 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Mixed Training: Scaling Parametric Knowledge Acquisition Beyond RAG
Mar 24, 2026Synthetic data augmentation helps language models learn new knowledge in data-constrained domains. However, naively scaling existing synthetic data methods by training on more synthetic tokens or using stronger generators yields diminishing returns below the performance of RAG. To break the RAG ceiling, we introduce Synthetic Mixed Training, which combines synthetic QAs and synthetic documents. This leverages their complementary training signals, and enables log-linear improvements as both synthetic data volume and generator strength increase. This allows the model to outperform RAG by a 2.6\% relative gain on QuaLITY, a long-document reading comprehension benchmark. In addition, we introduce Focal Rewriting, a simple technique for synthetic document generation that explicitly conditions document generation on specific questions, improving the diversity of synthetic documents and yielding a steeper log-linear scaling curve. On QuaLITY, our final recipe trains a Llama 8B model that outperforms RAG by 4.4\% relatively. Across models and benchmarks (QuaLITY, LongHealth, FinanceBench), our training enables models to beat RAG in five of six settings, outperforms by 2.6\%, and achieves a 9.1\% gain when combined with RAG.
Collaborative and Efficient Fine-tuning: Leveraging Task Similarity
Feb 06, 2026Adaptability has been regarded as a central feature in the foundation models, enabling them to effectively acclimate to unseen downstream tasks. Parameter-efficient fine-tuning methods such as celebrated LoRA facilitate efficient adaptation of large foundation models using labeled, high-quality and generally scarce task data. To mitigate data scarcity in fine-tuning of foundation models, we propose to leverage task similarity across multiple downstream users. Intuitively, users with similar tasks must be able to assist each other in boosting the effective fine-tuning data size. We propose Collaborative Low-Rank Adaptation, or CoLoRA, which exploits task similarity to collaboratively and efficiently fine-tune personalized foundation models. The main idea in CoLoRA is to train one shared adapter capturing underlying task similarities across all tasks, and personalized adapters tailored to user-specific tasks. We theoretically study CoLoRA on heterogeneous linear regression and provide provable guarantees for ground truth recovery. We also conduct several natural language experiments with varying task similarity, which further demonstrate that when trained together with similar tasks, individual performances are significantly boosted.
An Effective Energy Mask-based Adversarial Evasion Attacks against Misclassification in Speaker Recognition Systems
Jan 29, 2026Evasion attacks pose significant threats to AI systems, exploiting vulnerabilities in machine learning models to bypass detection mechanisms. The widespread use of voice data, including deepfakes, in promising future industries is currently hindered by insufficient legal frameworks. Adversarial attack methods have emerged as the most effective countermeasure against the indiscriminate use of such data. This research introduces masked energy perturbation (MEP), a novel approach using power spectrum for energy masking of original voice data. MEP applies masking to small energy regions in the frequency domain before generating adversarial perturbations, targeting areas less noticeable to the human auditory model. The study primarily employs advanced speaker recognition models, including ECAPA-TDNN and ResNet34, which have shown remarkable performance in speaker verification tasks. The proposed MEP method demonstrated strong performance in both audio quality and evasion effectiveness. The energy masking approach effectively minimizes the perceptual evaluation of speech quality (PESQ) degradation, indicating that minimal perceptual distortion occurs to the human listener despite the adversarial perturbations. Specifically, in the PESQ evaluation, the relative performance of the MEP method was 26.68% when compared to the fast gradient sign method (FGSM) and iterative FGSM.
A.X K1 Technical Report
Jan 15, 2026We introduce A.X K1, a 519B-parameter Mixture-of-Experts (MoE) language model trained from scratch. Our design leverages scaling laws to optimize training configurations and vocabulary size under fixed computational budgets. A.X K1 is pre-trained on a corpus of approximately 10T tokens, curated by a multi-stage data processing pipeline. Designed to bridge the gap between reasoning capability and inference efficiency, A.X K1 supports explicitly controllable reasoning to facilitate scalable deployment across diverse real-world scenarios. We propose a simple yet effective Think-Fusion training recipe, enabling user-controlled switching between thinking and non-thinking modes within a single unified model. Extensive evaluations demonstrate that A.X K1 achieves performance competitive with leading open-source models, while establishing a distinctive advantage in Korean-language benchmarks.
