 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Weighted Finite Automata over the Max-Plus Semiring and its Termination
Jul 13, 2024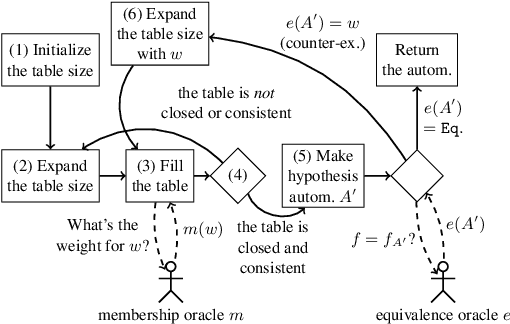
Active learning of finite automata has been vigorously pursued for the purposes of analysis and explanation of black-box systems. In this paper, we study an L*-style learning algorithm for weighted automata over the max-plus semiring. The max-plus setting exposes a "consistency" issue in the previously studied semiring-generic extension of L*: we show that it can fail to maintain consistency of tables, and can thus make equivalence queries on obviously wrong hypothesis automata. We present a theoretical fix by a mathematically clean notion of column-closedness. We also present a nontrivial and reasonably broad class of weighted languages over the max-plus semiring in which our algorithm terminates.
Temporal Logic Formalisation of ISO 34502 Critical Scenarios: Modular Construction with the RSS Safety Distance
Mar 27, 2024



As the development of autonomous vehicles progresses, efficient safety assurance methods become increasingly necessary. Safety assurance methods such as monitoring and scenario-based testing call for formalisation of driving scenarios. In this paper, we develop a temporal-logic formalisation of an important class of critical scenarios in the ISO standard 34502. We use signal temporal logic (STL) as a logical formalism. Our formalisation has two main features: 1) modular composition of logical formulas for systematic and comprehensive formalisation (following the compositional methodology of ISO 34502); 2) use of the RSS distance for defining danger. We find our formalisation comes with few parameters to tune thanks to the RSS distance. We experimentally evaluated our formalisation; using its results, we discuss the validity of our formalisation and its stability with respect to the choice of some parameter values.
Formal Verification of Safety Architectures for Automated Driving
Aug 20, 2023Safety architectures play a crucial role in the safety assurance of automated driving vehicles (ADVs). They can be used as safety envelopes of black-box ADV controllers, and for graceful degradation from one ODD to another. Building on our previous work on the formalization of responsibility-sensitive safety (RSS), we introduce a novel program logic that accommodates assume-guarantee reasoning and fallback-like constructs. This allows us to formally define and prove the safety of existing and novel safety architectures. We apply the logic to a pull over scenario and experimentally evaluate the resulting safety architecture.
* In proceedings of 2023 IEEE Intelligent Vehicles Symposium (IV), 8 pages, 5 figures
Formal Verification of Intersection Safety for Automated Driving
Aug 13, 2023


We build on our recent work on formalization of responsibility-sensitive safety (RSS) and present the first formal framework that enables mathematical proofs of the safety of control strategies in intersection scenarios. Intersection scenarios are challenging due to the complex interaction between vehicles; to cope with it, we extend the program logic dFHL in the previous work and introduce a novel formalism of hybrid control flow graphs on which our algorithm can automatically discover an RSS condition that ensures safety. An RSS condition thus discovered is experimentally evaluated; we observe that it is safe (as our safety proof says) and is not overly conservative.
