 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehaviorSFT: Behavioral Token Conditioning for Clinical Agents Across the Proactivity Spectrum
May 27, 2025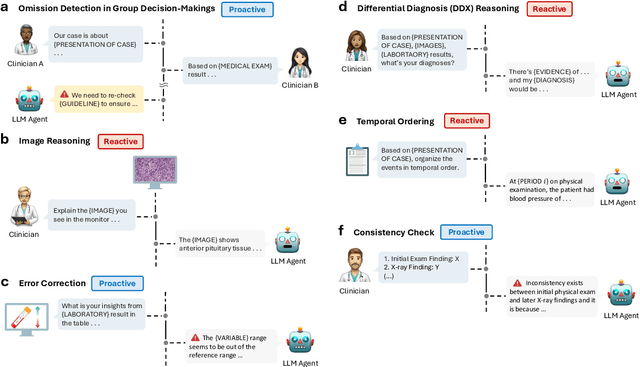
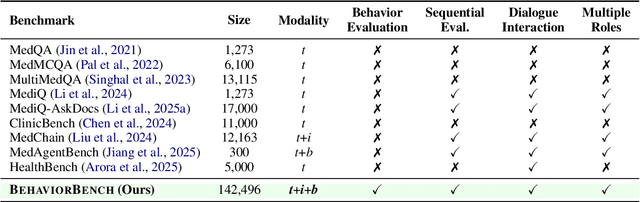
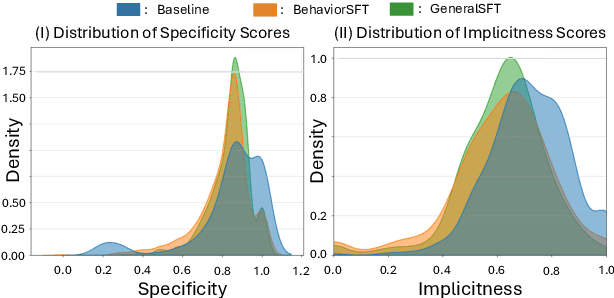
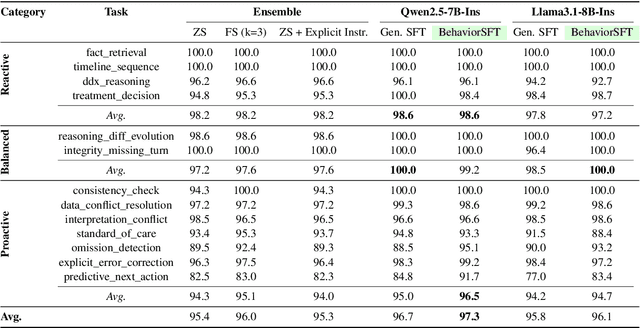
Large Language Models (LLMs) as clinical agents require careful behavioral adaptation. While adept at reactive tasks (e.g., diagnosis reasoning), LLMs often struggle with proactive engagement, like unprompted identification of critical missing information or risks. We introduce BehaviorBench, a comprehensive dataset to evaluate agent behaviors across a clinical assistance spectrum, ranging from reactive query responses to proactive interventions (e.g., clarifying ambiguities, flagging overlooked critical data). Our BehaviorBench experiments reveal LLMs' inconsistent proactivity. To address this, we propose BehaviorSFT, a novel training strategy using behavioral tokens to explicitly condition LLMs for dynamic behavioral selection along this spectrum. BehaviorSFT boosts performance, achieving up to 97.3% overall Macro F1 on BehaviorBench and improving proactive task scores (e.g., from 95.0% to 96.5% for Qwen2.5-7B-Ins). Crucially, blind clinician evaluations confirmed BehaviorSFT-trained agents exhibit more realistic clinical behavior, striking a superior balance between helpful proactivity (e.g., timely, relevant suggestions) and necessary restraint (e.g., avoiding over-intervention) versus standard fine-tuning or explicit instructed agents.