Towards a Science of Scaling Agent Systems
Dec 17, 2025Agents, language model-based systems that are capable of reasoning, planning, and acting are becoming the dominant paradigm for real-world AI applications. Despite this widespread adoption, the principles that determine their performance remain underexplored. We address this by deriving quantitative scaling principles for agent systems. We first formalize a definition for agentic evaluation and characterize scaling laws as the interplay between agent quantity, coordination structure, model capability, and task properties. We evaluate this across four benchmarks: Finance-Agent, BrowseComp-Plus, PlanCraft, and Workbench. With five canonical agent architectures (Single-Agent and four Multi-Agent Systems: Independent, Centralized, Decentralized, Hybrid), instantiated across three LLM families, we perform a controlled evaluation spanning 180 configurations. We derive a predictive model using coordination metrics, that achieves cross-validated R^2=0.524, enabling prediction on unseen task domains. We identify three effects: (1) a tool-coordination trade-off: under fixed computational budgets, tool-heavy tasks suffer disproportionately from multi-agent overhead. (2) a capability saturation: coordination yields diminishing or negative returns once single-agent baselines exceed ~45%. (3) topology-dependent error amplification: independent agents amplify errors 17.2x, while centralized coordination contains this to 4.4x. Centralized coordination improves performance by 80.8% on parallelizable tasks, while decentralized coordination excels on web navigation (+9.2% vs. +0.2%). Yet for sequential reasoning tasks, every multi-agent variants degraded performance by 39-70%. The framework predicts the optimal coordination strategy for 87% of held-out configurations. Out-of-sample validation on GPT-5.2, achieves MAE=0.071 and confirms four of five scaling principles generalize to unseen frontier models.
Post-Training LLMs as Better Decision-Making Agents: A Regret-Minimization Approach
Nov 06, 2025Large language models (LLMs) are increasingly deployed as "agents" for decision-making (DM) in interactive and dynamic environments. Yet, since they were not originally designed for DM, recent studies show that LLMs can struggle even in basic online DM problems, failing to achieve low regret or an effective exploration-exploitation tradeoff. To address this, we introduce Iterative Regret-Minimization Fine-Tuning (Iterative RMFT), a post-training procedure that repeatedly distills low-regret decision trajectories back into the base model. At each iteration, the model rolls out multiple decision trajectories, selects the k-lowest regret ones, and fine-tunes itself on them. Unlike prior methods that (a) distill action sequences from known DM algorithms or (b) rely on manually crafted chain-of-thought templates, our approach leverages the regret metric to elicit the model's own DM ability and reasoning rationales. This reliance on model-generated reasoning avoids rigid output engineering and provides more flexible, natural-language training signals. Empirical results show that Iterative RMFT improves LLMs' DM performance across diverse models - from Transformers with numerical input/output, to open-weight LLMs, and advanced closed-weight models like GPT-4o mini. Its flexibility in output and reasoning formats enables generalization across tasks with varying horizons, action spaces, reward processes, and natural-language contexts. Finally, we provide theoretical insight showing that a single-layer Transformer under this paradigm can act as a no-regret learner in a simplified setting. Overall, Iterative RMFT offers a principled and general post-training framework for enhancing LLMs' decision-making capabilities.
