 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoftMatcha 2: A Fast and Soft Pattern Matcher for Trillion-Scale Corpora
Feb 11, 2026We present an ultra-fast and flexible search algorithm that enables search over trillion-scale natural language corpora in under 0.3 seconds while handling semantic variations (substitution, insertion, and deletion). Our approach employs string matching based on suffix arrays that scales well with corpus size. To mitigate the combinatorial explosion induced by the semantic relaxation of queries, our method is built on two key algorithmic ideas: fast exact lookup enabled by a disk-aware design, and dynamic corpus-aware pruning. We theoretically show that the proposed method suppresses exponential growth in the search space with respect to query length by leveraging statistical properties of natural language. In experiments on FineWeb-Edu (Lozhkov et al., 2024) (1.4T tokens), we show that our method achieves significantly lower search latency than existing methods: infini-gram (Liu et al., 2024), infini-gram mini (Xu et al., 2025), and SoftMatcha (Deguchi et al., 2025). As a practical application, we demonstrate that our method identifies benchmark contamination in training corpora, unidentified by existing approaches. We also provide an online demo of fast, soft search across corpora in seven languages.
SoftMatcha: A Soft and Fast Pattern Matcher for Billion-Scale Corpus Searches
Mar 05, 2025Researchers and practitioners in natural language processing and computational linguistics frequently observe and analyze the real language usage in large-scale corpora. For that purpose, they often employ off-the-shelf pattern-matching tools, such as grep, and keyword-in-context concordancers, which is widely used in corpus linguistics for gathering examples. Nonetheless, these existing techniques rely on surface-level string matching, and thus they suffer from the major limitation of not being able to handle orthographic variations and paraphrasing -- notable and common phenomena in any natural language. In addition, existing continuous approaches such as dense vector search tend to be overly coarse, often retrieving texts that are unrelated but share similar topics. Given these challenges, we propose a novel algorithm that achieves \emph{soft} (or semantic) yet efficient pattern matching by relaxing a surface-level matching with word embeddings. Our algorithm is highly scalable with respect to the size of the corpus text utilizing inverted indexes. We have prepared an efficient implementation, and we provide an accessible web tool. Our experiments demonstrate that the proposed method (i) can execute searches on billion-scale corpora in less than a second, which is comparable in speed to surface-level string matching and dense vector search; (ii) can extract harmful instances that semantically match queries from a large set of English and Japanese Wikipedia articles; and (iii) can be effectively applied to corpus-linguistic analyses of Latin, a language with highly diverse inflections.
StatWhy: Formal Verification Tool for Statistical Hypothesis Testing Programs
May 25, 2024
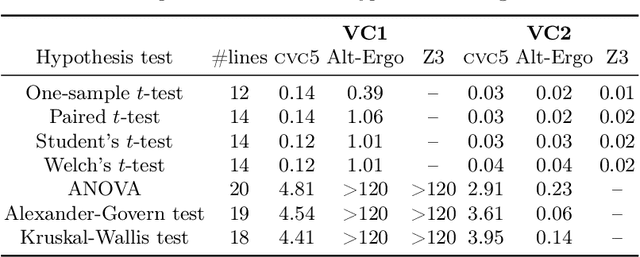

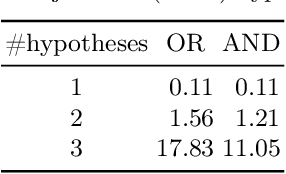
Statistical methods have been widely misused and misinterpreted in various scientific fields, raising significant concerns about the integrity of scientific research. To develop techniques to mitigate this problem, we propose a new method for formally specifying and automatically verifying the correctness of statistical programs. In this method, programmers are reminded to check the requirements for statistical methods by annotating their source code. Then, a software tool called StatWhy automatically checks whether the programmers have properly specified the requirements for the statistical methods. This tool is implemented using the Why3 platform to verify the correctness of OCaml programs for statistical hypothesis testing. We demonstrate how StatWhy can be used to avoid common errors in a variety of popular hypothesis testing programs.
