 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVSRD: Instance-Aware Volumetric Silhouette Rendering for Weakly Supervised 3D Object Detection
Mar 29, 2024Monocular 3D object detection poses a significant challenge in 3D scene understanding due to its inherently ill-posed nature in monocular depth estimation. Existing methods heavily rely on supervised learning using abundant 3D labels, typically obtained through expensive and labor-intensive annotation on LiDAR point clouds. To tackle this problem, we propose a novel weakly supervised 3D object detection framework named VSRD (Volumetric Silhouette Rendering for Detection) to train 3D object detectors without any 3D supervision but only weak 2D supervision. VSRD consists of multi-view 3D auto-labeling and subsequent training of monocular 3D object detectors using the pseudo labels generated in the auto-labeling stage. In the auto-labeling stage, we represent the surface of each instance as a signed distance field (SDF) and render its silhouette as an instance mask through our proposed instance-aware volumetric silhouette rendering. To directly optimize the 3D bounding boxes through rendering, we decompose the SDF of each instance into the SDF of a cuboid and the residual distance field (RDF) that represents the residual from the cuboid. This mechanism enables us to optimize the 3D bounding boxes in an end-to-end manner by comparing the rendered instance masks with the ground truth instance masks. The optimized 3D bounding boxes serve as effective training data for 3D object detection. We conduct extensive experiments on the KITTI-360 dataset, demonstrating that our method outperforms the existing weakly supervised 3D object detection methods. The code is available at https://github.com/skmhrk1209/VSRD.
Geometry-Aware Unsupervised Domain Adaptation for Stereo Matching
Mar 26, 2021
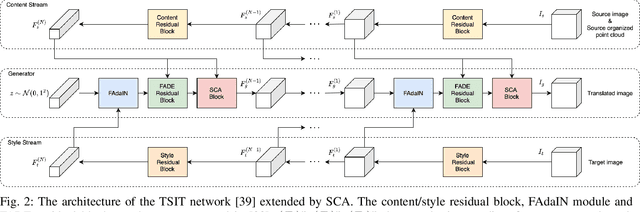
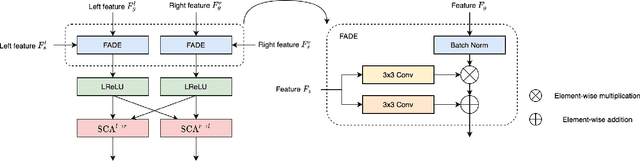
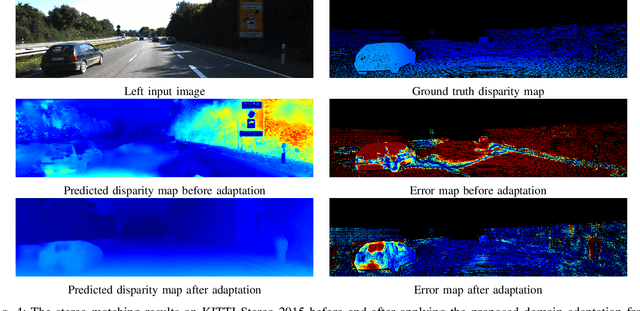
Recently proposed DNN-based stereo matching methods that learn priors directly from data are known to suffer a drastic drop in accuracy in new environments. Although supervised approaches with ground truth disparity maps often work well, collecting them in each deployment environment is cumbersome and costly. For this reason, many unsupervised domain adaptation methods based on image-to-image translation have been proposed, but these methods do not preserve the geometric structure of a stereo image pair because the image-to-image translation is applied to each view separately. To address this problem, in this paper, we propose an attention mechanism that aggregates features in the left and right views, called Stereoscopic Cross Attention (SCA). Incorporating SCA to an image-to-image translation network makes it possible to preserve the geometric structure of a stereo image pair in the process of the image-to-image translation. We empirically demonstrate the effectiveness of the proposed unsupervised domain adaptation based on the image-to-image translation with SCA.
Visualizing Color-wise Saliency of Black-Box Image Classification Models
Oct 06, 2020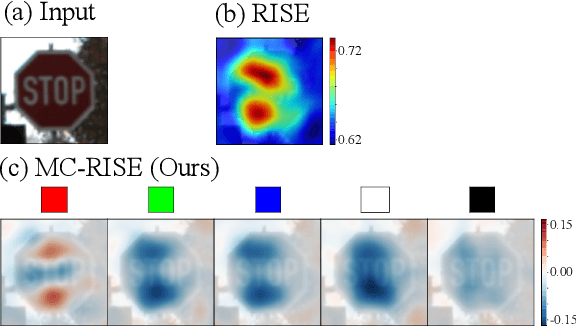

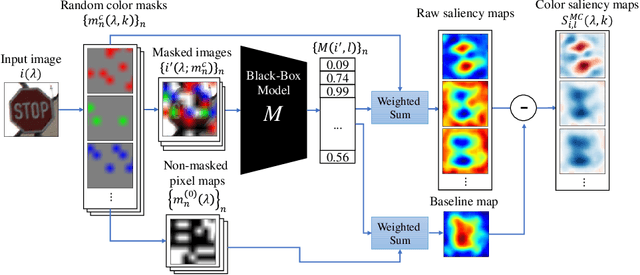
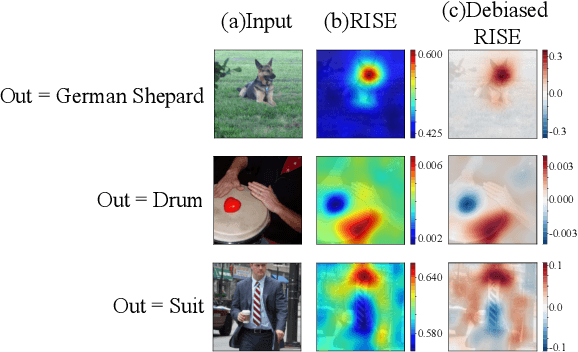
Image classification based on machine learning is being commonly used. However, a classification result given by an advanced method, including deep learning, is often hard to interpret. This problem of interpretability is one of the major obstacles in deploying a trained model in safety-critical systems. Several techniques have been proposed to address this problem; one of which is RISE, which explains a classification result by a heatmap, called a saliency map, which explains the significance of each pixel. We propose MC-RISE (Multi-Color RISE), which is an enhancement of RISE to take color information into account in an explanation. Our method not only shows the saliency of each pixel in a given image as the original RISE does, but the significance of color components of each pixel; a saliency map with color information is useful especially in the domain where the color information matters (e.g., traffic-sign recognition). We implemented MC-RISE and evaluate them using two datasets (GTSRB and ImageNet) to demonstrate the effectiveness of our methods in comparison with existing techniques for interpreting image classification results.