 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTDM: Temporally-Consistent Diffusion Model for All-in-One Real-World Video Restoration
Jan 04, 2025



In this paper, we propose the first diffusion-based all-in-one video restoration method that utilizes the power of a pre-trained Stable Diffusion and a fine-tuned ControlNet. Our method can restore various types of video degradation with a single unified model, overcoming the limitation of standard methods that require specific models for each restoration task. Our contributions include an efficient training strategy with Task Prompt Guidance (TPG) for diverse restoration tasks, an inference strategy that combines Denoising Diffusion Implicit Models~(DDIM) inversion with a novel Sliding Window Cross-Frame Attention (SW-CFA) mechanism for enhanced content preservation and temporal consistency, and a scalable pipeline that makes our method all-in-one to adapt to different video restoration tasks. Through extensive experiments on five video restoration tasks, we demonstrate the superiority of our method in generalization capability to real-world videos and temporal consistency preservation over existing state-of-the-art methods. Our method advances the video restoration task by providing a unified solution that enhances video quality across multiple applications.
Disparity Estimation Using a Quad-Pixel Sensor
Sep 01, 2024



A quad-pixel (QP) sensor is increasingly integrated into commercial mobile cameras. The QP sensor has a unit of 2$\times$2 four photodiodes under a single microlens, generating multi-directional phase shifting when out-focus blurs occur. Similar to a dual-pixel (DP) sensor, the phase shifting can be regarded as stereo disparity and utilized for depth estimation. Based on this, we propose a QP disparity estimation network (QPDNet), which exploits abundant QP information by fusing vertical and horizontal stereo-matching correlations for effective disparity estimation. We also present a synthetic pipeline to generate a training dataset from an existing RGB-Depth dataset. Experimental results demonstrate that our QPDNet outperforms state-of-the-art stereo and DP methods. Our code and synthetic dataset are available at https://github.com/Zhuofeng-Wu/QPDNet.
VSRD: Instance-Aware Volumetric Silhouette Rendering for Weakly Supervised 3D Object Detection
Mar 29, 2024Monocular 3D object detection poses a significant challenge in 3D scene understanding due to its inherently ill-posed nature in monocular depth estimation. Existing methods heavily rely on supervised learning using abundant 3D labels, typically obtained through expensive and labor-intensive annotation on LiDAR point clouds. To tackle this problem, we propose a novel weakly supervised 3D object detection framework named VSRD (Volumetric Silhouette Rendering for Detection) to train 3D object detectors without any 3D supervision but only weak 2D supervision. VSRD consists of multi-view 3D auto-labeling and subsequent training of monocular 3D object detectors using the pseudo labels generated in the auto-labeling stage. In the auto-labeling stage, we represent the surface of each instance as a signed distance field (SDF) and render its silhouette as an instance mask through our proposed instance-aware volumetric silhouette rendering. To directly optimize the 3D bounding boxes through rendering, we decompose the SDF of each instance into the SDF of a cuboid and the residual distance field (RDF) that represents the residual from the cuboid. This mechanism enables us to optimize the 3D bounding boxes in an end-to-end manner by comparing the rendered instance masks with the ground truth instance masks. The optimized 3D bounding boxes serve as effective training data for 3D object detection. We conduct extensive experiments on the KITTI-360 dataset, demonstrating that our method outperforms the existing weakly supervised 3D object detection methods. The code is available at https://github.com/skmhrk1209/VSRD.