Formalizing Statistical Causality via Modal Logic
Nov 01, 2022We propose a formal language for describing and explaining statistical causality. Concretely, we define Statistical Causality Language (StaCL) for specifying causal effects on random variables. StaCL incorporates modal operators for interventions to express causal properties between probability distributions in different possible worlds in a Kripke model. We formalize axioms for probability distributions, interventions, and causal predicates using StaCL formulas. These axioms are expressive enough to derive the rules of Pearl's do-calculus. Finally, we demonstrate by examples that StaCL can be used to prove and explain the correctness of statistical causal inference.
BOREx: Bayesian-Optimization--Based Refinement of Saliency Map for Image- and Video-Classification Models
Oct 31, 2022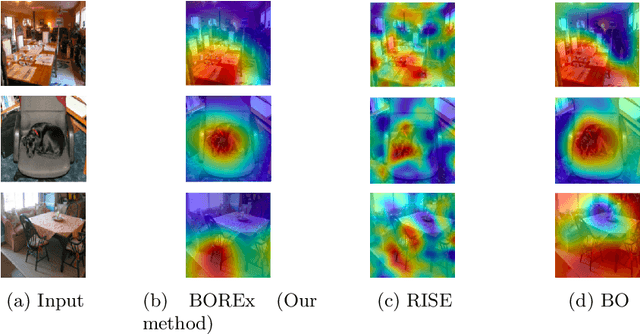
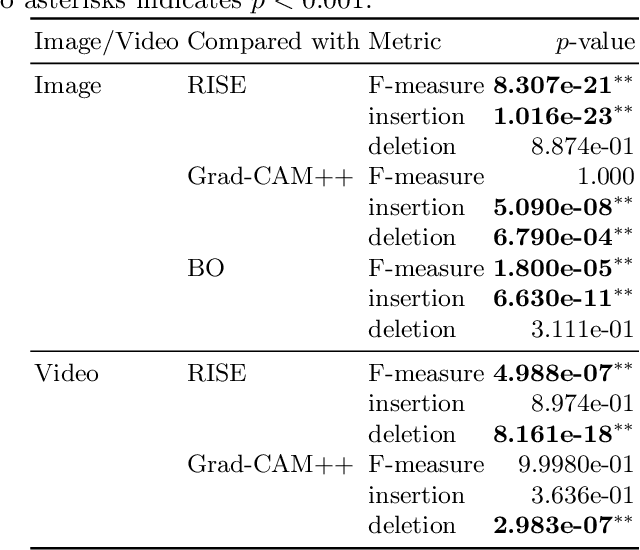
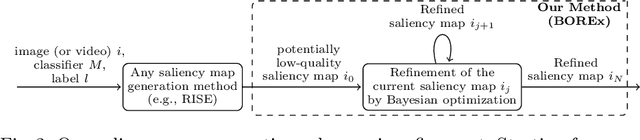
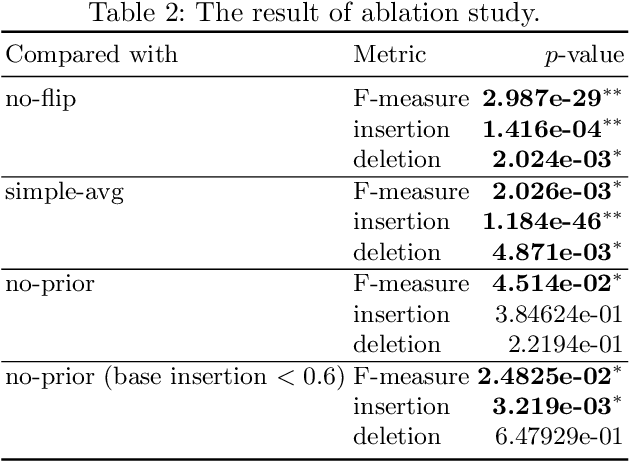
Explaining a classification result produced by an image- and video-classification model is one of the important but challenging issues in computer vision. Many methods have been proposed for producing heat-map--based explanations for this purpose, including ones based on the white-box approach that uses the internal information of a model (e.g., LRP, Grad-CAM, and Grad-CAM++) and ones based on the black-box approach that does not use any internal information (e.g., LIME, SHAP, and RISE). We propose a new black-box method BOREx (Bayesian Optimization for Refinement of visual model Explanation) to refine a heat map produced by any method. Our observation is that a heat-map--based explanation can be seen as a prior for an explanation method based on Bayesian optimization. Based on this observation, BOREx conducts Gaussian process regression (GPR) to estimate the saliency of each pixel in a given image starting from the one produced by another explanation method. Our experiments statistically demonstrate that the refinement by BOREx improves low-quality heat maps for image- and video-classification results.
