 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre LLM Agents Behaviorally Coherent? Latent Profiles for Social Simulation
Sep 03, 2025The impressive capabilities of Large Language Models (LLMs) have fueled the notion that synthetic agents can serve as substitutes for real participants in human-subject research. In an effort to evaluate the merits of this claim, social science researchers have largely focused on whether LLM-generated survey data corresponds to that of a human counterpart whom the LLM is prompted to represent. In contrast, we address a more fundamental question: Do agents maintain internal consistency, retaining similar behaviors when examined under different experimental settings? To this end, we develop a study designed to (a) reveal the agent's internal state and (b) examine agent behavior in a basic dialogue setting. This design enables us to explore a set of behavioral hypotheses to assess whether an agent's conversation behavior is consistent with what we would expect from their revealed internal state. Our findings on these hypotheses show significant internal inconsistencies in LLMs across model families and at differing model sizes. Most importantly, we find that, although agents may generate responses matching those of their human counterparts, they fail to be internally consistent, representing a critical gap in their capabilities to accurately substitute for real participants in human-subject research. Our simulation code and data are publicly accessible.
Confidence Calibration and Rationalization for LLMs via Multi-Agent Deliberation
Apr 14, 2024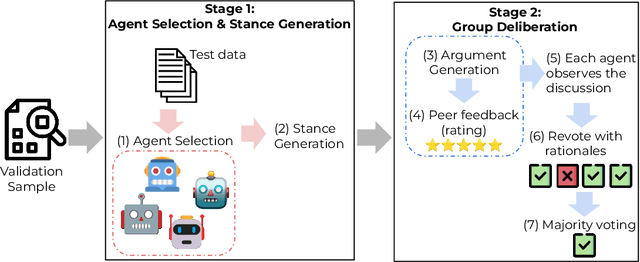


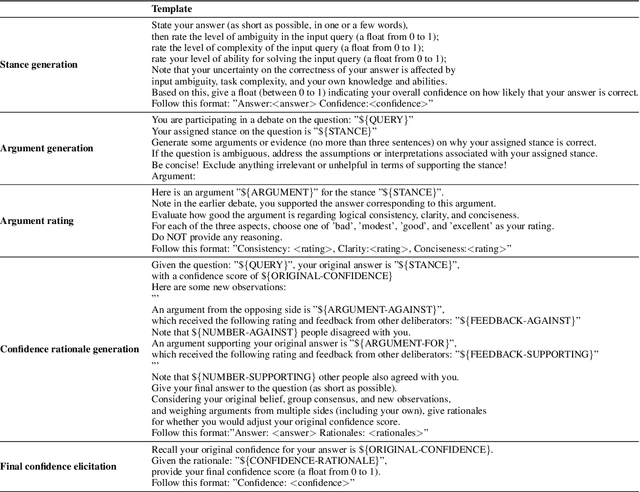
Uncertainty estimation is a significant issue for current large language models (LLMs) that are generally poorly calibrated and over-confident, especially with reinforcement learning from human feedback (RLHF). Unlike humans, whose decisions and confidences not only stem from intrinsic beliefs but can also be adjusted through daily observations, existing calibration methods for LLMs focus on estimating or eliciting individual confidence without taking full advantage of the "Collective Wisdom": the interaction among multiple LLMs that can collectively improve both accuracy and calibration. In this work, we propose Collaborative Calibration, a post-hoc training-free calibration strategy that leverages the collaborative and expressive capabilities of multiple tool-augmented LLM agents in a simulated group deliberation process. We demonstrate the effectiveness of Collaborative Calibration on generative QA tasks across various domains, showing its potential in harnessing the rationalization of collectively calibrated confidence assessments and improving the reliability of model predictions.
Chain-of-Instructions: Compositional Instruction Tuning on Large Language Models
Feb 18, 2024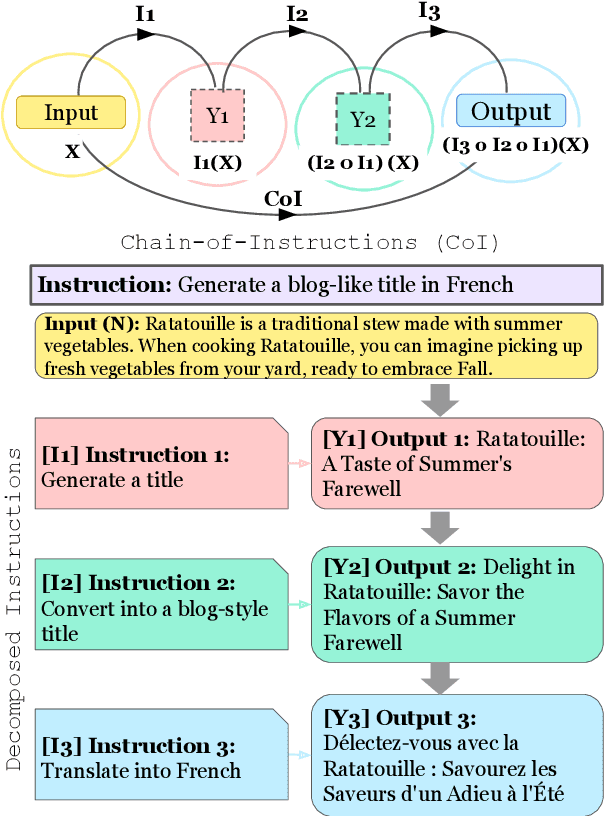
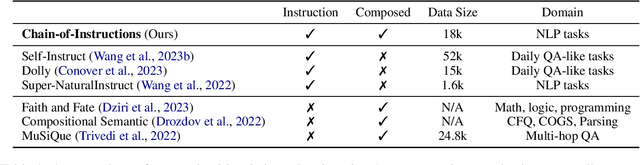

