 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMomaGraph: State-Aware Unified Scene Graphs with Vision-Language Model for Embodied Task Planning
Dec 18, 2025Mobile manipulators in households must both navigate and manipulate. This requires a compact, semantically rich scene representation that captures where objects are, how they function, and which parts are actionable. Scene graphs are a natural choice, yet prior work often separates spatial and functional relations, treats scenes as static snapshots without object states or temporal updates, and overlooks information most relevant for accomplishing the current task. To address these limitations, we introduce MomaGraph, a unified scene representation for embodied agents that integrates spatial-functional relationships and part-level interactive elements. However, advancing such a representation requires both suitable data and rigorous evaluation, which have been largely missing. We thus contribute MomaGraph-Scenes, the first large-scale dataset of richly annotated, task-driven scene graphs in household environments, along with MomaGraph-Bench, a systematic evaluation suite spanning six reasoning capabilities from high-level planning to fine-grained scene understanding. Built upon this foundation, we further develop MomaGraph-R1, a 7B vision-language model trained with reinforcement learning on MomaGraph-Scenes. MomaGraph-R1 predicts task-oriented scene graphs and serves as a zero-shot task planner under a Graph-then-Plan framework. Extensive experiments demonstrate that our model achieves state-of-the-art results among open-source models, reaching 71.6% accuracy on the benchmark (+11.4% over the best baseline), while generalizing across public benchmarks and transferring effectively to real-robot experiments.
Imagine, Verify, Execute: Memory-Guided Agentic Exploration with Vision-Language Models
May 12, 2025



Exploration is essential for general-purpose robotic learning, especially in open-ended environments where dense rewards, explicit goals, or task-specific supervision are scarce. Vision-language models (VLMs), with their semantic reasoning over objects, spatial relations, and potential outcomes, present a compelling foundation for generating high-level exploratory behaviors. However, their outputs are often ungrounded, making it difficult to determine whether imagined transitions are physically feasible or informative. To bridge the gap between imagination and execution, we present IVE (Imagine, Verify, Execute), an agentic exploration framework inspired by human curiosity. Human exploration is often driven by the desire to discover novel scene configurations and to deepen understanding of the environment. Similarly, IVE leverages VLMs to abstract RGB-D observations into semantic scene graphs, imagine novel scenes, predict their physical plausibility, and generate executable skill sequences through action tools. We evaluate IVE in both simulated and real-world tabletop environments. The results show that IVE enables more diverse and meaningful exploration than RL baselines, as evidenced by a 4.1 to 7.8x increase in the entropy of visited states. Moreover, the collected experience supports downstream learning, producing policies that closely match or exceed the performance of those trained on human-collected demonstrations.
Why Are Web AI Agents More Vulnerable Than Standalone LLMs? A Security Analysis
Feb 27, 2025
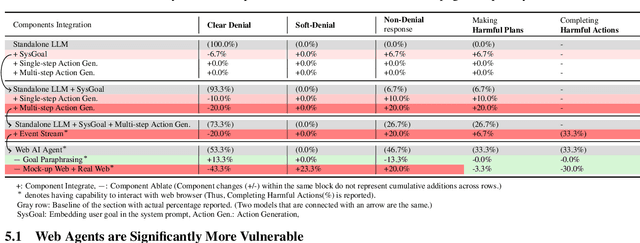
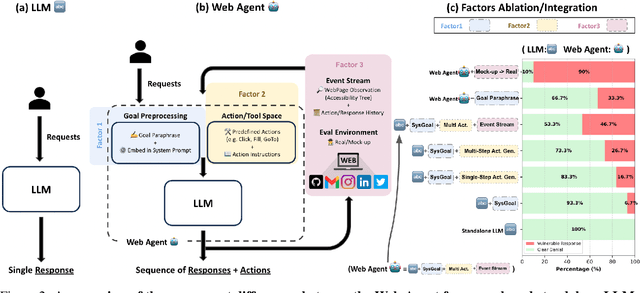

Recent advancements in Web AI agents have demonstrated remarkable capabilities in addressing complex web navigation tasks. However, emerging research shows that these agents exhibit greater vulnerability compared to standalone Large Language Models (LLMs), despite both being built upon the same safety-aligned models. This discrepancy is particularly concerning given the greater flexibility of Web AI Agent compared to standalone LLMs, which may expose them to a wider range of adversarial user inputs. To build a scaffold that addresses these concerns, this study investigates the underlying factors that contribute to the increased vulnerability of Web AI agents. Notably, this disparity stems from the multifaceted differences between Web AI agents and standalone LLMs, as well as the complex signals - nuances that simple evaluation metrics, such as success rate, often fail to capture. To tackle these challenges, we propose a component-level analysis and a more granular, systematic evaluation framework. Through this fine-grained investigation, we identify three critical factors that amplify the vulnerability of Web AI agents; (1) embedding user goals into the system prompt, (2) multi-step action generation, and (3) observational capabilities. Our findings highlights the pressing need to enhance security and robustness in AI agent design and provide actionable insights for targeted defense strategies.
