 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 0.65-pJ/bit 3.6-TB/s/mm I/O Interface with XTalk Minimizing Affine Signaling for Next-Generation HBM with High Interconnect Density
Apr 08, 2024



This paper presents an I/O interface with Xtalk Minimizing Affine Signaling (XMAS), which is designed to support high-speed data transmission in die-to-die communication over silicon interposers or similar high-density interconnects susceptible to crosstalk. The operating principles of XMAS are elucidated through rigorous analyses, and its advantages over existing signaling are validated through numerical experiments. XMAS not only demonstrates exceptional crosstalk removing capabilities but also exhibits robustness against noise, especially simultaneous switching noise. Fabricated in a 28-nm CMOS process, the prototype XMAS transceiver achieves an edge density of 3.6TB/s/mm and an energy efficiency of 0.65pJ/b. Compared to the single-ended signaling, the crosstalk-induced peak-to-peak jitter of the received eye with XMAS is reduced by 75% at 10GS/s/pin data rate, and the horizontal eye opening extends to 0.2UI at a bit error rate < 10$^{-12}$.
A$^3$: Accelerating Attention Mechanisms in Neural Networks with Approximation
Feb 22, 2020
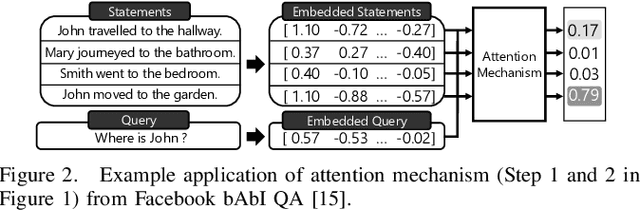
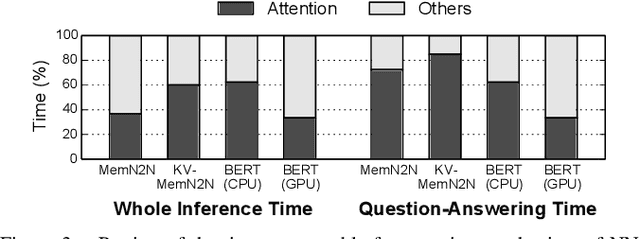

With the increasing computational demands of neural networks, many hardware accelerators for the neural networks have been proposed. Such existing neural network accelerators often focus on popular neural network types such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs); however, not much attention has been paid to attention mechanisms, an emerging neural network primitive that enables neural networks to retrieve most relevant information from a knowledge-base, external memory, or past states. The attention mechanism is widely adopted by many state-of-the-art neural networks for computer vision, natural language processing, and machine translation, and accounts for a large portion of total execution time. We observe today's practice of implementing this mechanism using matrix-vector multiplication is suboptimal as the attention mechanism is semantically a content-based search where a large portion of computations ends up not being used. Based on this observation, we design and architect A3, which accelerates attention mechanisms in neural networks with algorithmic approximation and hardware specialization. Our proposed accelerator achieves multiple orders of magnitude improvement in energy efficiency (performance/watt) as well as substantial speedup over the state-of-the-art conventional hardware.