 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Language Models Associate Sound with Meaning? A Multimodal Study of Sound Symbolism
Nov 16, 2025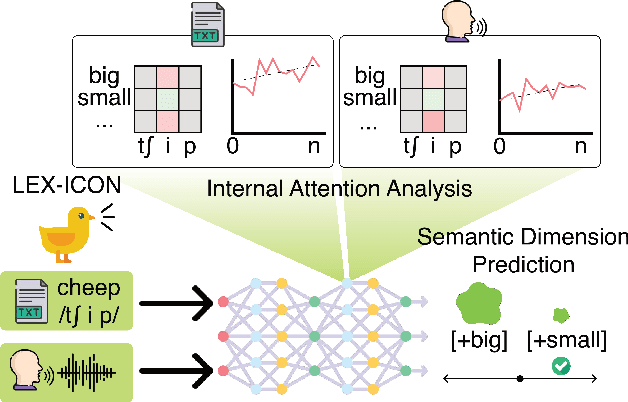

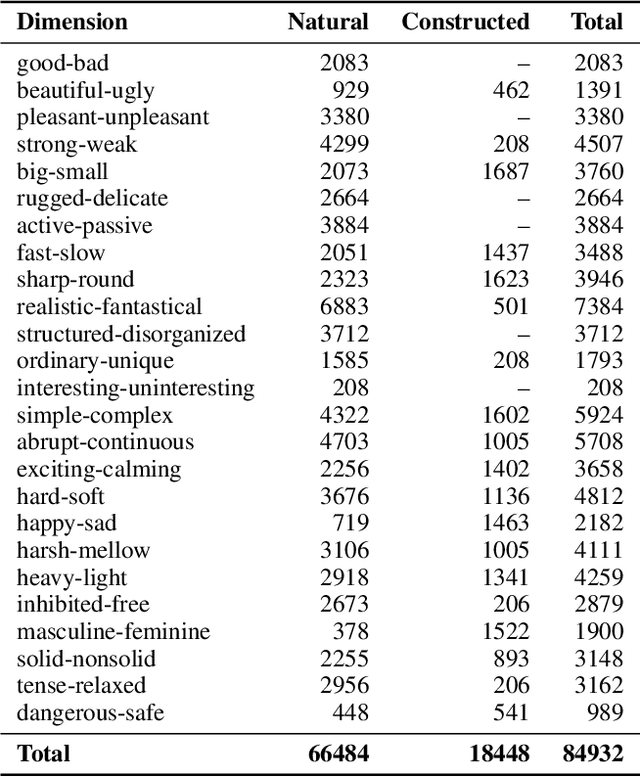
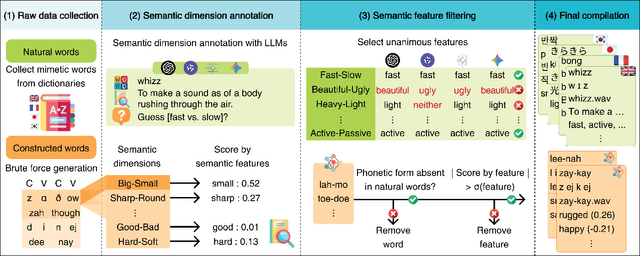
Sound symbolism is a linguistic concept that refers to non-arbitrary associations between phonetic forms and their meanings. We suggest that this can be a compelling probe into how Multimodal Large Language Models (MLLMs) interpret auditory information in human languages. We investigate MLLMs' performance on phonetic iconicity across textual (orthographic and IPA) and auditory forms of inputs with up to 25 semantic dimensions (e.g., sharp vs. round), observing models' layer-wise information processing by measuring phoneme-level attention fraction scores. To this end, we present LEX-ICON, an extensive mimetic word dataset consisting of 8,052 words from four natural languages (English, French, Japanese, and Korean) and 2,930 systematically constructed pseudo-words, annotated with semantic features applied across both text and audio modalities. Our key findings demonstrate (1) MLLMs' phonetic intuitions that align with existing linguistic research across multiple semantic dimensions and (2) phonosemantic attention patterns that highlight models' focus on iconic phonemes. These results bridge domains of artificial intelligence and cognitive linguistics, providing the first large-scale, quantitative analyses of phonetic iconicity in terms of MLLMs' interpretability.
