 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAMiT: Reciprocal Attention Mixing Transformer for Lightweight Image Restoration
May 22, 2023
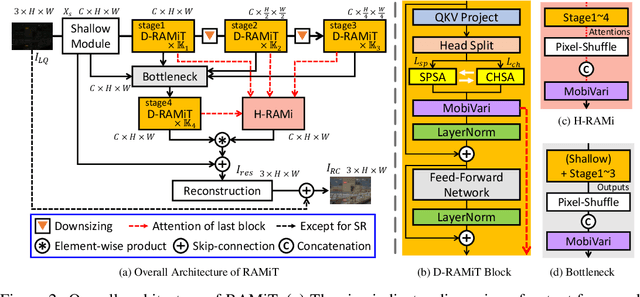
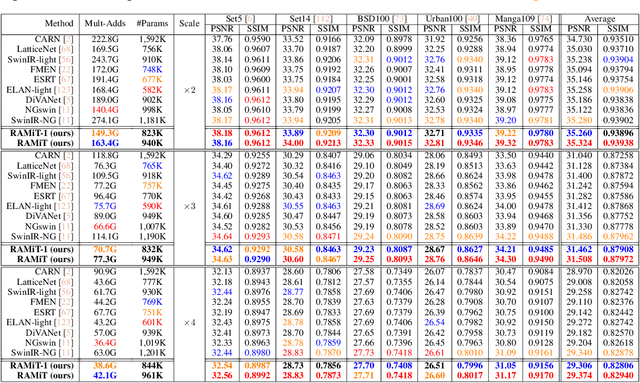
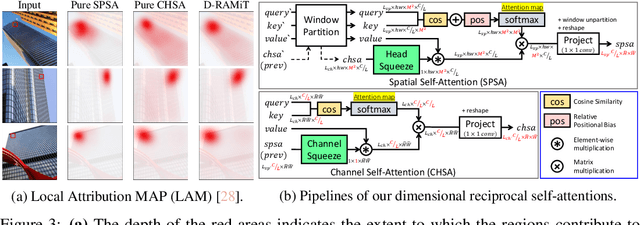
Although many recent works have made advancements in the image restoration (IR) field, they often suffer from an excessive number of parameters. Another issue is that most Transformer-based IR methods focus only on either local or global features, leading to limited receptive fields or deficient parameter issues. To address these problems, we propose a lightweight IR network, Reciprocal Attention Mixing Transformer (RAMiT). It employs our proposed dimensional reciprocal attention mixing Transformer (D-RAMiT) blocks, which compute bi-dimensional (spatial and channel) self-attentions in parallel with different numbers of multi-heads. The bi-dimensional attentions help each other to complement their counterpart's drawbacks and are then mixed. Additionally, we introduce a hierarchical reciprocal attention mixing (H-RAMi) layer that compensates for pixel-level information losses and utilizes semantic information while maintaining an efficient hierarchical structure. Furthermore, we revisit and modify MobileNet V1 and V2 to attach efficient convolutions to our proposed components. The experimental results demonstrate that RAMiT achieves state-of-the-art performance on multiple lightweight IR tasks, including super-resolution, color denoising, grayscale denoising, low-light enhancement, and deraining. Codes will be available soon.
Exploration of Lightweight Single Image Denoising with Transformers and Truly Fair Training
Apr 04, 2023



As multimedia content often contains noise from intrinsic defects of digital devices, image denoising is an important step for high-level vision recognition tasks. Although several studies have developed the denoising field employing advanced Transformers, these networks are too momory-intensive for real-world applications. Additionally, there is a lack of research on lightweight denosing (LWDN) with Transformers. To handle this, this work provides seven comparative baseline Transformers for LWDN, serving as a foundation for future research. We also demonstrate the parts of randomly cropped patches significantly affect the denoising performances during training. While previous studies have overlooked this aspect, we aim to train our baseline Transformers in a truly fair manner. Furthermore, we conduct empirical analyses of various components to determine the key considerations for constructing LWDN Transformers. Codes are available at https://github.com/rami0205/LWDN.