 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProGraph-R1: Progress-aware Reinforcement Learning for Graph Retrieval Augmented Generation
Jan 25, 2026Graph Retrieval-Augmented Generation (GraphRAG) has been successfully applied in various knowledge-intensive question answering tasks by organizing external knowledge into structured graphs of entities and relations. It enables large language models (LLMs) to perform complex reasoning beyond text-chunk retrieval. Recent works have employed reinforcement learning (RL) to train agentic GraphRAG frameworks that perform iterative interactions between LLMs and knowledge graphs. However, existing RL-based frameworks such as Graph-R1 suffer from two key limitations: (1) they primarily depend on semantic similarity for retrieval, often overlooking the underlying graph structure, and (2) they rely on sparse, outcome-level rewards, failing to capture the quality of intermediate retrieval steps and their dependencies. To address these limitations, we propose ProGraph-R1, a progress-aware agentic framework for graph-based retrieval and multi-step reasoning. ProGraph-R1 introduces a structure-aware hypergraph retrieval mechanism that jointly considers semantic relevance and graph connectivity, encouraging coherent traversal along multi-hop reasoning paths. We also design a progress-based step-wise policy optimization, which provides dense learning signals by modulating advantages according to intermediate reasoning progress within a graph, rather than relying solely on final outcomes. Experiments on multi-hop question answering benchmarks demonstrate that ProGraph-R1 consistently improves reasoning accuracy and generation quality over existing GraphRAG methods.
Align to Structure: Aligning Large Language Models with Structural Information
Apr 04, 2025Generating long, coherent text remains a challenge for large language models (LLMs), as they lack hierarchical planning and structured organization in discourse generation. We introduce Structural Alignment, a novel method that aligns LLMs with human-like discourse structures to enhance long-form text generation. By integrating linguistically grounded discourse frameworks into reinforcement learning, our approach guides models to produce coherent and well-organized outputs. We employ a dense reward scheme within a Proximal Policy Optimization framework, assigning fine-grained, token-level rewards based on the discourse distinctiveness relative to human writing. Two complementary reward models are evaluated: the first improves readability by scoring surface-level textual features to provide explicit structuring, while the second reinforces deeper coherence and rhetorical sophistication by analyzing global discourse patterns through hierarchical discourse motifs, outperforming both standard and RLHF-enhanced models in tasks such as essay generation and long-document summarization. All training data and code will be publicly shared at https://github.com/minnesotanlp/struct_align.
MAPoRL: Multi-Agent Post-Co-Training for Collaborative Large Language Models with Reinforcement Learning
Feb 25, 2025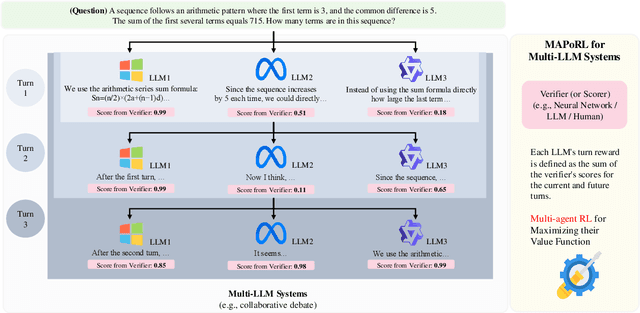
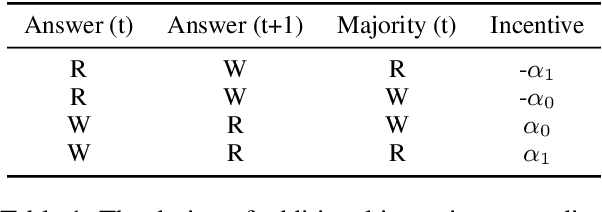
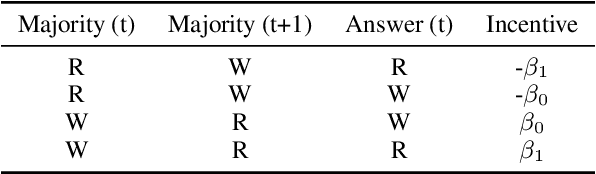
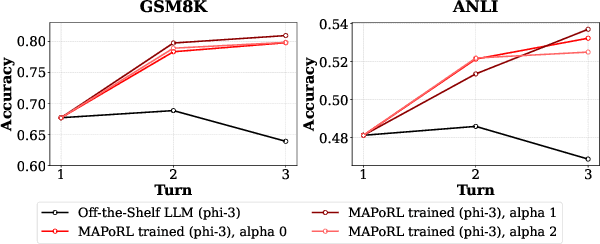
