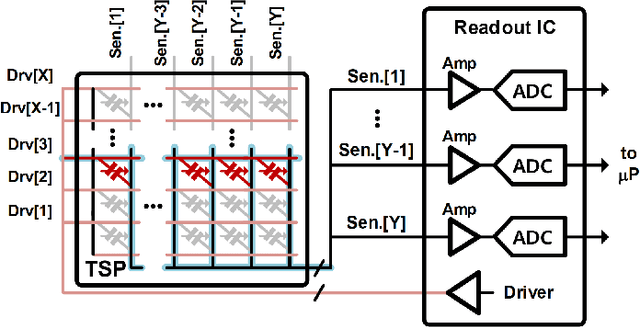
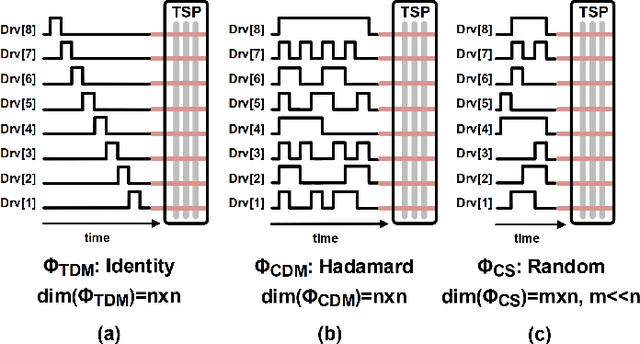
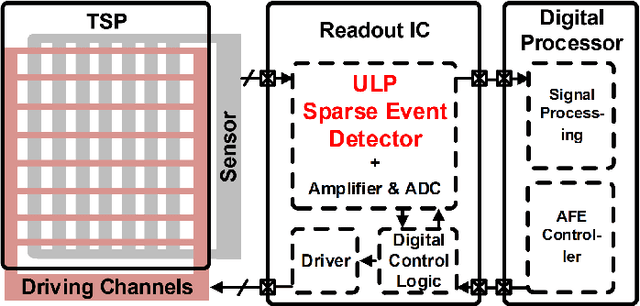
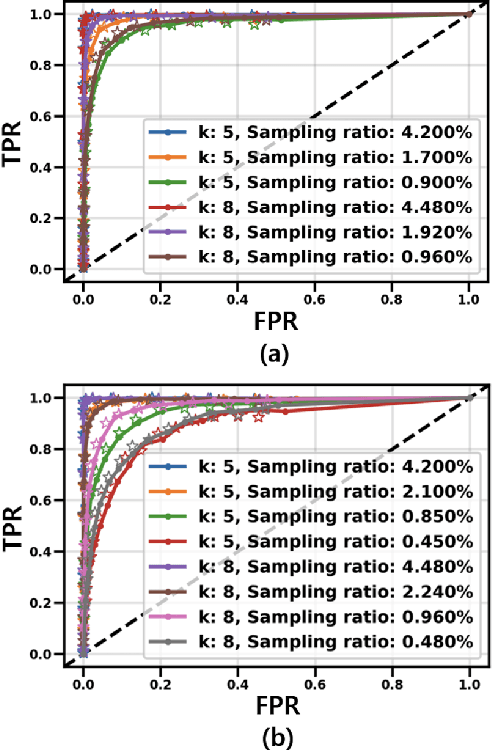
Increasing demand for larger touch screen panels (TSPs) places more energy burden to mobile systems with conventional sensing methods. To mitigate this problem, taking advantage of the touch event sparsity, this paper proposes a novel TSP readout system that can obtain huge energy saving by turning off the readout circuits when none of the sensors are activated. To this end, a novel ultra-low-power always-on event and region of interest detection based on lightweight compressed sensing is proposed. Exploiting the proposed event detector, the context-aware TSP readout system, which can improve the energy efficiency by up to 40x, is presented.
