 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Locally, Explain Globally: Graph-Guided LLM Investigations via Local Reasoning and Belief Propagation
Jan 25, 2026LLM agents excel when environments are mostly static and the needed information fits in a model's context window, but they often fail in open-ended investigations where explanations must be constructed by iteratively mining evidence from massive, heterogeneous operational data. These investigations exhibit hidden dependency structure: entities interact, signals co-vary, and the importance of a fact may only become clear after other evidence is discovered. Because the context window is bounded, agents must summarize intermediate findings before their significance is known, increasing the risk of discarding key evidence. ReAct-style agents are especially brittle in this regime. Their retrieve-summarize-reason loop makes conclusions sensitive to exploration order and introduces run-to-run non-determinism, producing a reliability gap where Pass-at-k may be high but Majority-at-k remains low. Simply sampling more rollouts or generating longer reasoning traces does not reliably stabilize results, since hypotheses cannot be autonomously checked as new evidence arrives and there is no explicit mechanism for belief bookkeeping and revision. In addition, ReAct entangles semantic reasoning with controller duties such as tool orchestration and state tracking, so execution errors and plan drift degrade reasoning while consuming scarce context. We address these issues by formulating investigation as abductive reasoning over a dependency graph and proposing EoG (Explanations over Graphs), a disaggregated framework in which an LLM performs bounded local evidence mining and labeling (cause vs symptom) while a deterministic controller manages traversal, state, and belief propagation to compute a minimal explanatory frontier. On a representative ITBench diagnostics task, EoG improves both accuracy and run-to-run consistency over ReAct baselines, including a 7x average gain in Majority-at-k entity F1.
Characterizing GPU Resilience and Impact on AI/HPC Systems
Mar 14, 2025In this study, we characterize GPU failures in Delta, the current large-scale AI system with over 600 petaflops of peak compute throughput. The system comprises GPU and non-GPU nodes with modern AI accelerators, such as NVIDIA A40, A100, and H100 GPUs. The study uses two and a half years of data on GPU errors. We evaluate the resilience of GPU hardware components to determine the vulnerability of different GPU components to failure and their impact on the GPU and node availability. We measure the key propagation paths in GPU hardware, GPU interconnect (NVLink), and GPU memory. Finally, we evaluate the impact of the observed GPU errors on user jobs. Our key findings are: (i) Contrary to common beliefs, GPU memory is over 30x more reliable than GPU hardware in terms of MTBE (mean time between errors). (ii) The newly introduced GSP (GPU System Processor) is the most vulnerable GPU hardware component. (iii) NVLink errors did not always lead to user job failure, and we attribute it to the underlying error detection and retry mechanisms employed. (iv) We show multiple examples of hardware errors originating from one of the key GPU hardware components, leading to application failure. (v) We project the impact of GPU node availability on larger scales with emulation and find that significant overprovisioning between 5-20% would be necessary to handle GPU failures. If GPU availability were improved to 99.9%, the overprovisioning would be reduced by 4x.
ITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks
Feb 07, 2025



Realizing the vision of using AI agents to automate critical IT tasks depends on the ability to measure and understand effectiveness of proposed solutions. We introduce ITBench, a framework that offers a systematic methodology for benchmarking AI agents to address real-world IT automation tasks. Our initial release targets three key areas: Site Reliability Engineering (SRE), Compliance and Security Operations (CISO), and Financial Operations (FinOps). The design enables AI researchers to understand the challenges and opportunities of AI agents for IT automation with push-button workflows and interpretable metrics. ITBench includes an initial set of 94 real-world scenarios, which can be easily extended by community contributions. Our results show that agents powered by state-of-the-art models resolve only 13.8% of SRE scenarios, 25.2% of CISO scenarios, and 0% of FinOps scenarios. We expect ITBench to be a key enabler of AI-driven IT automation that is correct, safe, and fast.
