 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnder the Surface: Tracking the Artifactuality of LLM-Generated Data
Jan 30, 2024



This work delves into the expanding role of large language models (LLMs) in generating artificial data. LLMs are increasingly employed to create a variety of outputs, including annotations, preferences, instruction prompts, simulated dialogues, and free text. As these forms of LLM-generated data often intersect in their application, they exert mutual influence on each other and raise significant concerns about the quality and diversity of the artificial data incorporated into training cycles, leading to an artificial data ecosystem. To the best of our knowledge, this is the first study to aggregate various types of LLM-generated text data, from more tightly constrained data like "task labels" to more lightly constrained "free-form text". We then stress test the quality and implications of LLM-generated artificial data, comparing it with human data across various existing benchmarks. Despite artificial data's capability to match human performance, this paper reveals significant hidden disparities, especially in complex tasks where LLMs often miss the nuanced understanding of intrinsic human-generated content. This study critically examines diverse LLM-generated data and emphasizes the need for ethical practices in data creation and when using LLMs. It highlights the LLMs' shortcomings in replicating human traits and behaviors, underscoring the importance of addressing biases and artifacts produced in LLM-generated content for future research and development. All data and code are available on our project page.
Annotation Imputation to Individualize Predictions: Initial Studies on Distribution Dynamics and Model Predictions
May 24, 2023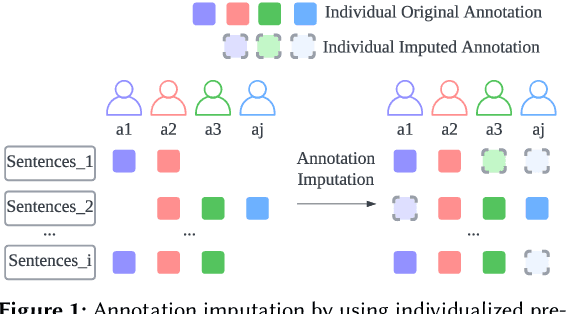
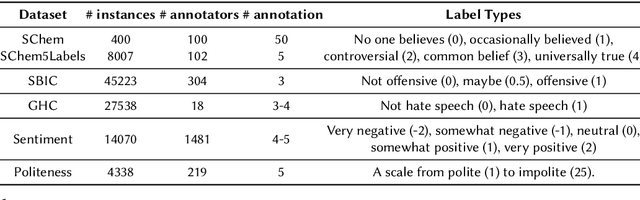
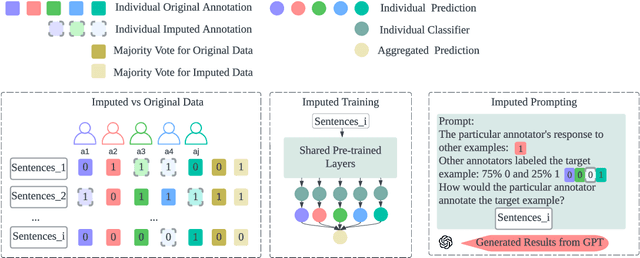

Annotating data via crowdsourcing is time-consuming and expensive. Owing to these costs, dataset creators often have each annotator label only a small subset of the data. This leads to sparse datasets with examples that are marked by few annotators; if an annotator is not selected to label an example, their opinion regarding it is lost. This is especially concerning for subjective NLP datasets where there is no correct label: people may have different valid opinions. Thus, we propose using imputation methods to restore the opinions of all annotators for all examples, creating a dataset that does not leave out any annotator's view. We then train and prompt models with data from the imputed dataset (rather than the original sparse dataset) to make predictions about majority and individual annotations. Unfortunately, the imputed data provided by our baseline methods does not improve predictions. However, through our analysis of it, we develop a strong understanding of how different imputation methods impact the original data in order to inform future imputation techniques. We make all of our code and data publicly available.
Quirk or Palmer: A Comparative Study of Modal Verb Frameworks with Annotated Datasets
Dec 20, 2022Modal verbs, such as "can", "may", and "must", are commonly used in daily communication to convey the speaker's perspective related to the likelihood and/or mode of the proposition. They can differ greatly in meaning depending on how they're used and the context of a sentence (e.g. "They 'must' help each other out." vs. "They 'must' have helped each other out.") Despite their practical importance in natural language understanding, linguists have yet to agree on a single, prominent framework for the categorization of modal verb senses. This lack of agreement stems from high degrees of flexibility and polysemy from the modal verbs, making it more difficult for researchers to incorporate insights from this family of words into their work. This work presents Moverb dataset, which consists of 27,240 annotations of modal verb senses over 4,540 utterances containing one or more sentences from social conversations. Each utterance is annotated by three annotators using two different theoretical frameworks (i.e., Quirk and Palmer) of modal verb senses. We observe that both frameworks have similar inter-annotator agreements, despite having different numbers of sense types (8 for Quirk and 3 for Palmer). With the RoBERTa-based classifiers fine-tuned on \dataset, we achieve F1 scores of 82.2 and 78.3 on Quirk and Palmer, respectively, showing that modal verb sense disambiguation is not a trivial task. Our dataset will be publicly available with our final version.