CFDNet: A Generalizable Foggy Stereo Matching Network with Contrastive Feature Distillation
Feb 29, 2024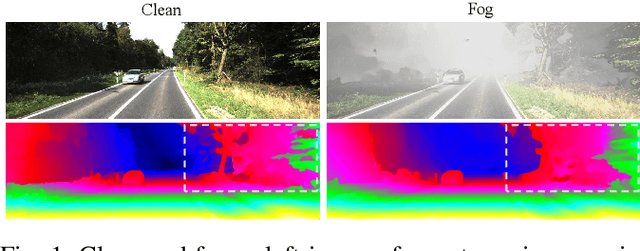
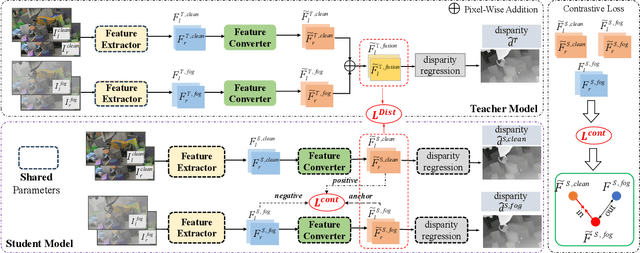
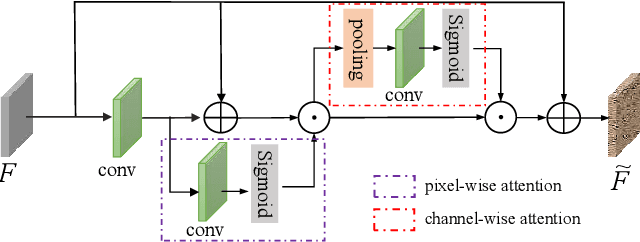
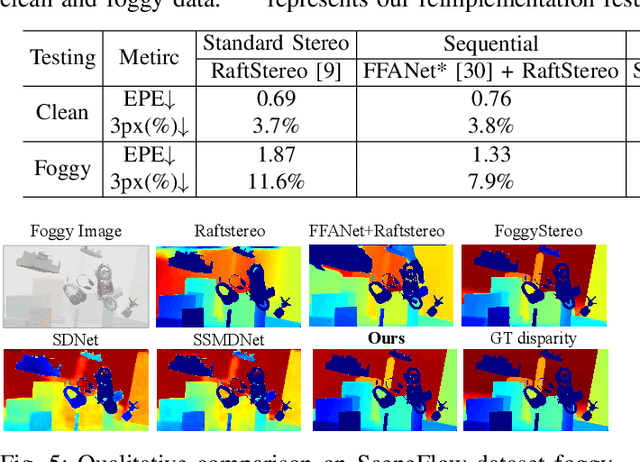
Stereo matching under foggy scenes remains a challenging task since the scattering effect degrades the visibility and results in less distinctive features for dense correspondence matching. While some previous learning-based methods integrated a physical scattering function for simultaneous stereo-matching and dehazing, simply removing fog might not aid depth estimation because the fog itself can provide crucial depth cues. In this work, we introduce a framework based on contrastive feature distillation (CFD). This strategy combines feature distillation from merged clean-fog features with contrastive learning, ensuring balanced dependence on fog depth hints and clean matching features. This framework helps to enhance model generalization across both clean and foggy environments. Comprehensive experiments on synthetic and real-world datasets affirm the superior strength and adaptability of our method.
Digging Into Normal Incorporated Stereo Matching
Feb 28, 2024Despite the remarkable progress facilitated by learning-based stereo-matching algorithms, disparity estimation in low-texture, occluded, and bordered regions still remains a bottleneck that limits the performance. To tackle these challenges, geometric guidance like plane information is necessary as it provides intuitive guidance about disparity consistency and affinity similarity. In this paper, we propose a normal incorporated joint learning framework consisting of two specific modules named non-local disparity propagation(NDP) and affinity-aware residual learning(ARL). The estimated normal map is first utilized for calculating a non-local affinity matrix and a non-local offset to perform spatial propagation at the disparity level. To enhance geometric consistency, especially in low-texture regions, the estimated normal map is then leveraged to calculate a local affinity matrix, providing the residual learning with information about where the correction should refer and thus improving the residual learning efficiency. Extensive experiments on several public datasets including Scene Flow, KITTI 2015, and Middlebury 2014 validate the effectiveness of our proposed method. By the time we finished this work, our approach ranked 1st for stereo matching across foreground pixels on the KITTI 2015 dataset and 3rd on the Scene Flow dataset among all the published works.
Global Occlusion-Aware Transformer for Robust Stereo Matching
Dec 22, 2023Despite the remarkable progress facilitated by learning-based stereo-matching algorithms, the performance in the ill-conditioned regions, such as the occluded regions, remains a bottleneck. Due to the limited receptive field, existing CNN-based methods struggle to handle these ill-conditioned regions effectively. To address this issue, this paper introduces a novel attention-based stereo-matching network called Global Occlusion-Aware Transformer (GOAT) to exploit long-range dependency and occlusion-awareness global context for disparity estimation. In the GOAT architecture, a parallel disparity and occlusion estimation module PDO is proposed to estimate the initial disparity map and the occlusion mask using a parallel attention mechanism. To further enhance the disparity estimates in the occluded regions, an occlusion-aware global aggregation module (OGA) is proposed. This module aims to refine the disparity in the occluded regions by leveraging restricted global correlation within the focus scope of the occluded areas. Extensive experiments were conducted on several public benchmark datasets including SceneFlow, KITTI 2015, and Middlebury. The results show that the proposed GOAT demonstrates outstanding performance among all benchmarks, particularly in the occluded regions.