Sound and Relatively Complete Belief Hoare Logic for Statistical Hypothesis Testing Programs
Aug 15, 2022
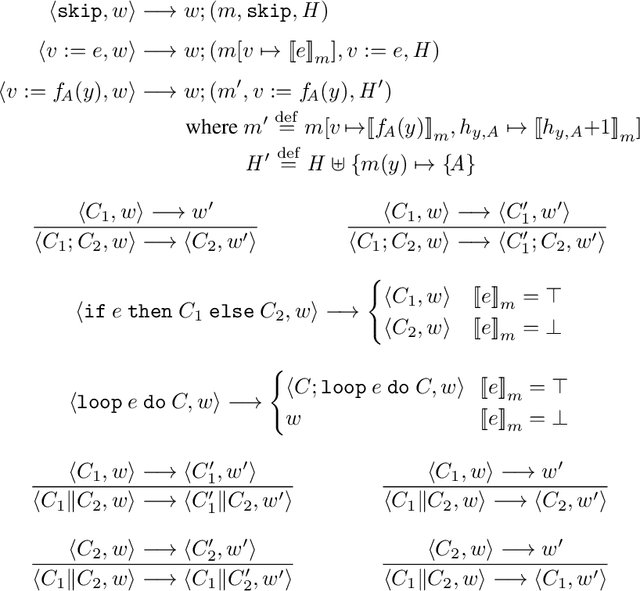


We propose a new approach to formally describing the requirement for statistical inference and checking whether a program uses the statistical method appropriately. Specifically, we define belief Hoare logic (BHL) for formalizing and reasoning about the statistical beliefs acquired via hypothesis testing. This program logic is sound and relatively complete with respect to a Kripke model for hypothesis tests. We demonstrate by examples that BHL is useful for reasoning about practical issues in hypothesis testing. In our framework, we clarify the importance of prior beliefs in acquiring statistical beliefs through hypothesis testing, and discuss the whole picture of the justification of statistical inference inside and outside the program logic.
Goal-Aware RSS for Complex Scenarios via Program Logic
Jul 06, 2022
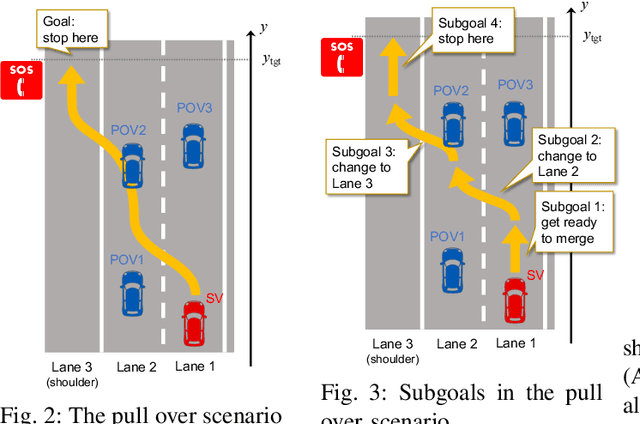
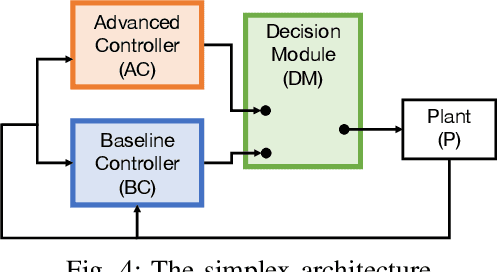
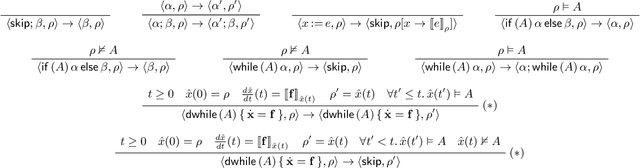
We introduce a goal-aware extension of responsibility-sensitive safety (RSS), a recent methodology for rule-based safety guarantee for automated driving systems (ADS). Making RSS rules guarantee goal achievement -- in addition to collision avoidance as in the original RSS -- requires complex planning over long sequences of manoeuvres. To deal with the complexity, we introduce a compositional reasoning framework based on program logic, in which one can systematically develop RSS rules for smaller subscenarios and combine them to obtain RSS rules for bigger scenarios. As the basis of the framework, we introduce a program logic dFHL that accommodates continuous dynamics and safety conditions. Our framework presents a dFHL-based workflow for deriving goal-aware RSS rules; we discuss its software support, too. We conducted experimental evaluation using RSS rules in a safety architecture. Its results show that goal-aware RSS is indeed effective in realising both collision avoidance and goal achievement.