Don't Look Only Once: Towards Multimodal Interactive Reasoning with Selective Visual Revisitation
May 24, 2025We present v1, a lightweight extension to Multimodal Large Language Models (MLLMs) that enables selective visual revisitation during inference. While current MLLMs typically consume visual input only once and reason purely over internal memory, v1 introduces a simple point-and-copy mechanism that allows the model to dynamically retrieve relevant image regions throughout the reasoning process. This mechanism augments existing architectures with minimal modifications, enabling contextual access to visual tokens based on the model's evolving hypotheses. To train this capability, we construct v1g, a dataset of 300K multimodal reasoning traces with interleaved visual grounding annotations. Experiments on three multimodal mathematical reasoning benchmarks -- MathVista, MathVision, and MathVerse -- demonstrate that v1 consistently improves performance over comparable baselines, particularly on tasks requiring fine-grained visual reference and multi-step reasoning. Our results suggest that dynamic visual access is a promising direction for enhancing grounded multimodal reasoning. Code, models, and data will be released to support future research.
Real-time Accident Anticipation for Autonomous Driving Through Monocular Depth-Enhanced 3D Modeling
Sep 02, 2024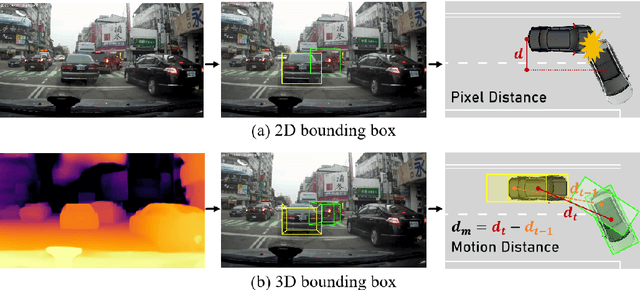
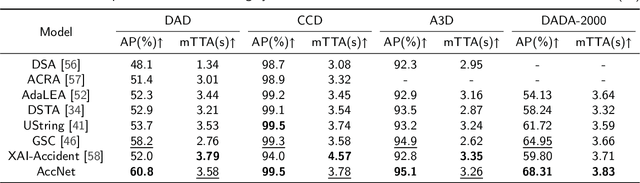
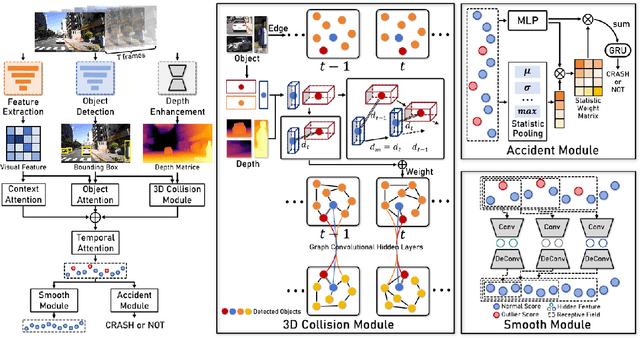
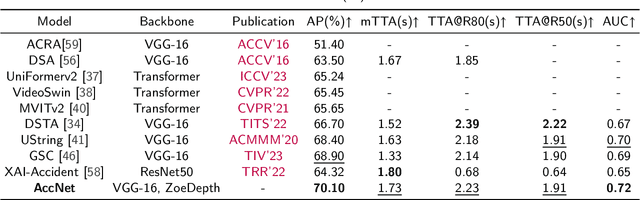
The primary goal of traffic accident anticipation is to foresee potential accidents in real time using dashcam videos, a task that is pivotal for enhancing the safety and reliability of autonomous driving technologies. In this study, we introduce an innovative framework, AccNet, which significantly advances the prediction capabilities beyond the current state-of-the-art (SOTA) 2D-based methods by incorporating monocular depth cues for sophisticated 3D scene modeling. Addressing the prevalent challenge of skewed data distribution in traffic accident datasets, we propose the Binary Adaptive Loss for Early Anticipation (BA-LEA). This novel loss function, together with a multi-task learning strategy, shifts the focus of the predictive model towards the critical moments preceding an accident. {We rigorously evaluate the performance of our framework on three benchmark datasets--Dashcam Accident Dataset (DAD), Car Crash Dataset (CCD), and AnAn Accident Detection (A3D), and DADA-2000 Dataset--demonstrating its superior predictive accuracy through key metrics such as Average Precision (AP) and mean Time-To-Accident (mTTA).