Dynamic Shielding for Reinforcement Learning in Black-Box Environments
Jul 27, 2022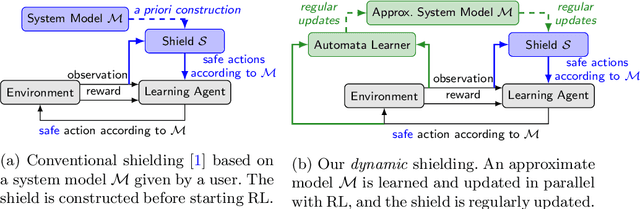
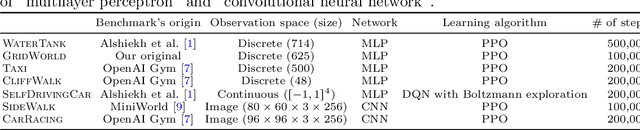

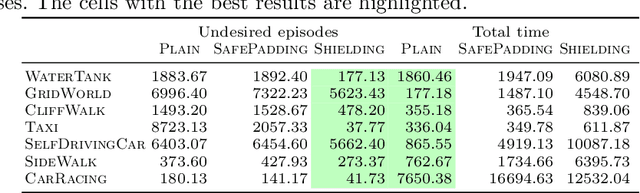
It is challenging to use reinforcement learning (RL) in cyber-physical systems due to the lack of safety guarantees during learning. Although there have been various proposals to reduce undesired behaviors during learning, most of these techniques require prior system knowledge, and their applicability is limited. This paper aims to reduce undesired behaviors during learning without requiring any prior system knowledge. We propose dynamic shielding: an extension of a model-based safe RL technique called shielding using automata learning. The dynamic shielding technique constructs an approximate system model in parallel with RL using a variant of the RPNI algorithm and suppresses undesired explorations due to the shield constructed from the learned model. Through this combination, potentially unsafe actions can be foreseen before the agent experiences them. Experiments show that our dynamic shield significantly decreases the number of undesired events during training.
Goal-Aware RSS for Complex Scenarios via Program Logic
Jul 06, 2022
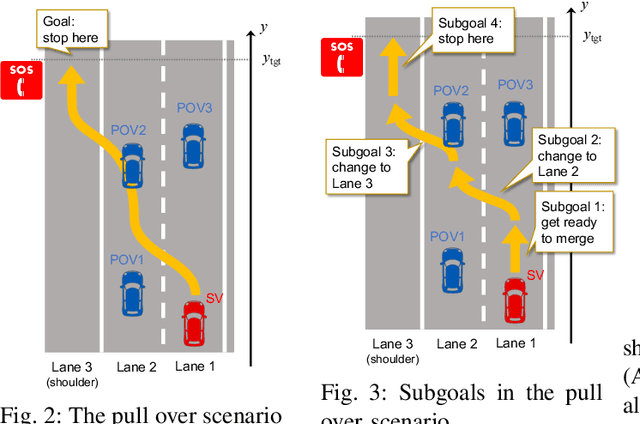
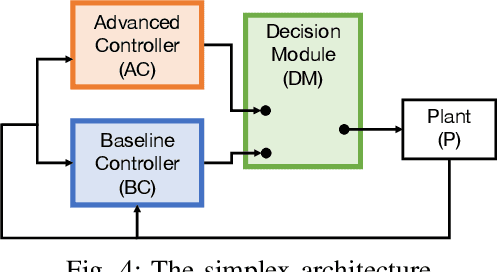
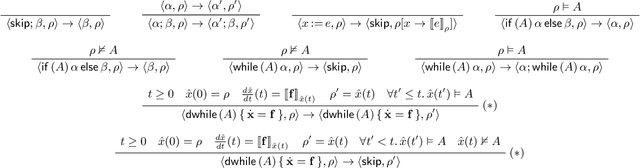
We introduce a goal-aware extension of responsibility-sensitive safety (RSS), a recent methodology for rule-based safety guarantee for automated driving systems (ADS). Making RSS rules guarantee goal achievement -- in addition to collision avoidance as in the original RSS -- requires complex planning over long sequences of manoeuvres. To deal with the complexity, we introduce a compositional reasoning framework based on program logic, in which one can systematically develop RSS rules for smaller subscenarios and combine them to obtain RSS rules for bigger scenarios. As the basis of the framework, we introduce a program logic dFHL that accommodates continuous dynamics and safety conditions. Our framework presents a dFHL-based workflow for deriving goal-aware RSS rules; we discuss its software support, too. We conducted experimental evaluation using RSS rules in a safety architecture. Its results show that goal-aware RSS is indeed effective in realising both collision avoidance and goal achievement.