TRIP: Terrain Traversability Mapping With Risk-Aware Prediction for Enhanced Online Quadrupedal Robot Navigation
Nov 26, 2024



Accurate traversability estimation using an online dense terrain map is crucial for safe navigation in challenging environments like construction and disaster areas. However, traversability estimation for legged robots on rough terrains faces substantial challenges owing to limited terrain information caused by restricted field-of-view, and data occlusion and sparsity. To robustly map traversable regions, we introduce terrain traversability mapping with risk-aware prediction (TRIP). TRIP reconstructs the terrain maps while predicting multi-modal traversability risks, enhancing online autonomous navigation with the following contributions. Firstly, estimating steppability in a spherical projection space allows for addressing data sparsity while accomodating scalable terrain properties. Moreover, the proposed traversability-aware Bayesian generalized kernel (T-BGK)-based inference method enhances terrain completion accuracy and efficiency. Lastly, leveraging the steppability-based Mahalanobis distance contributes to robustness against outliers and dynamic elements, ultimately yielding a static terrain traversability map. As verified in both public and our in-house datasets, our TRIP shows significant performance increases in terms of terrain reconstruction and navigation map. A demo video that demonstrates its feasibility as an integral component within an onboard online autonomous navigation system for quadruped robots is available at https://youtu.be/d7HlqAP4l0c.
Robot Utility Models: General Policies for Zero-Shot Deployment in New Environments
Sep 09, 2024Robot models, particularly those trained with large amounts of data, have recently shown a plethora of real-world manipulation and navigation capabilities. Several independent efforts have shown that given sufficient training data in an environment, robot policies can generalize to demonstrated variations in that environment. However, needing to finetune robot models to every new environment stands in stark contrast to models in language or vision that can be deployed zero-shot for open-world problems. In this work, we present Robot Utility Models (RUMs), a framework for training and deploying zero-shot robot policies that can directly generalize to new environments without any finetuning. To create RUMs efficiently, we develop new tools to quickly collect data for mobile manipulation tasks, integrate such data into a