 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes BERT Learn as Humans Perceive? Understanding Linguistic Styles through Lexica
Paper and Code

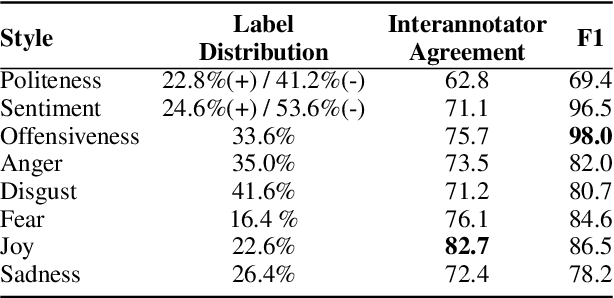


People convey their intention and attitude through linguistic styles of the text that they write. In this study, we investigate lexicon usages across styles throughout two lenses: human perception and machine word importance, since words differ in the strength of the stylistic cues that they provide. To collect labels of human perception, we curate a new dataset, Hummingbird, on top of benchmarking style datasets. We have crowd workers highlight the representative words in the text that makes them think the text has the following styles: politeness, sentiment, offensiveness, and five emotion types. We then compare these human word labels with word importance derived from a popular fine-tuned style classifier like BERT. Our results show that the BERT often finds content words not relevant to the target style as important words used in style prediction, but humans do not perceive the same way even though for some styles (e.g., positive sentiment and joy) human- and machine-identified words share significant overlap for some styles.