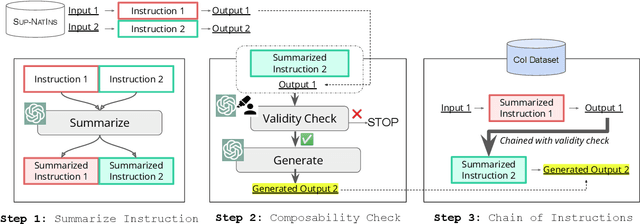
Fine-tuning large language models (LLMs) with a collection of large and diverse instructions has improved the model's generalization to different tasks, even for unseen tasks. However, most existing instruction datasets include only single instructions, and they struggle to follow complex instructions composed of multiple subtasks (Wang et al., 2023a). In this work, we propose a novel concept of compositional instructions called chain-of-instructions (CoI), where the output of one instruction becomes an input for the next like a chain. Unlike the conventional practice of solving single instruction tasks, our proposed method encourages a model to solve each subtask step by step until the final answer is reached. CoI-tuning (i.e., fine-tuning with CoI instructions) improves the model's ability to handle instructions composed of multiple subtasks. CoI-tuned models also outperformed baseline models on multilingual summarization, demonstrating the generalizability of CoI models on unseen composite downstream tasks.
Under the Surface: Tracking the Artifactuality of LLM-Generated Data
Jan 30, 2024