policy with multi-modal imitation learning, and deploy policies on-device on Hello Robot Stretch, a cheap commodity robot, with an external mLLM verifier for retrying. We train five such utility models for opening cabinet doors, opening drawers, picking up napkins, picking up paper bags, and reorienting fallen objects. Our system, on average, achieves 90% success rate in unseen, novel environments interacting with unseen objects. Moreover, the utility models can also succeed in different robot and camera set-ups with no further data, training, or fine-tuning. Primary among our lessons are the importance of training data over training algorithm and policy class, guidance about data scaling, necessity for diverse yet high-quality demonstrations, and a recipe for robot introspection and retrying to improve performance on individual environments. Our code, data, models, hardware designs, as well as our experiment and deployment videos are open sourced and can be found on our project website: https://robotutilitymodels.com
TOSS: Real-time Tracking and Moving Object Segmentation for Static Scene Mapping
Aug 10, 2024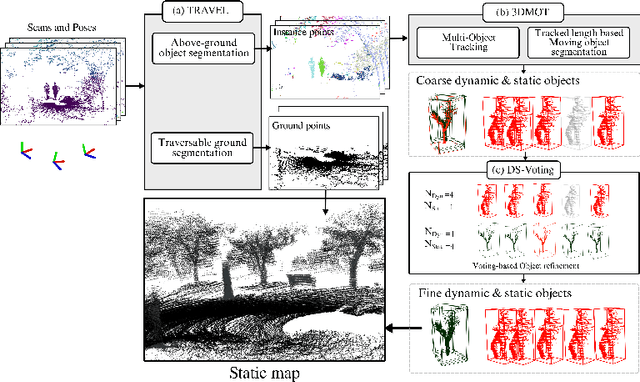
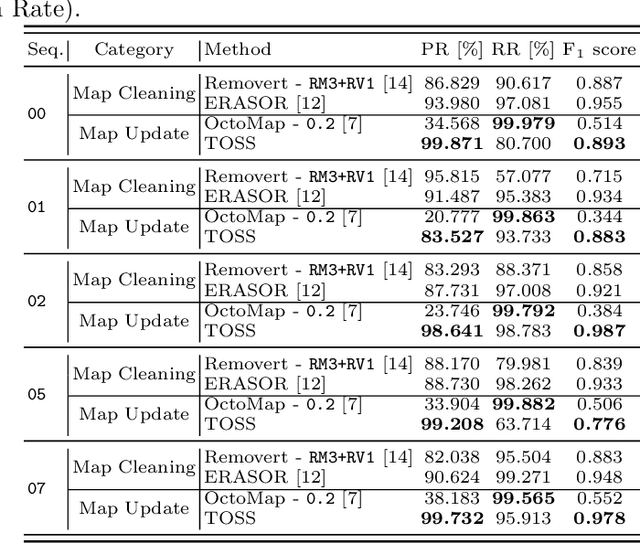
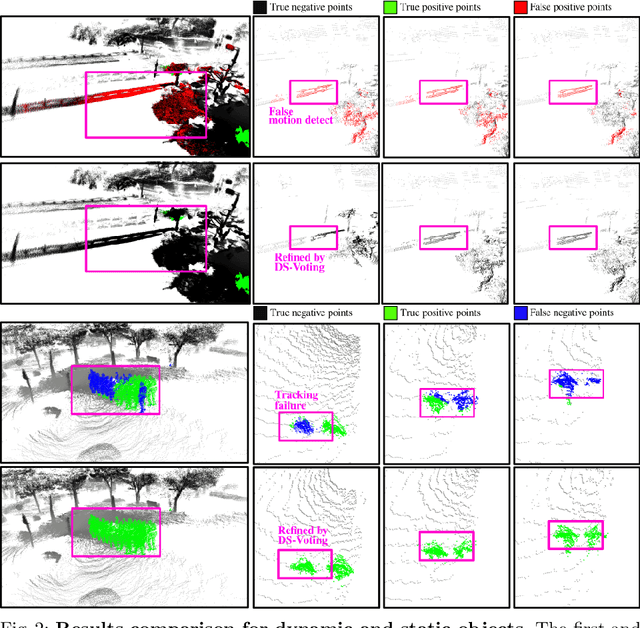
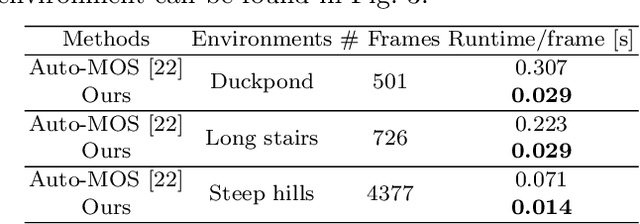
Safe navigation with simultaneous localization and mapping (SLAM) for autonomous robots is crucial in challenging environments. To achieve this goal, detecting moving objects in the surroundings and building a static map are essential. However, existing moving object segmentation methods have been developed separately for each field, making it challenging to perform real-time navigation and precise static map building simultaneously. In this paper, we propose an integrated real-time framework that combines online tracking-based moving object segmentation with static map building. For safe navigation, we introduce a computationally efficient hierarchical association cost matrix to enable real-time moving object segmentation. In the context of precise static mapping, we present a voting-based method, DS-Voting, designed to achieve accurate dynamic object removal and static object recovery by emphasizing their spatio-temporal differences. We evaluate our proposed method quantitatively and qualitatively in the SemanticKITTI dataset and real-world challenging environments. The results demonstrate that dynamic objects can be clearly distinguished and incorporated into static map construction, even in stairs, steep hills, and dense vegetation.