How to Train Your Fact Verifier: Knowledge Transfer with Multimodal Open Models
Jun 29, 2024



Given the growing influx of misinformation across news and social media, there is a critical need for systems that can provide effective real-time verification of news claims. Large language or multimodal model based verification has been proposed to scale up online policing mechanisms for mitigating spread of false and harmful content. While these can potentially reduce burden on human fact-checkers, such efforts may be hampered by foundation model training data becoming outdated. In this work, we test the limits of improving foundation model performance without continual updating through an initial study of knowledge transfer using either existing intra- and inter- domain benchmarks or explanations generated from large language models (LLMs). We evaluate on 12 public benchmarks for fact-checking and misinformation detection as well as two other tasks relevant to content moderation -- toxicity and stance detection. Our results on two recent multi-modal fact-checking benchmarks, Mocheg and Fakeddit, indicate that knowledge transfer strategies can improve Fakeddit performance over the state-of-the-art by up to 1.7% and Mocheg performance by up to 2.9%.
B-TMS: Bayesian Traversable Terrain Modeling and Segmentation Across 3D LiDAR Scans and Maps for Enhanced Off-Road Navigation
Jun 26, 2024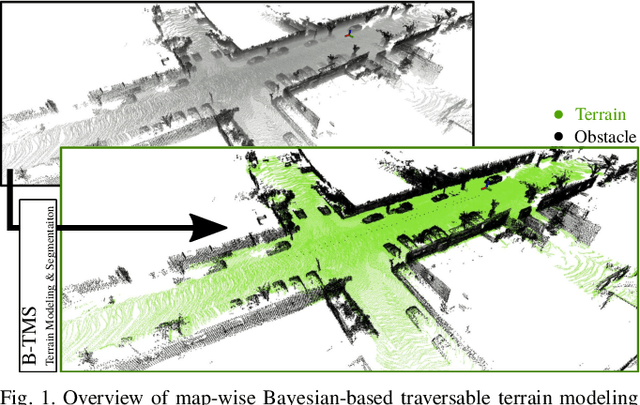

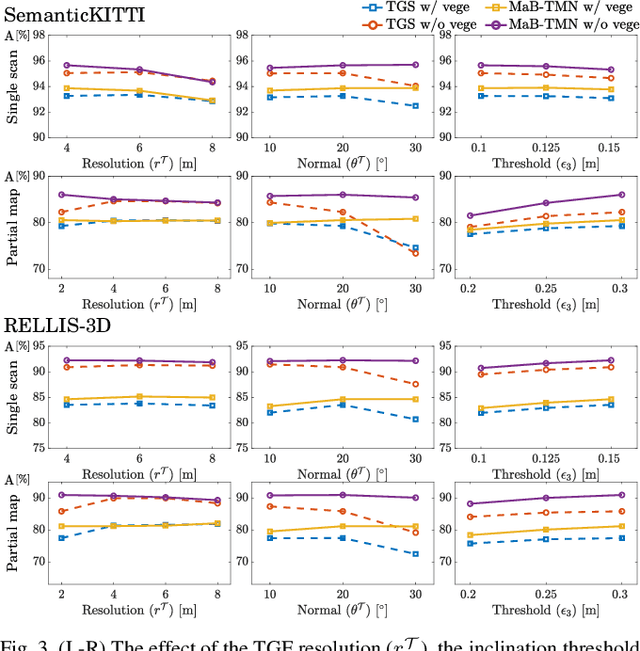
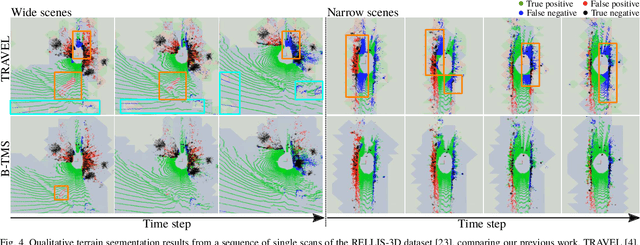
Recognizing traversable terrain from 3D point cloud data is critical, as it directly impacts the performance of autonomous navigation in off-road environments. However, existing segmentation algorithms often struggle with challenges related to changes in data distribution, environmental specificity, and sensor variations. Moreover, when encountering sunken areas, their performance is frequently compromised, and they may even fail to recognize them. To address these challenges, we introduce B-TMS, a novel approach that performs map-wise terrain modeling and segmentation by utilizing Bayesian generalized kernel (BGK) within the graph structure known as the tri-grid field (TGF). Our experiments encompass various data distributions, ranging from single scans to partial maps, utilizing both public datasets representing urban scenes and off-road environments, and our own dataset acquired from extremely bumpy terrains. Our results demonstrate notable contributions, particularly in terms of robustness to data distribution variations, adaptability to diverse environmental conditions, and resilience against the challenges associated with parameter changes.