Energy-Efficient High-Accuracy Spiking Neural Network Inference Using Time-Domain Neurons
Feb 04, 2022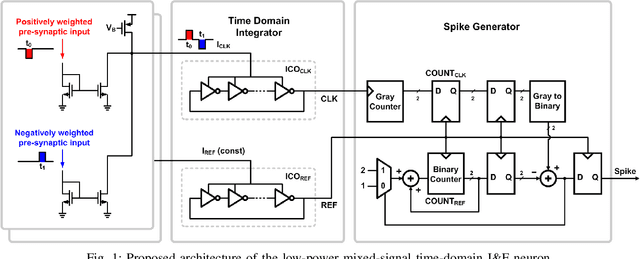
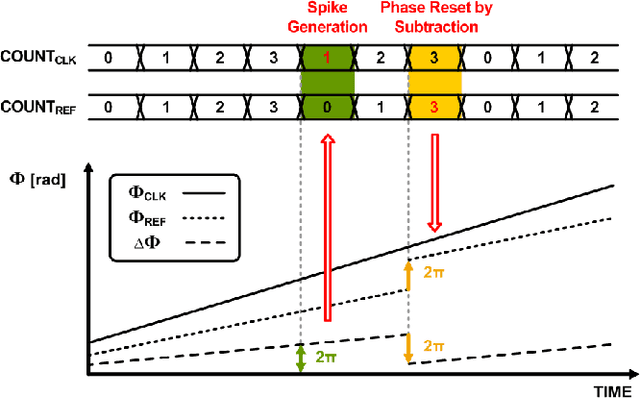
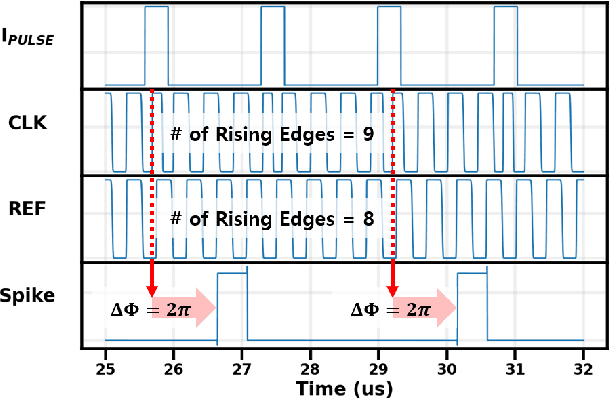
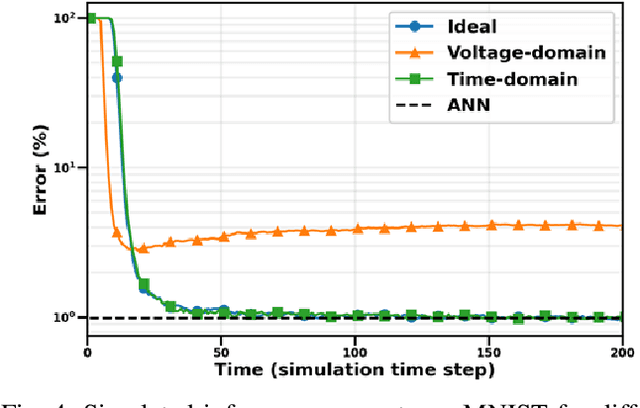
Due to the limitations of realizing artificial neural networks on prevalent von Neumann architectures, recent studies have presented neuromorphic systems based on spiking neural networks (SNNs) to reduce power and computational cost. However, conventional analog voltage-domain integrate-and-fire (I&F) neuron circuits, based on either current mirrors or op-amps, pose serious issues such as nonlinearity or high power consumption, thereby degrading either inference accuracy or energy efficiency of the SNN. To achieve excellent energy efficiency and high accuracy simultaneously, this paper presents a low-power highly linear time-domain I&F neuron circuit. Designed and simulated in a 28nm CMOS process, the proposed neuron leads to more than 4.3x lower error rate on the MNIST inference over the conventional current-mirror-based neurons. In addition, the power consumed by the proposed neuron circuit is simulated to be 0.230uW per neuron, which is orders of magnitude lower than the existing voltage-domain neurons.
