 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergistic Integration of Large Language Models and Cognitive Architectures for Robust AI: An Exploratory Analysis
Sep 05, 2023



This paper explores the integration of two AI subdisciplines employed in the development of artificial agents that exhibit intelligent behavior: Large Language Models (LLMs) and Cognitive Architectures (CAs). We present three integration approaches, each grounded in theoretical models and supported by preliminary empirical evidence. The modular approach, which introduces four models with varying degrees of integration, makes use of chain-of-thought prompting, and draws inspiration from augmented LLMs, the Common Model of Cognition, and the simulation theory of cognition. The agency approach, motivated by the Society of Mind theory and the LIDA cognitive architecture, proposes the formation of agent collections that interact at micro and macro cognitive levels, driven by either LLMs or symbolic components. The neuro-symbolic approach, which takes inspiration from the CLARION cognitive architecture, proposes a model where bottom-up learning extracts symbolic representations from an LLM layer and top-down guidance utilizes symbolic representations to direct prompt engineering in the LLM layer. These approaches aim to harness the strengths of both LLMs and CAs, while mitigating their weaknesses, thereby advancing the development of more robust AI systems. We discuss the tradeoffs and challenges associated with each approach.
Supervised Contextual Embeddings for Transfer Learning in Natural Language Processing Tasks
Jun 28, 2019


Pre-trained word embeddings are the primary method for transfer learning in several Natural Language Processing (NLP) tasks. Recent works have focused on using unsupervised techniques such as language modeling to obtain these embeddings. In contrast, this work focuses on extracting representations from multiple pre-trained supervised models, which enriches word embeddings with task and domain specific knowledge. Experiments performed in cross-task, cross-domain and cross-lingual settings indicate that such supervised embeddings are helpful, especially in the low-resource setting, but the extent of gains is dependent on the nature of the task and domain. We make our code publicly available.
Question Answering via Web Extracted Tables and Pipelined Models
Apr 16, 2019
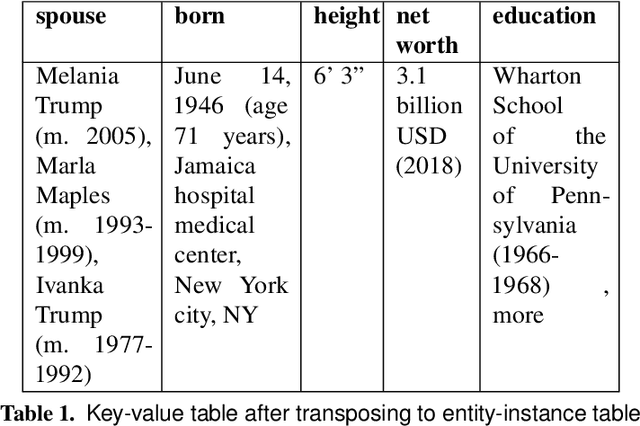
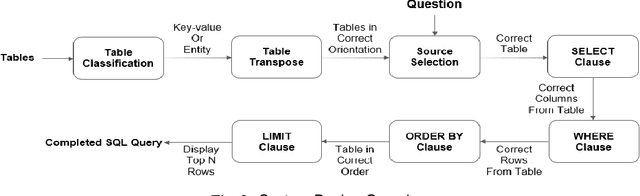
In this paper, we describe a dataset and baseline result for a question answering that utilizes web tables. It contains commonly asked questions on the web and their corresponding answers found in tables on websites. Our dataset is novel in that every question is paired with a table of a different signature. In particular, the dataset contains two classes of tables: entity-instance tables and the key-value tables. Each QA instance comprises a table of either kind, a natural language question, and a corresponding structured SQL query. We build our model by dividing question answering into several tasks, including table retrieval and question element classification, and conduct experiments to measure the performance of each task. We extract various features specific to each task and compose a full pipeline which constructs the SQL query from its parts. Our work provides qualitative results and error analysis for each task, and identifies in detail the reasoning required to generate SQL expressions from natural language questions. This analysis of reasoning informs future models based on neural machine learning.
Retrieval-Based Neural Code Generation
Aug 29, 2018

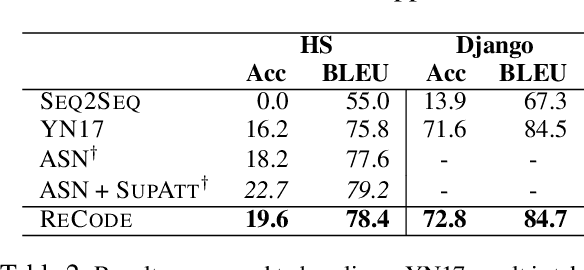

In models to generate program source code from natural language, representing this code in a tree structure has been a common approach. However, existing methods often fail to generate complex code correctly due to a lack of ability to memorize large and complex structures. We introduce ReCode, a method based on subtree retrieval that makes it possible to explicitly reference existing code examples within a neural code generation model. First, we retrieve sentences that are similar to input sentences using a dynamic-programming-based sentence similarity scoring method. Next, we extract n-grams of action sequences that build the associated abstract syntax tree. Finally, we increase the probability of actions that cause the retrieved n-gram action subtree to be in the predicted code. We show that our approach improves the performance on two code generation tasks by up to +2.6 BLEU.