Thunder-Tok: Minimizing Tokens per Word in Tokenizing Korean Texts for Generative Language Models
Jun 18, 2025
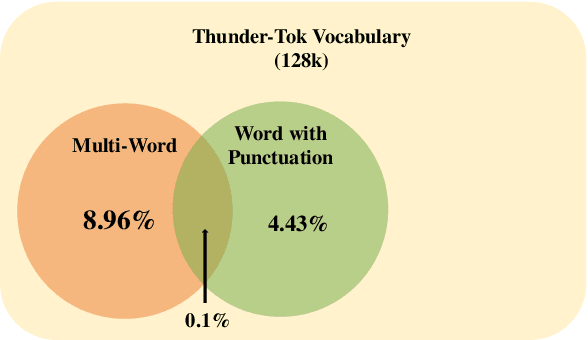

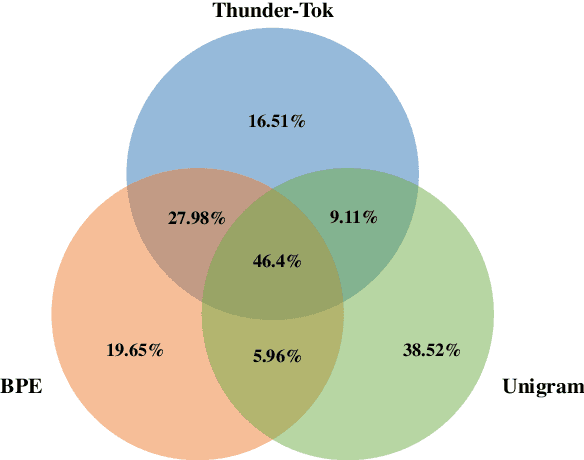
This paper introduces Thunder-Tok, a new Korean tokenizer designed to reduce token fertility without compromising model performance. Our approach uses a rule-based pre-tokenization method that aligns with the linguistic structure of the Korean language. We also create a seed vocabulary containing tokens that resemble linguistic units and employ a branching entropy-based selection algorithm. These techniques increase the average token length, thus lowering fertility while preserving linguistic information. Experimental results indicate that Thunder-Tok reduces fertility by approximately 10% (i.e., reduces the number of tokens by 10%, improving the inference speed by 10%) compared to BPE without compromising performance across various downstream tasks. These findings demonstrate that our linguistically informed approach is effective and practical for designing efficient tokenizers for language models.
Tiered Agentic Oversight: A Hierarchical Multi-Agent System for AI Safety in Healthcare
Jun 14, 2025Current large language models (LLMs), despite their power, can introduce safety risks in clinical settings due to limitations such as poor error detection and single point of failure. To address this, we propose Tiered Agentic Oversight (TAO), a hierarchical multi-agent framework that enhances AI safety through layered, automated supervision. Inspired by clinical hierarchies (e.g., nurse, physician, specialist), TAO conducts agent routing based on task complexity and agent roles. Leveraging automated inter- and intra-tier collaboration and role-playing, TAO creates a robust safety framework. Ablation studies reveal that TAO's superior performance is driven by its adaptive tiered architecture, which improves safety by over 3.2% compared to static single-tier configurations; the critical role of its lower tiers, particularly tier 1, whose removal most significantly impacts safety; and the strategic assignment of more advanced LLM to these initial tiers, which boosts performance by over 2% compared to less optimal allocations while achieving near-peak safety efficiently. These mechanisms enable TAO to outperform single-agent and multi-agent frameworks in 4 out of 5 healthcare safety benchmarks, showing up to an 8.2% improvement over the next-best methods in these evaluations. Finally, we validate TAO via an auxiliary clinician-in-the-loop study where integrating expert feedback improved TAO's accuracy in medical triage from 40% to 60%.
BehaviorSFT: Behavioral Token Conditioning for Clinical Agents Across the Proactivity Spectrum
May 27, 2025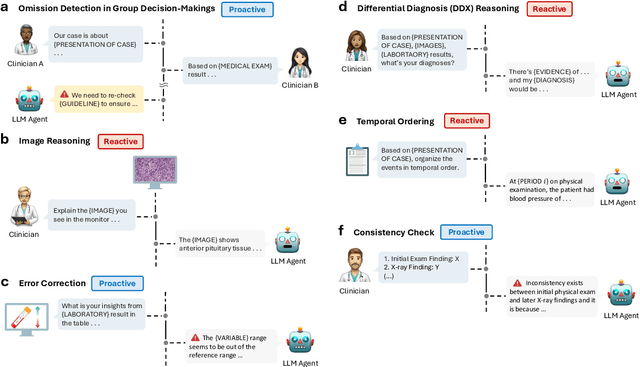
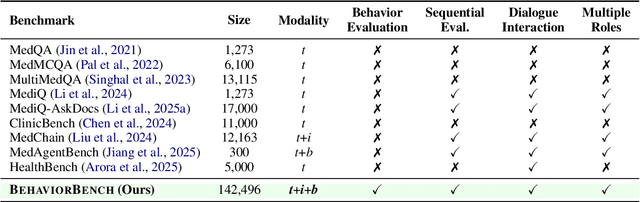
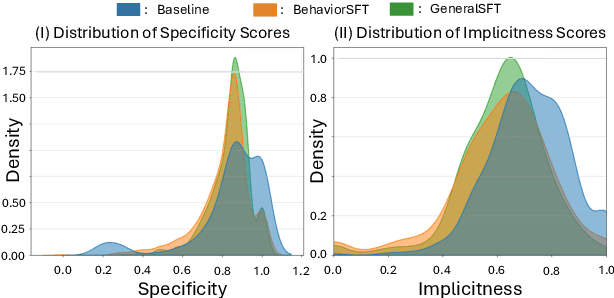