Leveraging multiple large language models (LLMs) to build collaborative multi-agentic workflows has demonstrated significant potential. However, most previous studies focus on prompting the out-of-the-box LLMs, relying on their innate capability for collaboration, which may not improve LLMs' performance as shown recently. In this paper, we introduce a new post-training paradigm MAPoRL (Multi-Agent Post-co-training for collaborative LLMs with Reinforcement Learning), to explicitly elicit the collaborative behaviors and further unleash the power of multi-agentic LLM frameworks. In MAPoRL, multiple LLMs first generate their own responses independently and engage in a multi-turn discussion to collaboratively improve the final answer. In the end, a MAPoRL verifier evaluates both the answer and the discussion, by assigning a score that verifies the correctness of the answer, while adding incentives to encourage corrective and persuasive discussions. The score serves as the co-training reward, and is then maximized through multi-agent RL. Unlike existing LLM post-training paradigms, MAPoRL advocates the co-training of multiple LLMs together using RL for better generalization. Accompanied by analytical insights, our experiments demonstrate that training individual LLMs alone is insufficient to induce effective collaboration. In contrast, multi-agent co-training can boost the collaboration performance across benchmarks, with generalization to unseen domains.
Generative Subgraph Retrieval for Knowledge Graph-Grounded Dialog Generation
Oct 12, 2024Knowledge graph-grounded dialog generation requires retrieving a dialog-relevant subgraph from the given knowledge base graph and integrating it with the dialog history. Previous works typically represent the graph using an external encoder, such as graph neural networks, and retrieve relevant triplets based on the similarity between single-vector representations of triplets and the dialog history. However, these external encoders fail to leverage the rich knowledge of pretrained language models, and the retrieval process is also suboptimal due to the information bottleneck caused by the single-vector abstraction of the dialog history. In this work, we propose Dialog generation with Generative Subgraph Retrieval (DialogGSR), which retrieves relevant knowledge subgraphs by directly generating their token sequences on top of language models. For effective generative subgraph retrieval, we introduce two key methods: (i) structure-aware knowledge graph linearization with self-supervised graph-specific tokens and (ii) graph-constrained decoding utilizing graph structural proximity-based entity informativeness scores for valid and relevant generative retrieval. DialogGSR achieves state-of-the-art performance in knowledge graph-grounded dialog generation, as demonstrated on OpenDialKG and KOMODIS datasets.
Chain-of-Instructions: Compositional Instruction Tuning on Large Language Models
Feb 18, 2024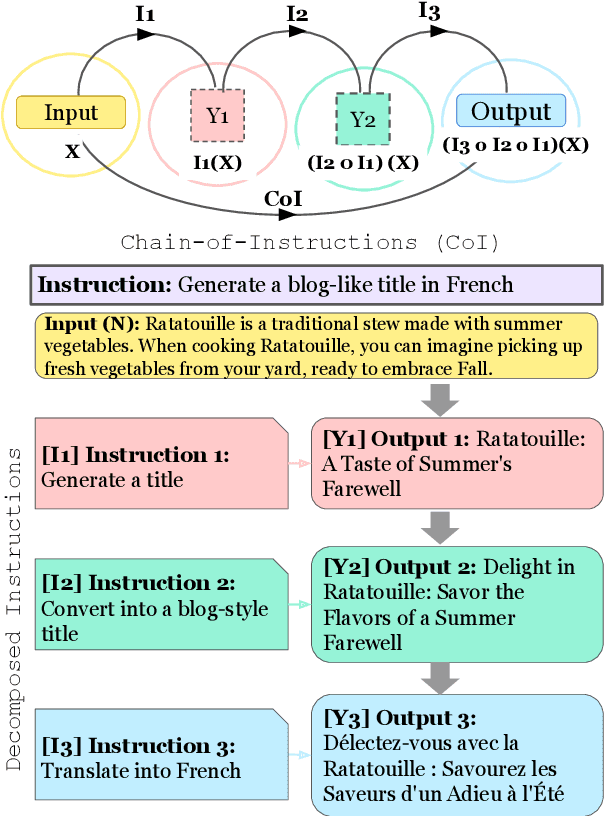

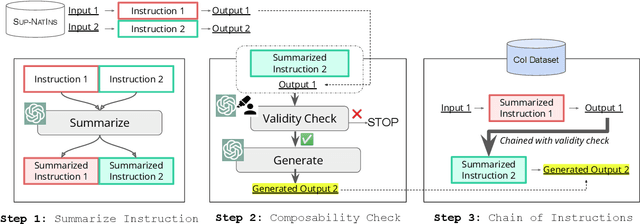
Fine-tuning large language models (LLMs) with a collection of large and diverse instructions has improved the model's generalization to different tasks, even for unseen tasks. However, most existing instruction datasets include only single instructions, and they struggle to follow complex instructions composed of multiple subtasks (Wang et al., 2023a). In this work, we propose a novel concept of compositional instructions called chain-of-instructions (CoI), where the output of one instruction becomes an input for the next like a chain. Unlike the conventional practice of solving single instruction tasks, our proposed method encourages a model to solve each subtask step by step until the final answer is reached. CoI-tuning (i.e., fine-tuning with CoI instructions) improves the model's ability to handle instructions composed of multiple subtasks. CoI-tuned models also outperformed baseline models on multilingual summarization, demonstrating the generalizability of CoI models on unseen composite downstream tasks.