This work delves into the expanding role of large language models (LLMs) in generating artificial data. LLMs are increasingly employed to create a variety of outputs, including annotations, preferences, instruction prompts, simulated dialogues, and free text. As these forms of LLM-generated data often intersect in their application, they exert mutual influence on each other and raise significant concerns about the quality and diversity of the artificial data incorporated into training cycles, leading to an artificial data ecosystem. To the best of our knowledge, this is the first study to aggregate various types of LLM-generated text data, from more tightly constrained data like "task labels" to more lightly constrained "free-form text". We then stress test the quality and implications of LLM-generated artificial data, comparing it with human data across various existing benchmarks. Despite artificial data's capability to match human performance, this paper reveals significant hidden disparities, especially in complex tasks where LLMs often miss the nuanced understanding of intrinsic human-generated content. This study critically examines diverse LLM-generated data and emphasizes the need for ethical practices in data creation and when using LLMs. It highlights the LLMs' shortcomings in replicating human traits and behaviors, underscoring the importance of addressing biases and artifacts produced in LLM-generated content for future research and development. All data and code are available on our project page.
How Far Can We Extract Diverse Perspectives from Large Language Models? Criteria-Based Diversity Prompting!
Nov 16, 2023



Collecting diverse human data on subjective NLP topics is costly and challenging. As Large Language Models (LLMs) have developed human-like capabilities, there is a recent trend in collaborative efforts between humans and LLMs for generating diverse data, offering potential scalable and efficient solutions. However, the extent of LLMs' capability to generate diverse perspectives on subjective topics remains an unexplored question. In this study, we investigate LLMs' capacity for generating diverse perspectives and rationales on subjective topics, such as social norms and argumentative texts. We formulate this problem as diversity extraction in LLMs and propose a criteria-based prompting technique to ground diverse opinions and measure perspective diversity from the generated criteria words. Our results show that measuring semantic diversity through sentence embeddings and distance metrics is not enough to measure perspective diversity. To see how far we can extract diverse perspectives from LLMs, or called diversity coverage, we employ a step-by-step recall prompting for generating more outputs from the model in an iterative manner. As we apply our prompting method to other tasks (hate speech labeling and story continuation), indeed we find that LLMs are able to generate diverse opinions according to the degree of task subjectivity.
Werewolf Among Us: A Multimodal Dataset for Modeling Persuasion Behaviors in Social Deduction Games
Dec 16, 2022
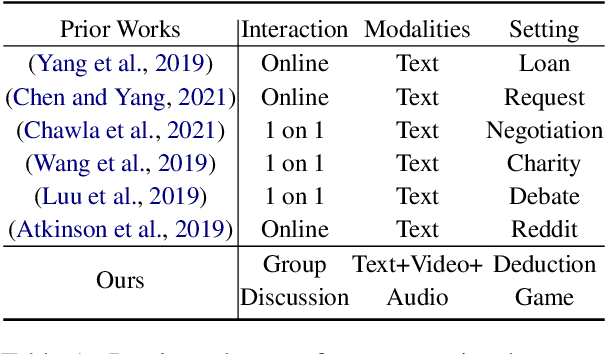


Persuasion modeling is a key building block for conversational agents. Existing works in this direction are limited to analyzing textual dialogue corpus. We argue that visual signals also play an important role in understanding human persuasive behaviors. In this paper, we introduce the first multimodal dataset for modeling persuasion behaviors. Our dataset includes 199 dialogue transcriptions and videos captured in a multi-player social deduction game setting, 26,647 utterance level annotations of persuasion strategy, and game level annotations of deduction game outcomes. We provide extensive experiments to show how dialogue context and visual signals benefit persuasion strategy prediction. We also explore the generalization ability of language models for persuasion modeling and the role of persuasion strategies in predicting social deduction game outcomes. Our dataset, code, and models can be found at https://persuasion-deductiongame.socialai-data.org.
Modeling Motivational Interviewing Strategies On An Online Peer-to-Peer Counseling Platform
Nov 09, 2022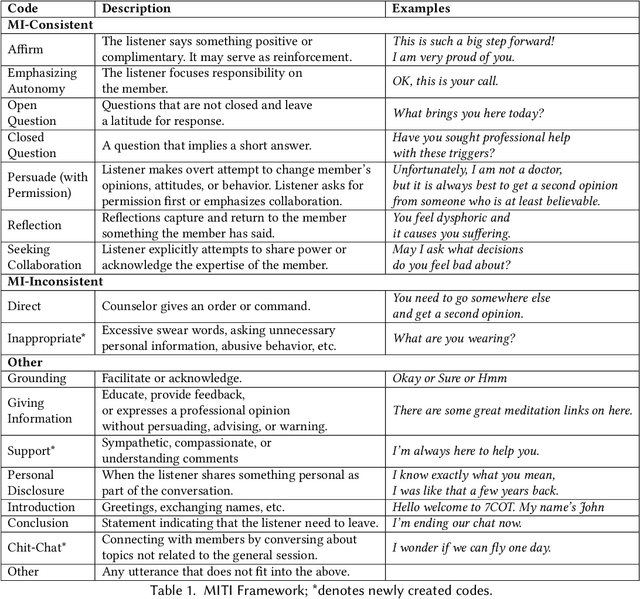