HELMHOLTZ: A Verifier for Tezos Smart Contracts Based on Refinement Types
Sep 10, 2021



A smart contract is a program executed on a blockchain, based on which many cryptocurrencies are implemented, and is being used for automating transactions. Due to the large amount of money that smart contracts deal with, there is a surging demand for a method that can statically and formally verify them. This article describes our type-based static verification tool HELMHOLTZ for Michelson, which is a statically typed stack-based language for writing smart contracts that are executed on the blockchain platform Tezos. HELMHOLTZ is designed on top of our extension of Michelson's type system with refinement types. HELMHOLTZ takes a Michelson program annotated with a user-defined specification written in the form of a refinement type as input; it then typechecks the program against the specification based on the refinement type system, discharging the generated verification conditions with the SMT solver Z3. We briefly introduce our refinement type system for the core calculus Mini-Michelson of Michelson, which incorporates the characteristic features such as compound datatypes (e.g., lists and pairs), higher-order functions, and invocation of another contract. \HELMHOLTZ{} successfully verifies several practical Michelson programs, including one that transfers money to an account and that checks a digital signature.
Enhancing Loop-Invariant Synthesis via Reinforcement Learning
Aug 14, 2021
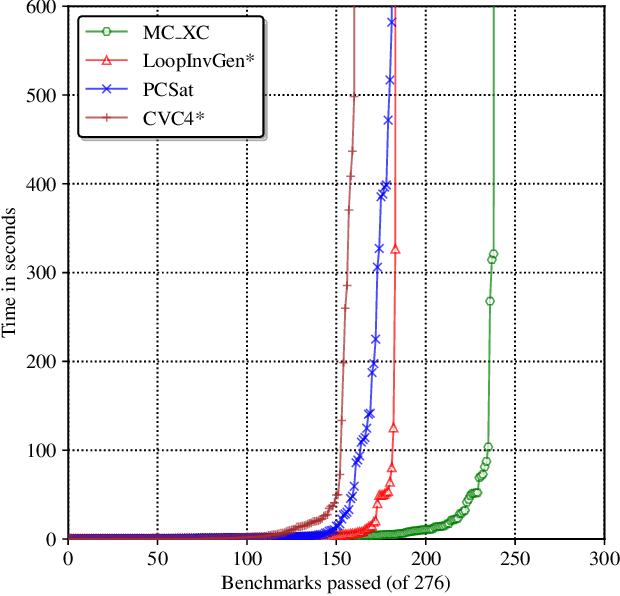
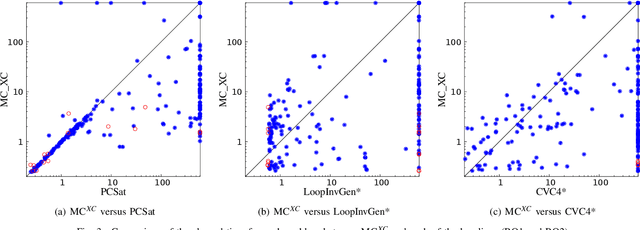
