 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotation Imputation to Individualize Predictions: Initial Studies on Distribution Dynamics and Model Predictions
Paper and Code
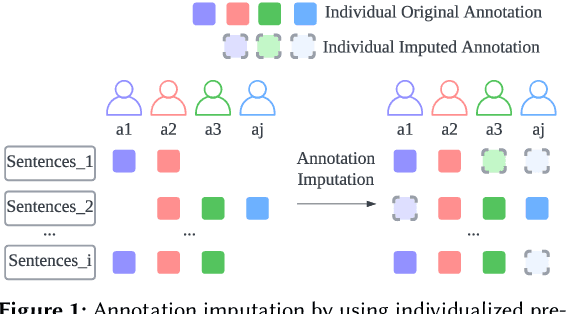
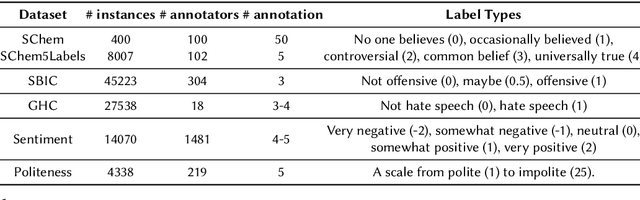
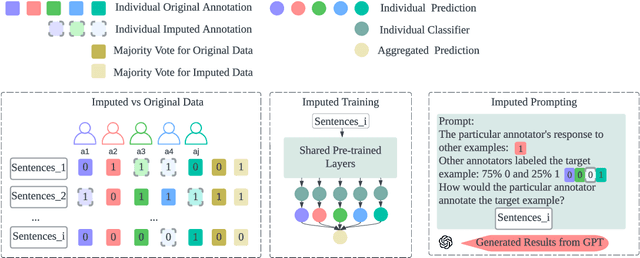

Annotating data via crowdsourcing is time-consuming and expensive. Owing to these costs, dataset creators often have each annotator label only a small subset of the data. This leads to sparse datasets with examples that are marked by few annotators; if an annotator is not selected to label an example, their opinion regarding it is lost. This is especially concerning for subjective NLP datasets where there is no correct label: people may have different valid opinions. Thus, we propose using imputation methods to restore the opinions of all annotators for all examples, creating a dataset that does not leave out any annotator's view. We then train and prompt models with data from the imputed dataset (rather than the original sparse dataset) to make predictions about majority and individual annotations. Unfortunately, the imputed data provided by our baseline methods does not improve predictions. However, through our analysis of it, we develop a strong understanding of how different imputation methods impact the original data in order to inform future imputation techniques. We make all of our code and data publicly available.