A Dataset and Baselines for Visual Question Answering on Art
Aug 28, 2020
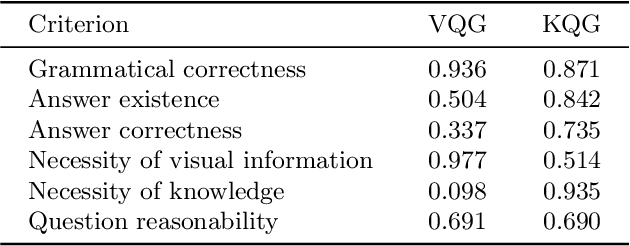
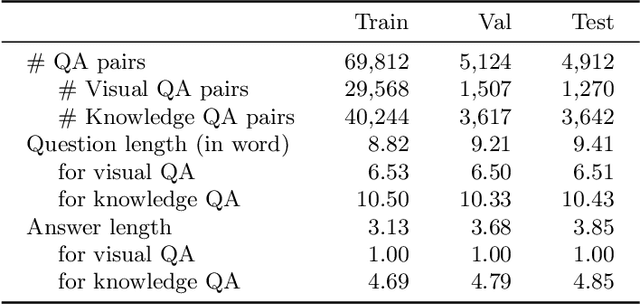
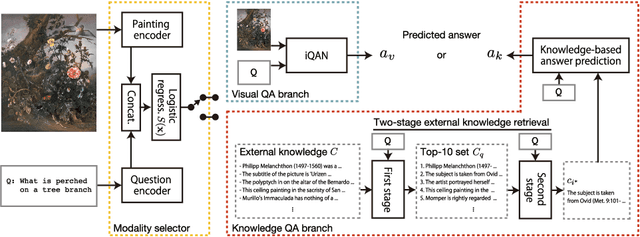
Answering questions related to art pieces (paintings) is a difficult task, as it implies the understanding of not only the visual information that is shown in the picture, but also the contextual knowledge that is acquired through the study of the history of art. In this work, we introduce our first attempt towards building a new dataset, coined AQUA (Art QUestion Answering). The question-answer (QA) pairs are automatically generated using state-of-the-art question generation methods based on paintings and comments provided in an existing art understanding dataset. The QA pairs are cleansed by crowdsourcing workers with respect to their grammatical correctness, answerability, and answers' correctness. Our dataset inherently consists of visual (painting-based) and knowledge (comment-based) questions. We also present a two-branch model as baseline, where the visual and knowledge questions are handled independently. We extensively compare our baseline model against the state-of-the-art models for question answering, and we provide a comprehensive study about the challenges and potential future directions for visual question answering on art.
SURREAL-System: Fully-Integrated Stack for Distributed Deep Reinforcement Learning
Oct 11, 2019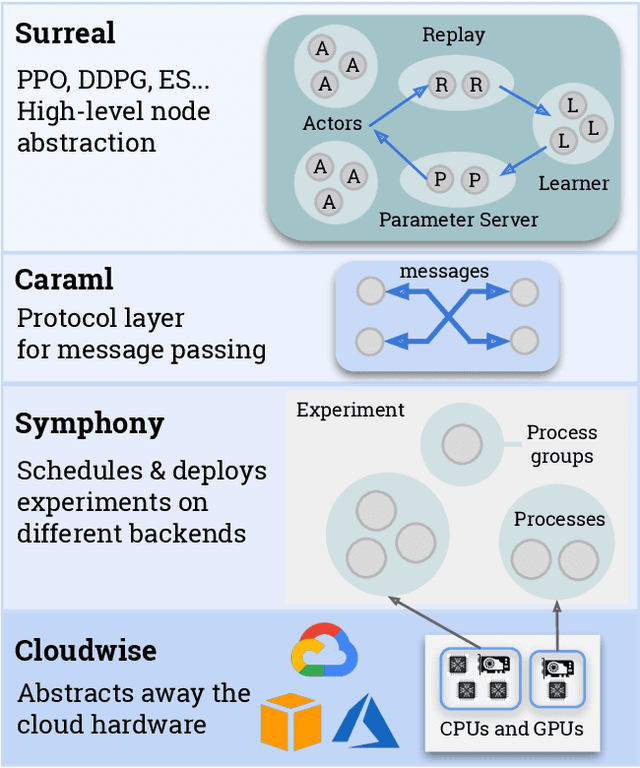

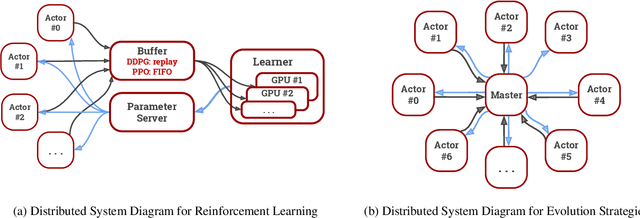
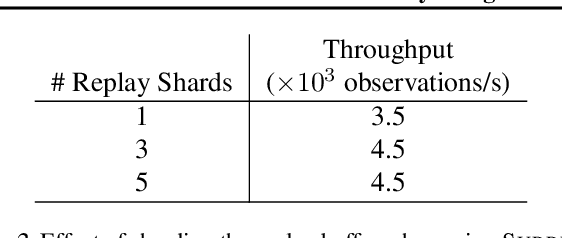
We present an overview of SURREAL-System, a reproducible, flexible, and scalable framework for distributed reinforcement learning (RL). The framework consists of a stack of four layers: Provisioner, Orchestrator, Protocol, and Algorithms. The Provisioner abstracts away the machine hardware and node pools across different cloud