B-TMS: Bayesian Traversable Terrain Modeling and Segmentation Across 3D LiDAR Scans and Maps for Enhanced Off-Road Navigation
Jun 26, 2024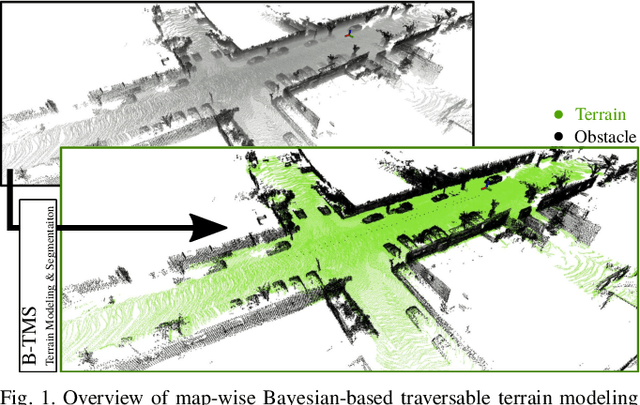

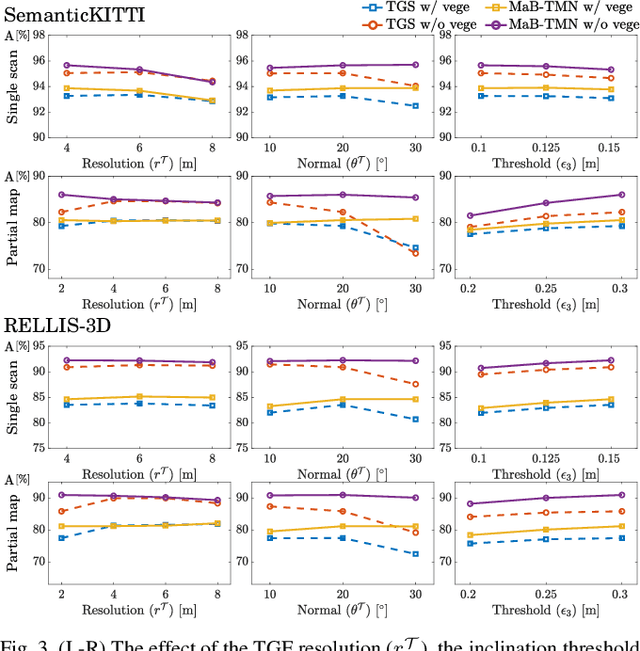
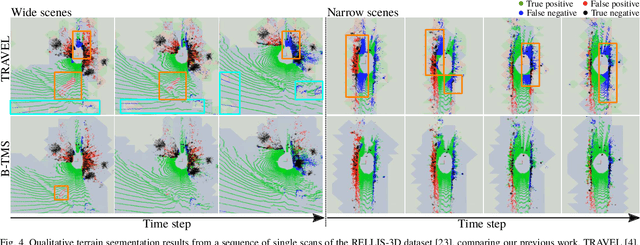
Recognizing traversable terrain from 3D point cloud data is critical, as it directly impacts the performance of autonomous navigation in off-road environments. However, existing segmentation algorithms often struggle with challenges related to changes in data distribution, environmental specificity, and sensor variations. Moreover, when encountering sunken areas, their performance is frequently compromised, and they may even fail to recognize them. To address these challenges, we introduce B-TMS, a novel approach that performs map-wise terrain modeling and segmentation by utilizing Bayesian generalized kernel (BGK) within the graph structure known as the tri-grid field (TGF). Our experiments encompass various data distributions, ranging from single scans to partial maps, utilizing both public datasets representing urban scenes and off-road environments, and our own dataset acquired from extremely bumpy terrains. Our results demonstrate notable contributions, particularly in terms of robustness to data distribution variations, adaptability to diverse environmental conditions, and resilience against the challenges associated with parameter changes.