Galibr: Targetless LiDAR-Camera Extrinsic Calibration Method via Ground Plane Initialization
Jun 14, 2024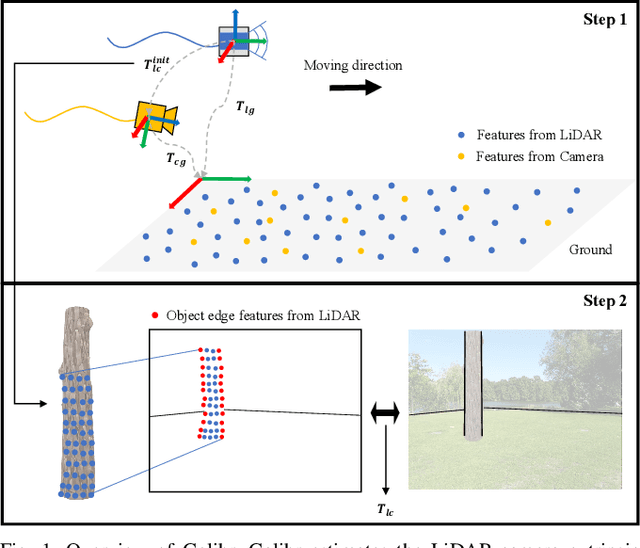
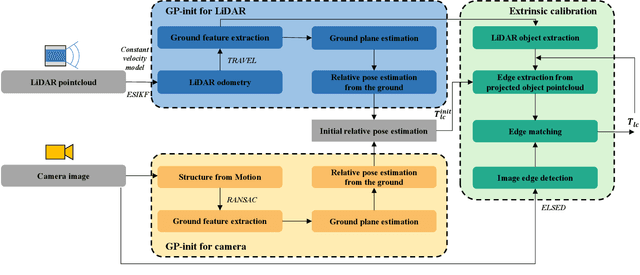
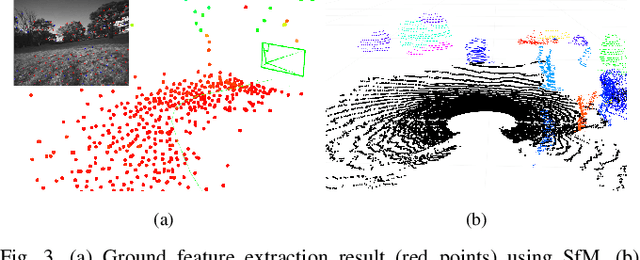

With the rapid development of autonomous driving and SLAM technology, the performance of autonomous systems using multimodal sensors highly relies on accurate extrinsic calibration. Addressing the need for a convenient, maintenance-friendly calibration process in any natural environment, this paper introduces Galibr, a fully automatic targetless LiDAR-camera extrinsic calibration tool designed for ground vehicle platforms in any natural setting. The method utilizes the ground planes and edge information from both LiDAR and camera inputs, streamlining the calibration process. It encompasses two main steps: an initial pose estimation algorithm based on ground planes (GP-init), and a refinement phase through edge extraction and matching. Our approach significantly enhances calibration performance, primarily attributed to our novel initial pose estimation method, as demonstrated in unstructured natural environments, including on the KITTI dataset and the KAIST quadruped dataset.