Responsibility-Sensitive Safety: an Introduction with an Eye to Logical Foundations and Formalization
Jun 07, 2022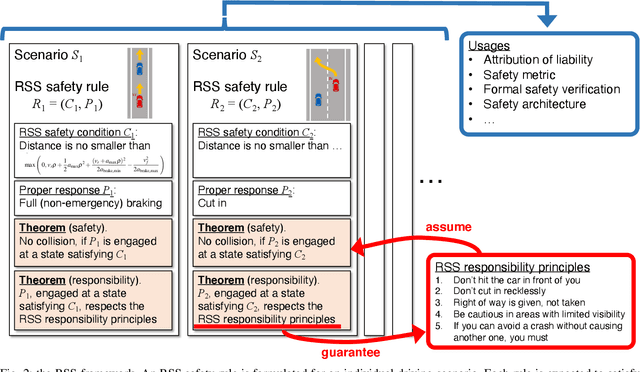
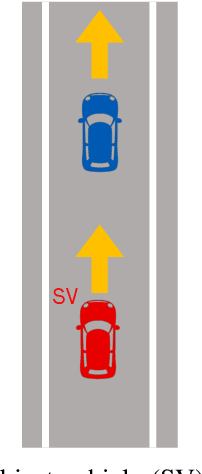
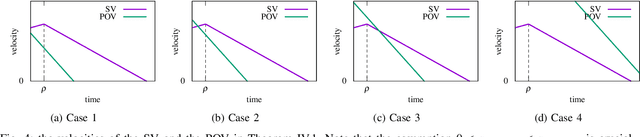
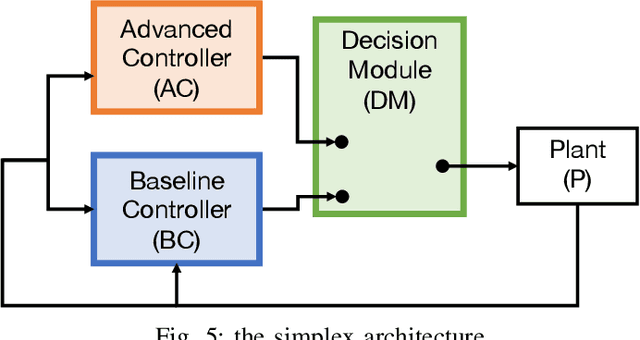
Responsibility-sensitive safety (RSS) is an approach to the safety of automated driving systems (ADS). It aims to introduce mathematically formulated safety rules, compliance with which guarantees collision avoidance as a mathematical theorem. However, despite the emphasis on mathematical and logical guarantees, the logical foundations and formalization of RSS are largely an unexplored topic of study. In this paper, we present an introduction to RSS, one that we expect will bridge between different research communities and pave the way to a logical theory of RSS, its mathematical formalization, and software tools of practical use.
Fibrational Initial Algebra-Final Coalgebra Coincidence over Initial Algebras: Turning Verification Witnesses Upside Down
May 11, 2021
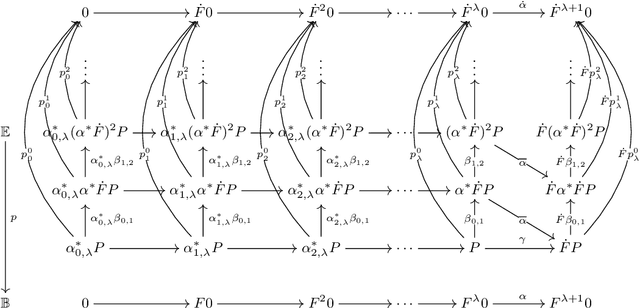
The coincidence between initial algebras (IAs) and final coalgebras (FCs) is a phenomenon that underpins various important results in theoretical computer science. In this paper, we identify a general fibrational condition for the IA-FC coincidence, namely in the fiber over an initial algebra in the base category. Identifying (co)algebras in a fiber as (co)inductive predicates, our fibrational IA-FC coincidence allows one to use coinductive witnesses (such as invariants) for verifying inductive properties (such as liveness). Our general fibrational theory features the technical condition of stability of chain colimits; we extend the framework to the presence of a monadic effect, too, restricting to fibrations of complete lattice-valued predicates. Practical benefits of our categorical theory are exemplified by new "upside-down" witness notions for three verification problems: probabilistic liveness, and acceptance and model-checking with respect to bottom-up tree automata.