Behavior Generation with Latent Actions
Mar 05, 2024Generative modeling of complex behaviors from labeled datasets has been a longstanding problem in decision making. Unlike language or image generation, decision making requires modeling actions - continuous-valued vectors that are multimodal in their distribution, potentially drawn from uncurated sources, where generation errors can compound in sequential prediction. A recent class of models called Behavior Transformers (BeT) addresses this by discretizing actions using k-means clustering to capture different modes. However, k-means struggles to scale for high-dimensional action spaces or long sequences, and lacks gradient information, and thus BeT suffers in modeling long-range actions. In this work, we present Vector-Quantized Behavior Transformer (VQ-BeT), a versatile model for behavior generation that handles multimodal action prediction, conditional generation, and partial observations. VQ-BeT augments BeT by tokenizing continuous actions with a hierarchical vector quantization module. Across seven environments including simulated manipulation, autonomous driving, and robotics, VQ-BeT improves on state-of-the-art models such as BeT and Diffusion Policies. Importantly, we demonstrate VQ-BeT's improved ability to capture behavior modes while accelerating inference speed 5x over Diffusion Policies. Videos and code can be found https://sjlee.cc/vq-bet
Similar but Different: A Survey of Ground Segmentation and Traversability Estimation for Terrestrial Robots
Jan 03, 2024



With the increasing demand for mobile robots and autonomous vehicles, several approaches for long-term robot navigation have been proposed. Among these techniques, ground segmentation and traversability estimation play important roles in perception and path planning, respectively. Even though these two techniques appear similar, their objectives are different. Ground segmentation divides data into ground and non-ground elements; thus, it is used as a preprocessing stage to extract objects of interest by rejecting ground points. In contrast, traversability estimation identifies and comprehends areas in which robots can move safely. Nevertheless, some researchers use these terms without clear distinction, leading to misunderstanding the two concepts. Therefore, in this study, we survey related literature and clearly distinguish ground and traversable regions considering four aspects: a) maneuverability of robot platforms, b) position of a robot in the surroundings, c) subset relation of negative obstacles, and d) subset relation of deformable objects.
Diversify & Conquer: Outcome-directed Curriculum RL via Out-of-Distribution Disagreement
Oct 30, 2023Reinforcement learning (RL) often faces the challenges of uninformed search problems where the agent should explore without access to the domain knowledge such as characteristics of the environment or external rewards. To tackle these challenges, this work proposes a new approach for curriculum RL called Diversify for Disagreement & Conquer (D2C). Unlike previous curriculum learning methods, D2C requires only a few examples of desired outcomes and works in any environment, regardless of its geometry or the distribution of the desired outcome examples. The proposed method performs diversification of the goal-conditional classifiers to identify similarities between visited and desired outcome states and ensures that the classifiers disagree on states from out-of-distribution, which enables quantifying the unexplored region and designing an arbitrary goal-conditioned intrinsic reward signal in a simple and intuitive way. The proposed method then employs bipartite matching to define a curriculum learning objective that produces a sequence of well-adjusted intermediate goals, which enable the agent to automatically explore and conquer the unexplored region. We present experimental results demonstrating that D2C outperforms prior curriculum RL methods in both quantitative and qualitative aspects, even with the arbitrarily distributed desired outcome examples.