providers. The Orchestrator provides a unified interface for scheduling and deploying distributed algorithms by high-level description, which is capable of deploying to a wide range of hardware from a personal laptop to full-fledged cloud clusters. The Protocol provides network communication primitives optimized for RL. Finally, the SURREAL algorithms, such as Proximal Policy Optimization (PPO) and Evolution Strategies (ES), can easily scale to 1000s of CPU cores and 100s of GPUs. The learning performances of our distributed algorithms establish new state-of-the-art on OpenAI Gym and Robotics Suites tasks.
Question Answering via Web Extracted Tables and Pipelined Models
Apr 16, 2019
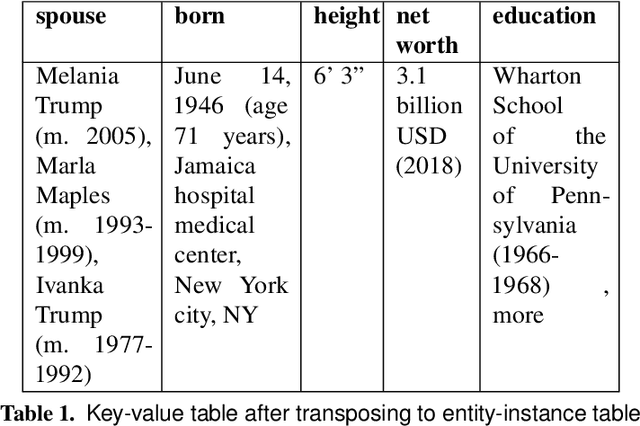
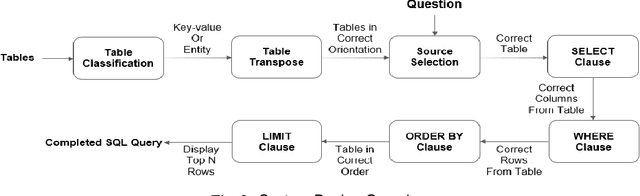
In this paper, we describe a dataset and baseline result for a question answering that utilizes web tables. It contains commonly asked questions on the web and their corresponding answers found in tables on websites. Our dataset is novel in that every question is paired with a table of a different signature. In particular, the dataset contains two classes of tables: entity-instance tables and the key-value tables. Each QA instance comprises a table of either kind, a natural language question, and a corresponding structured SQL query. We build our model by dividing question answering into several tasks, including table retrieval and question element classification, and conduct experiments to measure the performance of each task. We extract various features specific to each task and compose a full pipeline which constructs the SQL query from its parts. Our work provides qualitative results and error analysis for each task, and identifies in detail the reasoning required to generate SQL expressions from natural language questions. This analysis of reasoning informs future models based on neural machine learning.