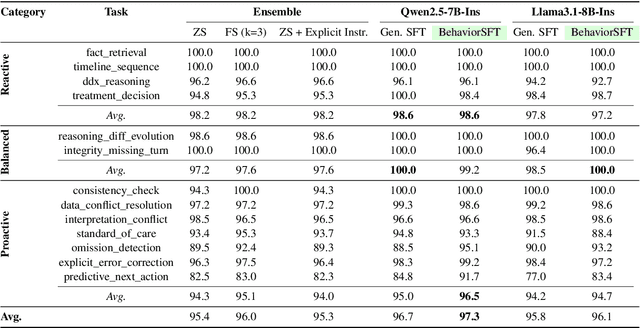
Large Language Models (LLMs) as clinical agents require careful behavioral adaptation. While adept at reactive tasks (e.g., diagnosis reasoning), LLMs often struggle with proactive engagement, like unprompted identification of critical missing information or risks. We introduce BehaviorBench, a comprehensive dataset to evaluate agent behaviors across a clinical assistance spectrum, ranging from reactive query responses to proactive interventions (e.g., clarifying ambiguities, flagging overlooked critical data). Our BehaviorBench experiments reveal LLMs' inconsistent proactivity. To address this, we propose BehaviorSFT, a novel training strategy using behavioral tokens to explicitly condition LLMs for dynamic behavioral selection along this spectrum. BehaviorSFT boosts performance, achieving up to 97.3% overall Macro F1 on BehaviorBench and improving proactive task scores (e.g., from 95.0% to 96.5% for Qwen2.5-7B-Ins). Crucially, blind clinician evaluations confirmed BehaviorSFT-trained agents exhibit more realistic clinical behavior, striking a superior balance between helpful proactivity (e.g., timely, relevant suggestions) and necessary restraint (e.g., avoiding over-intervention) versus standard fine-tuning or explicit instructed agents.
Toward Evaluative Thinking: Meta Policy Optimization with Evolving Reward Models
Apr 28, 2025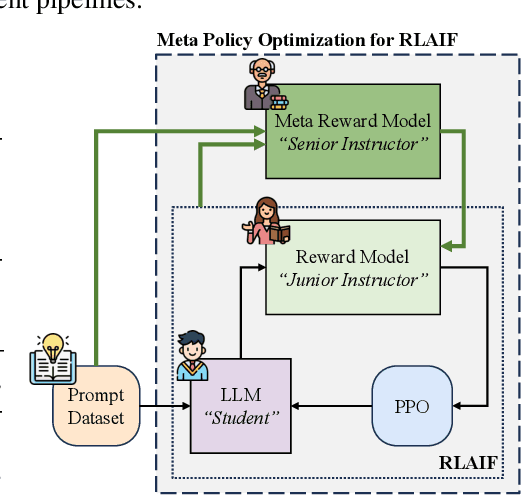


Reward-based alignment methods for large language models (LLMs) face two key limitations: vulnerability to reward hacking, where models exploit flaws in the reward signal; and reliance on brittle, labor-intensive prompt engineering when LLMs are used as reward models. We introduce Meta Policy Optimization (MPO), a framework that addresses these challenges by integrating a meta-reward model that dynamically refines the reward model's prompt throughout training. In MPO, the meta-reward model monitors the evolving training context and continuously adjusts the reward model's prompt to maintain high alignment, providing an adaptive reward signal that resists exploitation by the policy. This meta-learning approach promotes a more stable policy optimization, and greatly reduces the need for manual reward prompt design. It yields performance on par with or better than models guided by extensively hand-crafted reward prompts. Furthermore, we show that MPO maintains its effectiveness across diverse tasks, such as question answering and mathematical reasoning, without requiring specialized reward designs. Beyond standard RLAIF, MPO's meta-learning formulation is readily extensible to higher-level alignment frameworks. Overall, this method addresses theoretical and practical challenges in reward-based RL alignment for LLMs, paving the way for more robust and adaptable alignment strategies. The code and models will be publicly shared.