 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotation Imputation to Individualize Predictions: Initial Studies on Distribution Dynamics and Model Predictions
May 24, 2023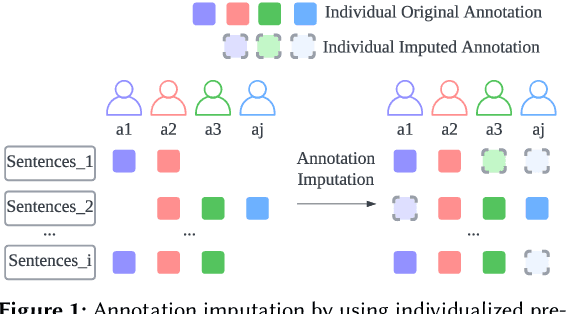
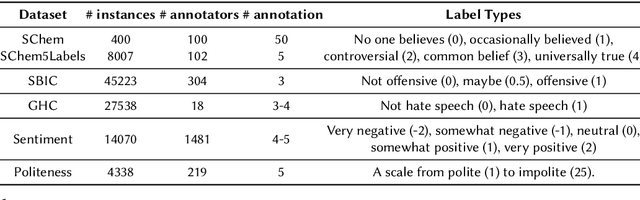
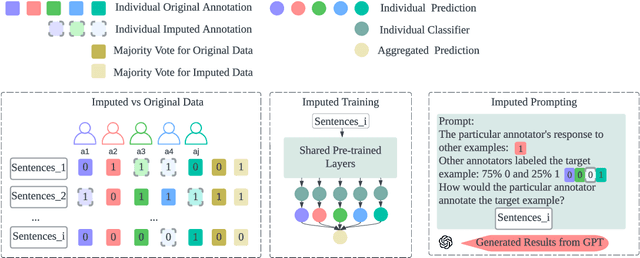

Annotating data via crowdsourcing is time-consuming and expensive. Owing to these costs, dataset creators often have each annotator label only a small subset of the data. This leads to sparse datasets with examples that are marked by few annotators; if an annotator is not selected to label an example, their opinion regarding it is lost. This is especially concerning for subjective NLP datasets where there is no correct label: people may have different valid opinions. Thus, we propose using imputation methods to restore the opinions of all annotators for all examples, creating a dataset that does not leave out any annotator's view. We then train and prompt models with data from the imputed dataset (rather than the original sparse dataset) to make predictions about majority and individual annotations. Unfortunately, the imputed data provided by our baseline methods does not improve predictions. However, through our analysis of it, we develop a strong understanding of how different imputation methods impact the original data in order to inform future imputation techniques. We make all of our code and data publicly available.
SIERRA: A Modular Framework for Research Automation
Mar 03, 2022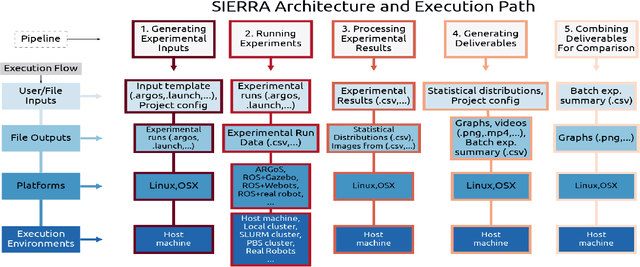
Modern intelligent systems researchers employ the scientific method: they form hypotheses about system behavior, and then run experiments using one or more independent variables to test their hypotheses. We present SIERRA, a novel framework structured around that idea for accelerating research developments and improving reproducibility of results. SIERRA makes it easy to quickly specify the independent variable(s) for an experiment, generate experimental inputs, automatically run the experiment, and process the results to generate deliverables such as graphs and videos. SIERRA provides reproducible automation independent of the execution environment (HPC hardware, real robots, etc.) and targeted platform (arbitrary simulator or real robots), enabling exact experiment replication (up to the limit of the execution environment and platform). It employs a deeply modular approach that allows easy customization and extension of automation for the needs of individual researchers, thereby eliminating manual experiment configuration and result processing via throw-away scripts.