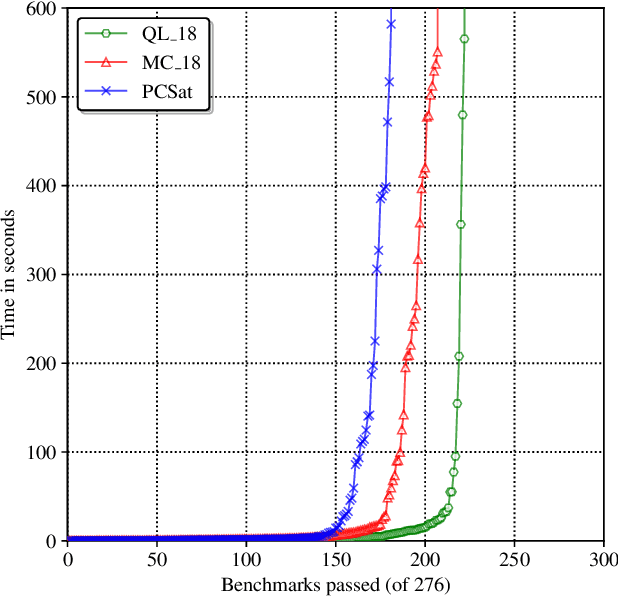
Loop-invariant synthesis is the basis of every program verification procedure. Due to its undecidability in general, a tool for invariant synthesis necessarily uses heuristics. Despite the common belief that the design of heuristics is vital for the effective performance of a verifier, little work has been performed toward obtaining the optimal heuristics for each invariant-synthesis tool. Instead, developers have hand-tuned the heuristics of tools. This study demonstrates that we can effectively and automatically learn a good heuristic via reinforcement learning for an invariant synthesizer PCSat. Our experiment shows that PCSat combined with the heuristic learned by reinforcement learning outperforms the state-of-the-art solvers for this task. To the best of our knowledge, this is the first work that investigates learning the heuristics of an invariant synthesis tool.
Control-Data Separation and Logical Condition Propagation for Efficient Inference on Probabilistic Programs
Jan 28, 2021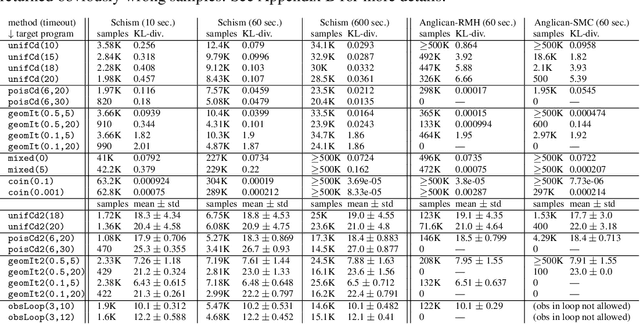


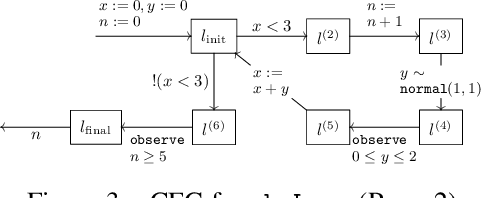
We introduce a novel sampling algorithm for Bayesian inference on imperative probabilistic programs. It features a hierarchical architecture that separates control flows from data: the top-level samples a control flow, and the bottom level samples data values along the control flow picked by the top level. This separation allows us to plug various language-based analysis techniques in probabilistic program sampling; specifically, we use logical backward propagation of observations for sampling efficiency. We implemented our algorithm on top of Anglican. The experimental results demonstrate our algorithm's efficiency, especially for programs with while loops and rare observations.