Millions of people participate in online peer-to-peer support sessions, yet there has been little prior research on systematic psychology-based evaluations of fine-grained peer-counselor behavior in relation to client satisfaction. This paper seeks to bridge this gap by mapping peer-counselor chat-messages to motivational interviewing (MI) techniques. We annotate 14,797 utterances from 734 chat conversations using 17 MI techniques and introduce four new interviewing codes such as chit-chat and inappropriate to account for the unique conversational patterns observed on online platforms. We automate the process of labeling peer-counselor responses to MI techniques by fine-tuning large domain-specific language models and then use these automated measures to investigate the behavior of the peer counselors via correlational studies. Specifically, we study the impact of MI techniques on the conversation ratings to investigate the techniques that predict clients' satisfaction with their counseling sessions. When counselors use techniques such as reflection and affirmation, clients are more satisfied. Examining volunteer counselors' change in usage of techniques suggest that counselors learn to use more introduction and open questions as they gain experience. This work provides a deeper understanding of the use of motivational interviewing techniques on peer-to-peer counselor platforms and sheds light on how to build better training programs for volunteer counselors on online platforms.
StyLEx: Explaining Styles with Lexicon-Based Human Perception
Oct 14, 2022
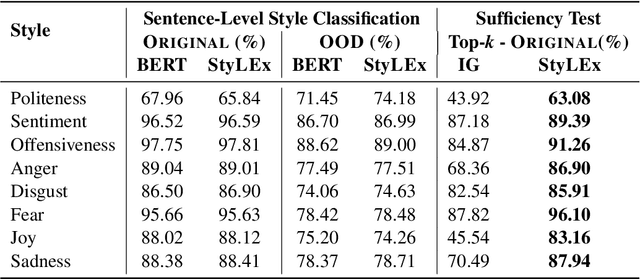
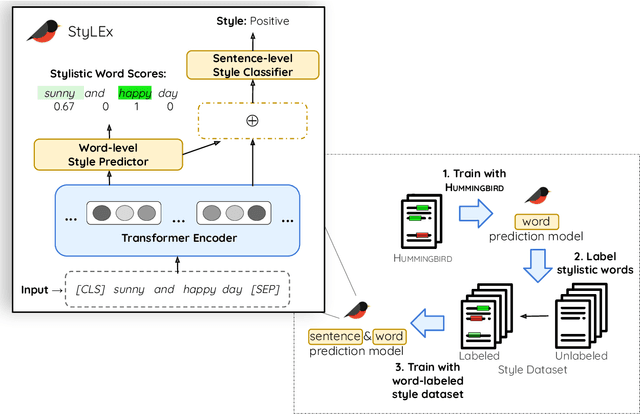
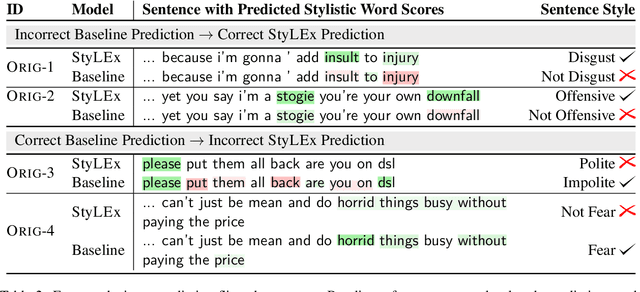
Style plays a significant role in how humans express themselves and communicate with others. Large pre-trained language models produce impressive results on various style classification tasks. However, they often learn spurious domain-specific words to make predictions. This incorrect word importance learned by the model often leads to ambiguous token-level explanations which do not align with human perception of linguistic styles. To tackle this challenge, we introduce StyLEx, a model that learns annotated human perceptions of stylistic lexica and uses these stylistic words as additional information for predicting the style of a sentence. Our experiments show that StyLEx can provide human-like stylistic lexical explanations without sacrificing the performance of sentence-level style prediction on both original and out-of-domain datasets. Explanations from StyLEx show higher sufficiency, and plausibility when compared to human annotations, and are also more understandable by human judges compared to the existing widely-used saliency baseline.
Does BERT Learn as Humans Perceive? Understanding Linguistic Styles through Lexica
Sep 06, 2021
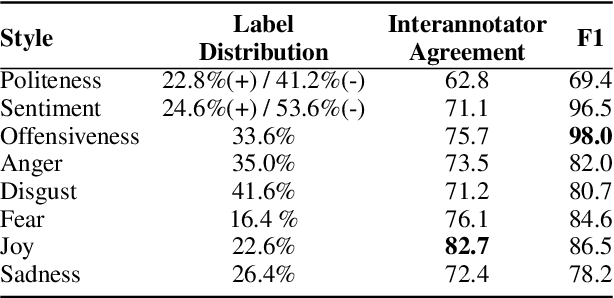