Improving Spiking Neural Network Accuracy Using Time-based Neurons
Jan 05, 2022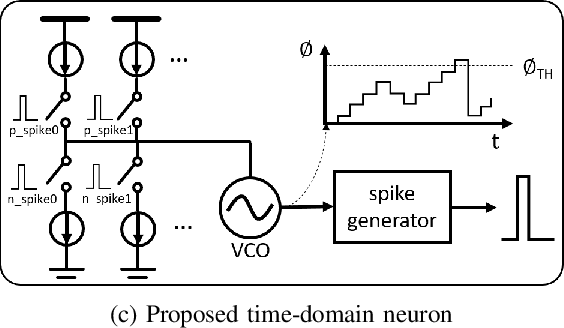
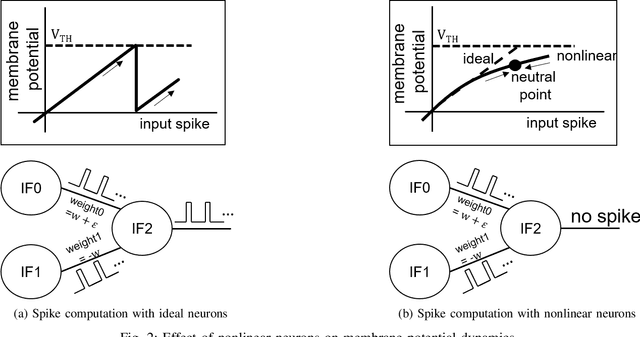
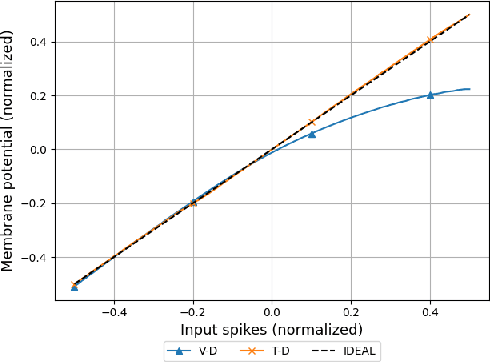
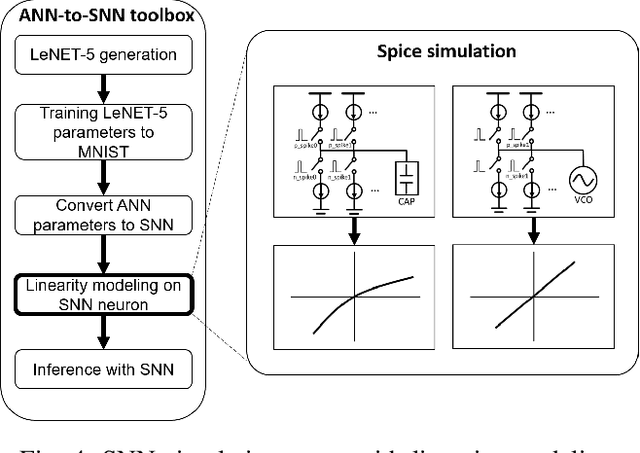
Due to the fundamental limit to reducing power consumption of running deep learning models on von-Neumann architecture, research on neuromorphic computing systems based on low-power spiking neural networks using analog neurons is in the spotlight. In order to integrate a large number of neurons, neurons need to be designed to occupy a small area, but as technology scales down, analog neurons are difficult to scale, and they suffer from reduced voltage headroom/dynamic range and circuit nonlinearities. In light of this, this paper first models the nonlinear behavior of existing current-mirror-based voltage-domain neurons designed in a 28nm process, and show SNN inference accuracy can be severely degraded by the effect of neuron's nonlinearity. Then, to mitigate this problem, we propose a novel neuron, which processes incoming spikes in the time domain and greatly improves the linearity, thereby improving the inference accuracy compared to the existing voltage-domain neuron. Tested on the MNIST dataset, the inference error rate of the proposed neuron differs by less than 0.1% from that of the ideal neuron.