Enhancing Wind Speed and Wind Power Forecasting Using Shape-Wise Feature Engineering: A Novel Approach for Improved Accuracy and Robustness
Jan 16, 2024Accurate prediction of wind speed and power is vital for enhancing the efficiency of wind energy systems. Numerous solutions have been implemented to date, demonstrating their potential to improve forecasting. Among these, deep learning is perceived as a revolutionary approach in the field. However, despite their effectiveness, the noise present in the collected data remains a significant challenge. This noise has the potential to diminish the performance of these algorithms, leading to inaccurate predictions. In response to this, this study explores a novel feature engineering approach. This approach involves altering the data input shape in both Convolutional Neural Network-Long Short-Term Memory (CNN-LSTM) and Autoregressive models for various forecasting horizons. The results reveal substantial enhancements in model resilience against noise resulting from step increases in data. The approach could achieve an impressive 83% accuracy in predicting unseen data up to the 24th steps. Furthermore, this method consistently provides high accuracy for short, mid, and long-term forecasts, outperforming the performance of individual models. These findings pave the way for further research on noise reduction strategies at different forecasting horizons through shape-wise feature engineering.
Learning to Write with Coherence From Negative Examples
Sep 22, 2022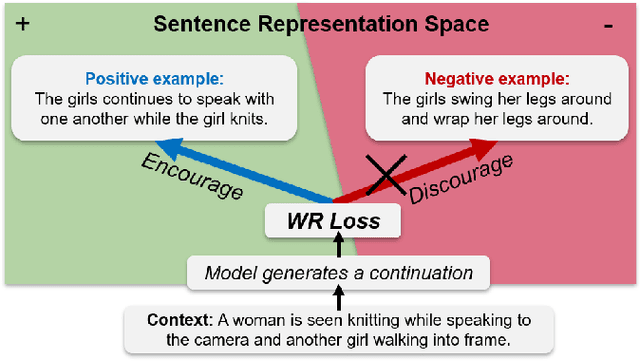
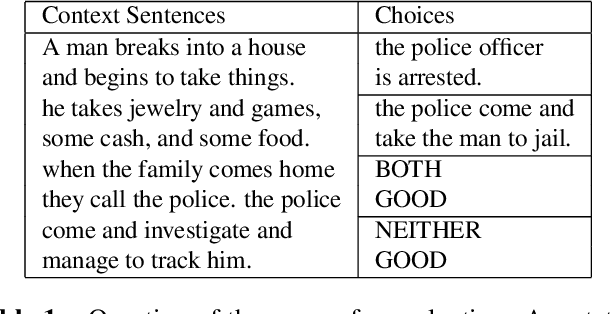
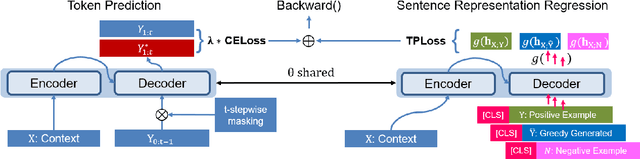
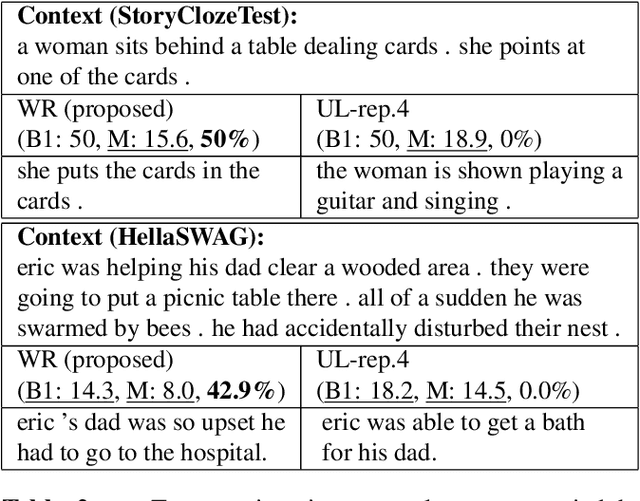
Coherence is one of the critical factors that determine the quality of writing. We propose writing relevance (WR) training method for neural encoder-decoder natural language generation (NLG) models which improves coherence of the continuation by leveraging negative examples. WR loss regresses the vector representation of the context and generated sentence toward positive continuation by contrasting it with the negatives. We compare our approach with Unlikelihood (UL) training in a text continuation task on commonsense natural language inference (NLI) corpora to show which method better models the coherence by avoiding unlikely continuations. The preference of our approach in human evaluation shows the efficacy of our method in improving coherence.