People convey their intention and attitude through linguistic styles of the text that they write. In this study, we investigate lexicon usages across styles throughout two lenses: human perception and machine word importance, since words differ in the strength of the stylistic cues that they provide. To collect labels of human perception, we curate a new dataset, Hummingbird, on top of benchmarking style datasets. We have crowd workers highlight the representative words in the text that makes them think the text has the following styles: politeness, sentiment, offensiveness, and five emotion types. We then compare these human word labels with word importance derived from a popular fine-tuned style classifier like BERT. Our results show that the BERT often finds content words not relevant to the target style as important words used in style prediction, but humans do not perceive the same way even though for some styles (e.g., positive sentiment and joy) human- and machine-identified words share significant overlap for some styles.
DEUX: An Attribute-Guided Framework for Sociable Recommendation Dialog Systems
Apr 16, 2021

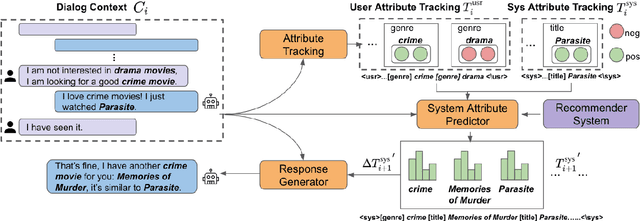

It is important for sociable recommendation dialog systems to perform as both on-task content and social content to engage users and gain their favor. In addition to understand the user preferences and provide a satisfying recommendation, such systems must be able to generate coherent and natural social conversations to the user. Traditional dialog state tracking cannot be applied to such systems because it does not track the attributes in the social content. To address this challenge, we propose DEUX, a novel attribute-guided framework to create better user experiences while accomplishing a movie recommendation task. DEUX has a module that keeps track of the movie attributes (e.g., favorite genres, actors,etc.) in both user utterances and system responses. This allows the system to introduce new movie attributes in its social content. Then, DEUX has multiple values for the same attribute type which suits the recommendation task since a user may like multiple genres, for instance. Experiments suggest that DEUX outperforms all the baselines on being more consistent, fitting the user preferences better, and providing a more engaging chat experience. Our approach can be used for any similar problems of sociable task-oriented dialog system.