II-MMR: Identifying and Improving Multi-modal Multi-hop Reasoning in Visual Question Answering
Feb 16, 2024



Visual Question Answering (VQA) often involves diverse reasoning scenarios across Vision and Language (V&L). Most prior VQA studies, however, have merely focused on assessing the model's overall accuracy without evaluating it on different reasoning cases. Furthermore, some recent works observe that conventional Chain-of-Thought (CoT) prompting fails to generate effective reasoning for VQA, especially for complex scenarios requiring multi-hop reasoning. In this paper, we propose II-MMR, a novel idea to identify and improve multi-modal multi-hop reasoning in VQA. In specific, II-MMR takes a VQA question with an image and finds a reasoning path to reach its answer using two novel language promptings: (i) answer prediction-guided CoT prompt, or (ii) knowledge triplet-guided prompt. II-MMR then analyzes this path to identify different reasoning cases in current VQA benchmarks by estimating how many hops and what types (i.e., visual or beyond-visual) of reasoning are required to answer the question. On popular benchmarks including GQA and A-OKVQA, II-MMR observes that most of their VQA questions are easy to answer, simply demanding "single-hop" reasoning, whereas only a few questions require "multi-hop" reasoning. Moreover, while the recent V&L model struggles with such complex multi-hop reasoning questions even using the traditional CoT method, II-MMR shows its effectiveness across all reasoning cases in both zero-shot and fine-tuning settings.
Graph-Guided Reasoning for Multi-Hop Question Answering in Large Language Models
Nov 16, 2023



Chain-of-Thought (CoT) prompting has boosted the multi-step reasoning capabilities of Large Language Models (LLMs) by generating a series of rationales before the final answer. We analyze the reasoning paths generated by CoT and find two issues in multi-step reasoning: (i) Generating rationales irrelevant to the question, (ii) Unable to compose subquestions or queries for generating/retrieving all the relevant information. To address them, we propose a graph-guided CoT prompting method, which guides the LLMs to reach the correct answer with graph representation/verification steps. Specifically, we first leverage LLMs to construct a "question/rationale graph" by using knowledge extraction prompting given the initial question and the rationales generated in the previous steps. Then, the graph verification step diagnoses the current rationale triplet by comparing it with the existing question/rationale graph to filter out irrelevant rationales and generate follow-up questions to obtain relevant information. Additionally, we generate CoT paths that exclude the extracted graph information to represent the context information missed from the graph extraction. Our graph-guided reasoning method shows superior performance compared to previous CoT prompting and the variants on multi-hop question answering benchmark datasets.
Cluster-Guided Label Generation in Extreme Multi-Label Classification
Feb 17, 2023For extreme multi-label classification (XMC), existing classification-based models poorly perform for tail labels and often ignore the semantic relations among labels, like treating "Wikipedia" and "Wiki" as independent and separate labels. In this paper, we cast XMC as a generation task (XLGen), where we benefit from pre-trained text-to-text models. However, generating labels from the extremely large label space is challenging without any constraints or guidance. We, therefore, propose to guide label generation using label cluster information to hierarchically generate lower-level labels. We also find that frequency-based label ordering and using decoding ensemble methods are critical factors for the improvements in XLGen. XLGen with cluster guidance significantly outperforms the classification and generation baselines on tail labels, and also generally improves the overall performance in four popular XMC benchmarks. In human evaluation, we also find XLGen generates unseen but plausible labels. Our code is now available at https://github.com/alexa/xlgen-eacl-2023.