Recursive Constraints to Prevent Instability in Constrained Reinforcement Learning
Jan 20, 2022We consider the challenge of finding a deterministic policy for a Markov decision process that uniformly (in all states) maximizes one reward subject to a probabilistic constraint over a different reward. Existing solutions do not fully address our precise problem definition, which nevertheless arises naturally in the context of safety-critical robotic systems. This class of problem is known to be hard, but the combined requirements of determinism and uniform optimality can create learning instability. In this work, after describing and motivating our problem with a simple example, we present a suitable constrained reinforcement learning algorithm that prevents learning instability, using recursive constraints. Our proposed approach admits an approximative form that improves efficiency and is conservative w.r.t. the constraint.
Predictive PER: Balancing Priority and Diversity towards Stable Deep Reinforcement Learning
Nov 26, 2020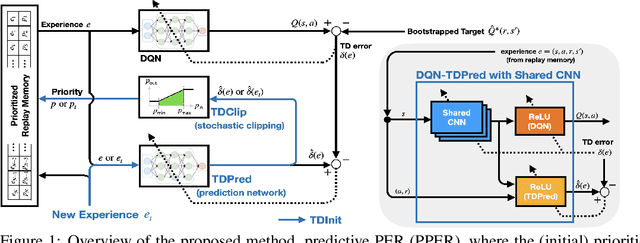
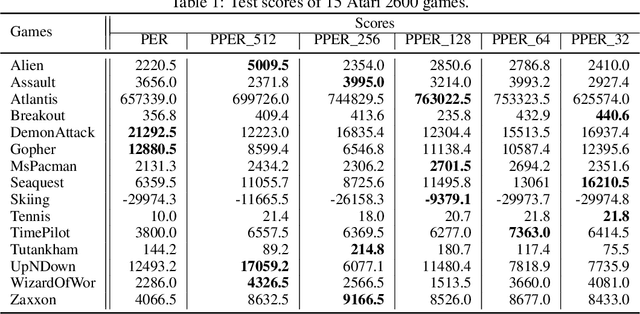
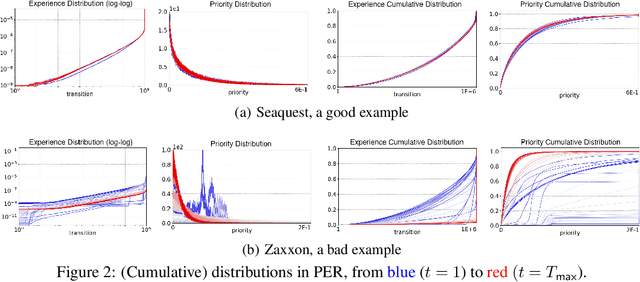

Prioritized experience replay (PER) samples important transitions, rather than uniformly, to improve the performance of a deep reinforcement learning agent. We claim that such prioritization has to be balanced with sample diversity for making the DQN stabilized and preventing forgetting. Our proposed improvement over PER, called Predictive PER (PPER), takes three countermeasures (TDInit, TDClip, TDPred) to (i) eliminate priority outliers and explosions and (ii) improve the sample diversity and distributions, weighted by priorities, both leading to stabilizing the DQN. The most notable among the three is the introduction of the second DNN called TDPred to generalize the in-distribution priorities. Ablation study and full experiments with Atari games show that each countermeasure by its own way and PPER contribute to successfully enhancing stability and thus performance over PER.