Is Deep Reinforcement Learning Ready for Practical Applications in Healthcare? A Sensitivity Analysis of Duel-DDQN for Sepsis Treatment
May 08, 2020
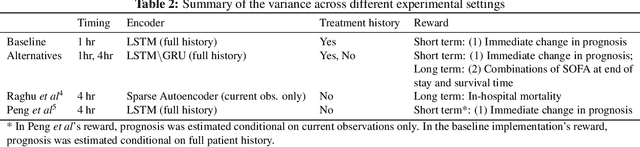
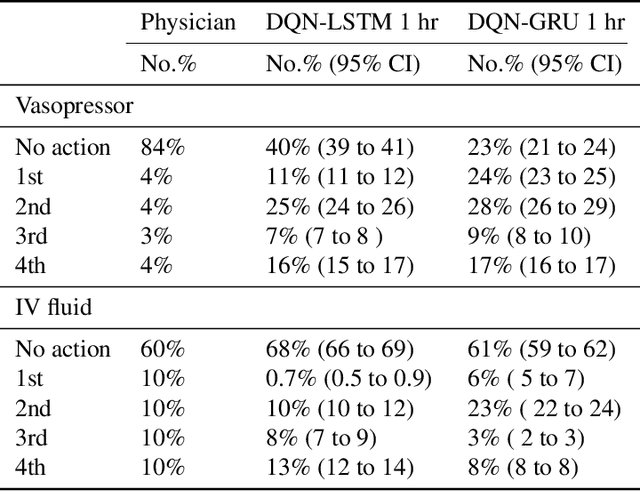
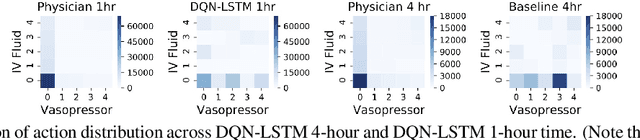
The potential of Reinforcement Learning (RL) has been demonstrated through successful applications to games such as Go and Atari. However, while it is straightforward to evaluate the performance of an RL algorithm in a game setting by simply using it to play the game, evaluation is a major challenge in clinical settings where it could be unsafe to follow RL policies in practice. Thus, understanding sensitivity of RL policies to the host of decisions made during implementation is an important step toward building the type of trust in RL required for eventual clinical uptake. In this work, we perform a sensitivity analysis on a state-of-the-art RL algorithm (Dueling Double Deep Q-Networks)applied to hemodynamic stabilization treatment strategies for septic patients in the ICU. We consider sensitivity of learned policies to input features, time discretization, reward function, and random seeds. We find that varying these settings can significantly impact learned policies, which suggests a need for caution when interpreting RL agent output.
A Biologically Plausible Benchmark for Contextual Bandit Algorithms in Precision Oncology Using in vitro Data
Nov 11, 2019

Precision oncology, the genetic sequencing of tumors to identify druggable targets, has emerged as the standard of care in the treatment of many cancers. Nonetheless, due to the pace of therapy development and variability in patient information, designing effective protocols for individual treatment assignment in a sample-efficient way remains a major challenge. One promising approach to this problem is to frame precision oncology treatment as a contextual bandit problem and to apply sequential decision-making algorithms designed to minimize regret in this setting. However, a clear prerequisite for considering this methodology in high-stakes clinical decisions is careful benchmarking to understand realistic costs and benefits. Here, we propose a benchmark dataset to evaluate contextual bandit algorithms based on real in vitro drug response of approximately 900 cancer cell lines. Specifically, we curated a dataset of complete treatment responses for a subset of 7 treatments from prior in vitro studies. This allows us to compute the regret of proposed decision policies using biologically plausible counterfactuals. We ran a suite of Bayesian bandit algorithms on our benchmark, and found that the methods accumulate less regret over a sequence of treatment assignment tasks than a rule-based baseline derived from current clinical practice. This effect was more pronounced when genomic information was included as context. We expect this work to be a starting point for evaluation of both the unique structural requirements and ethical implications for real-world testing of bandit based clinical decision support.