 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive PER: Balancing Priority and Diversity towards Stable Deep Reinforcement Learning
Paper and Code
Nov 26, 2020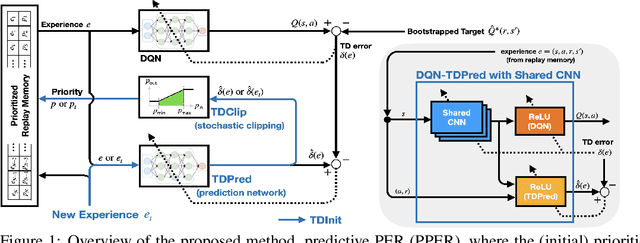
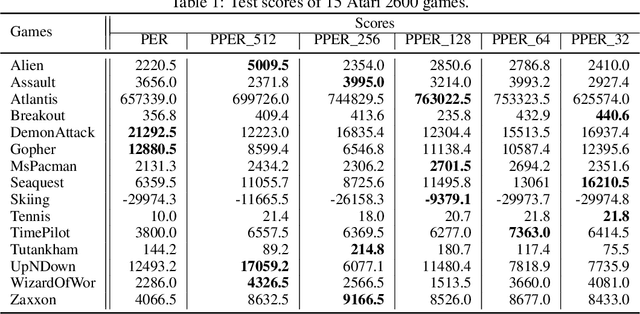
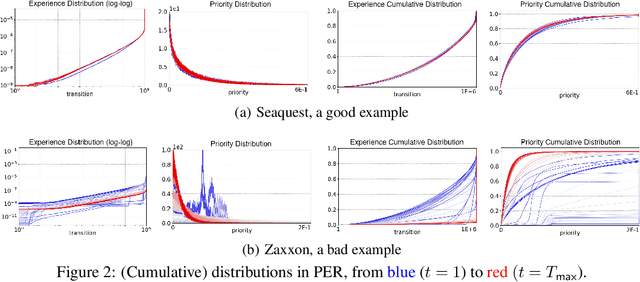

Prioritized experience replay (PER) samples important transitions, rather than uniformly, to improve the performance of a deep reinforcement learning agent. We claim that such prioritization has to be balanced with sample diversity for making the DQN stabilized and preventing forgetting. Our proposed improvement over PER, called Predictive PER (PPER), takes three countermeasures (TDInit, TDClip, TDPred) to (i) eliminate priority outliers and explosions and (ii) improve the sample diversity and distributions, weighted by priorities, both leading to stabilizing the DQN. The most notable among the three is the introduction of the second DNN called TDPred to generalize the in-distribution priorities. Ablation study and full experiments with Atari games show that each countermeasure by its own way and PPER contribute to successfully enhancing stability and thus performance over PER.