Control-Data Separation and Logical Condition Propagation for Efficient Inference on Probabilistic Programs
Jan 28, 2021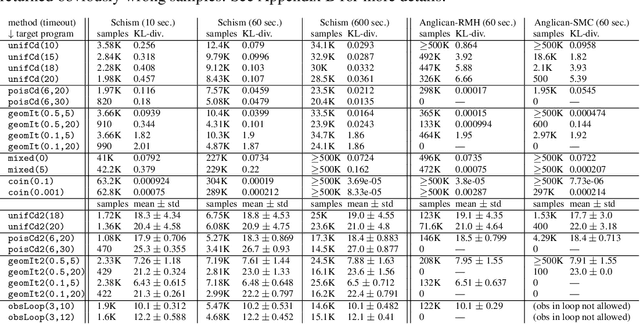


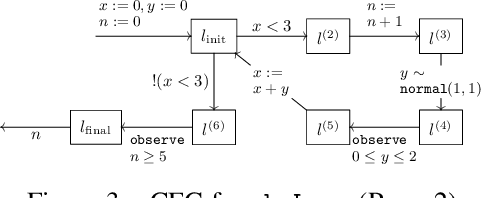
We introduce a novel sampling algorithm for Bayesian inference on imperative probabilistic programs. It features a hierarchical architecture that separates control flows from data: the top-level samples a control flow, and the bottom level samples data values along the control flow picked by the top level. This separation allows us to plug various language-based analysis techniques in probabilistic program sampling; specifically, we use logical backward propagation of observations for sampling efficiency. We implemented our algorithm on top of Anglican. The experimental results demonstrate our algorithm's efficiency, especially for programs with while loops and rare observations.
Predictive PER: Balancing Priority and Diversity towards Stable Deep Reinforcement Learning
Nov 26, 2020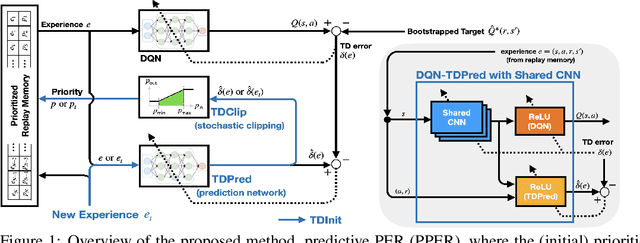
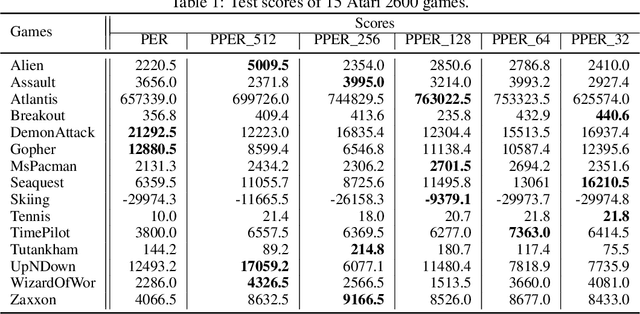
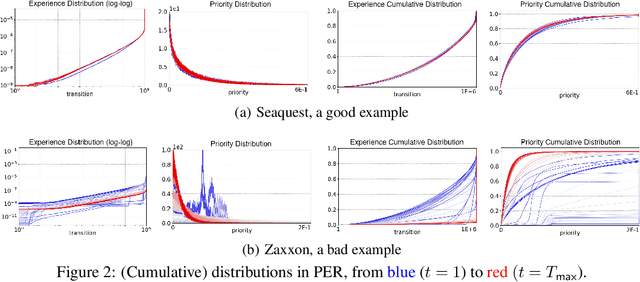

Prioritized experience replay (PER) samples important transitions, rather than uniformly, to improve the performance of a deep reinforcement learning agent. We claim that such prioritization has to be balanced with sample diversity for making the DQN stabilized and preventing forgetting. Our proposed improvement over PER, called Predictive PER (PPER), takes three countermeasures (TDInit, TDClip, TDPred) to (i) eliminate priority outliers and explosions and (ii) improve the sample diversity and distributions, weighted by priorities, both leading to stabilizing the DQN. The most notable among the three is the introduction of the second DNN called TDPred to generalize the in-distribution priorities. Ablation study and full experiments with Atari games show that each countermeasure by its own way and PPER contribute to successfully enhancing stability and thus performance over PER.