Deciding Whether to Ask Clarifying Questions in Large-Scale Spoken Language Understanding
Sep 25, 2021
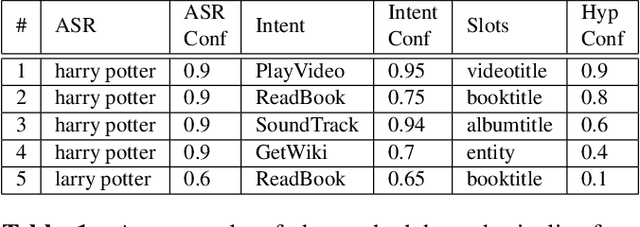

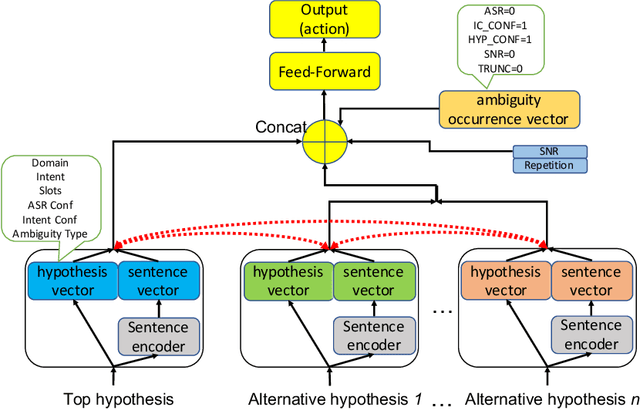
A large-scale conversational agent can suffer from understanding user utterances with various ambiguities such as ASR ambiguity, intent ambiguity, and hypothesis ambiguity. When ambiguities are detected, the agent should engage in a clarifying dialog to resolve the ambiguities before committing to actions. However, asking clarifying questions for all the ambiguity occurrences could lead to asking too many questions, essentially hampering the user experience. To trigger clarifying questions only when necessary for the user satisfaction, we propose a neural self-attentive model that leverages the hypotheses with ambiguities and contextual signals. We conduct extensive experiments on five common ambiguity types using real data from a large-scale commercial conversational agent and demonstrate significant improvement over a set of baseline approaches.
Pseudo Labeling and Negative Feedback Learning for Large-scale Multi-label Domain Classification
Mar 08, 2020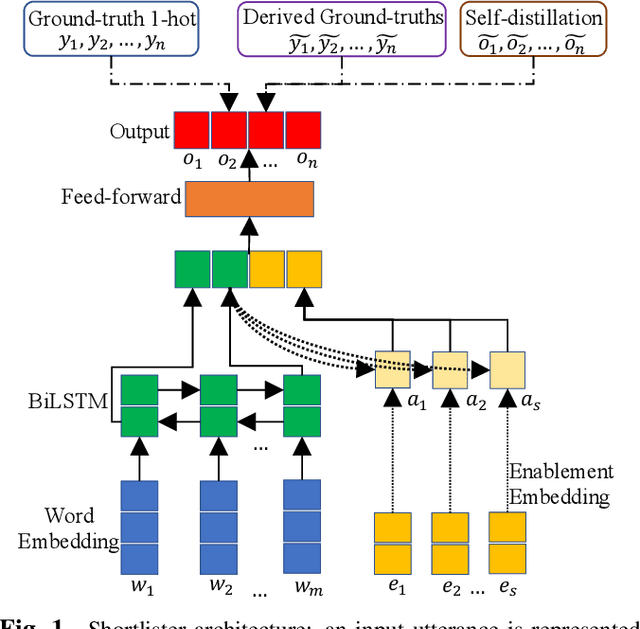



In large-scale domain classification, an utterance can be handled by multiple domains with overlapped capabilities. However, only a limited number of ground-truth domains are provided for each training utterance in practice while knowing as many as correct target labels is helpful for improving the model performance. In this paper, given one ground-truth domain for each training utterance, we regard domains consistently predicted with the highest confidences as additional pseudo labels for the training. In order to reduce prediction errors due to incorrect pseudo labels, we leverage utterances with negative system responses to decrease the confidences of the incorrectly predicted domains. Evaluating on user utterances from an intelligent conversational system, we show that the proposed approach significantly improves the performance of domain classification with hypothesis reranking.