Automated Compliance Blueprint Optimization with Artificial Intelligence
Jun 22, 2022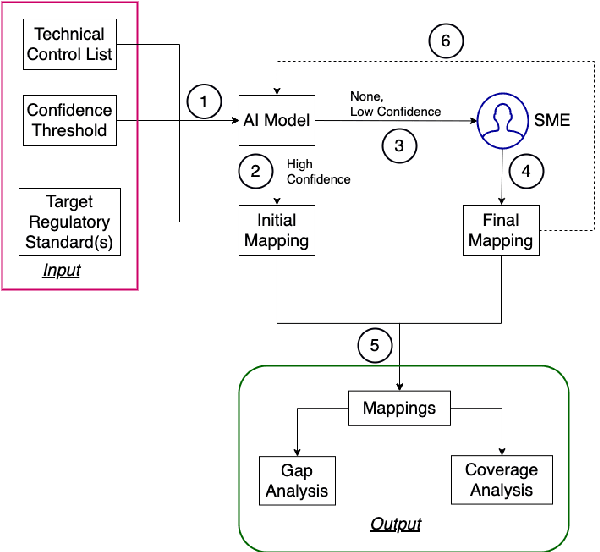
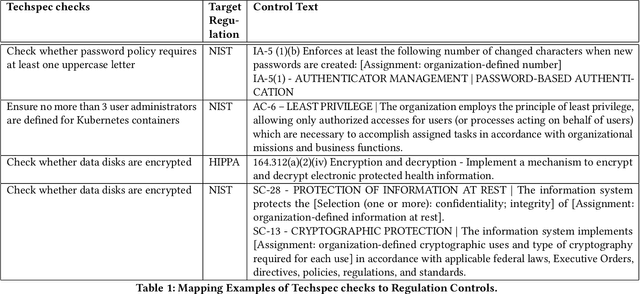
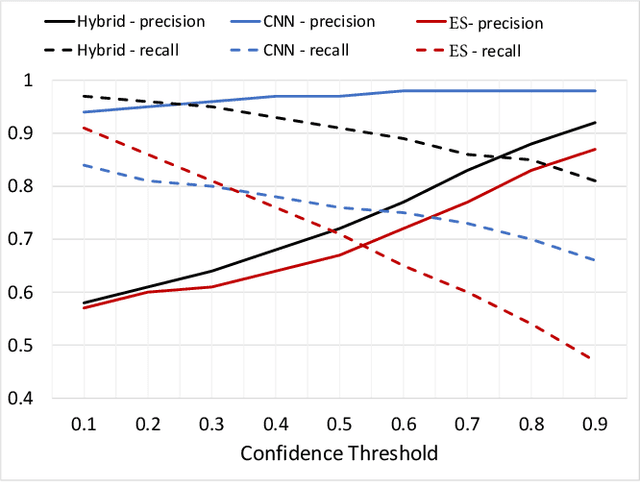
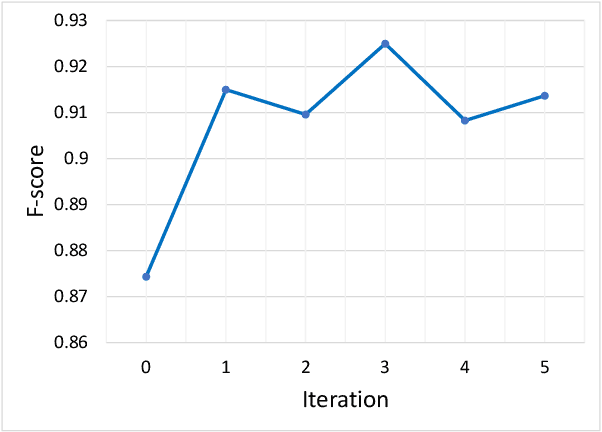
For highly regulated industries such as banking and healthcare, one of the major hindrances to the adoption of cloud computing is compliance with regulatory standards. This is a complex problem due to many regulatory and technical specification (techspec) documents that the companies need to comply with. The critical problem is to establish the mapping between techspecs and regulation controls so that from day one, companies can comply with regulations with minimal effort. We demonstrate the practicality of an approach to automatically analyze regulatory standards using Artificial Intelligence (AI) techniques. We present early results to identify the mapping between techspecs and regulation controls, and discuss challenges that must be overcome for this solution to be fully practical.
Vulnerability Prioritization: An Offensive Security Approach
Jun 22, 2022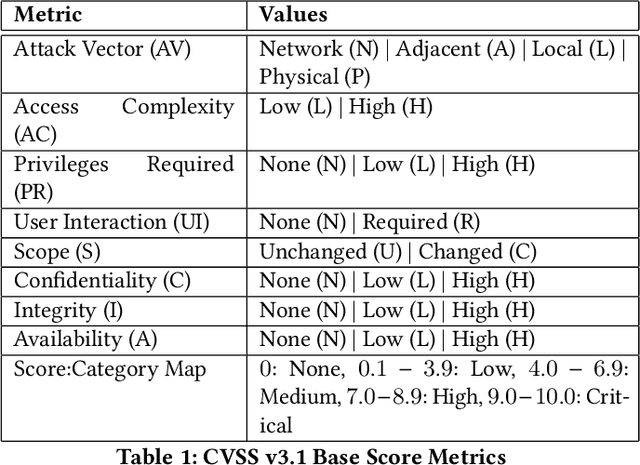
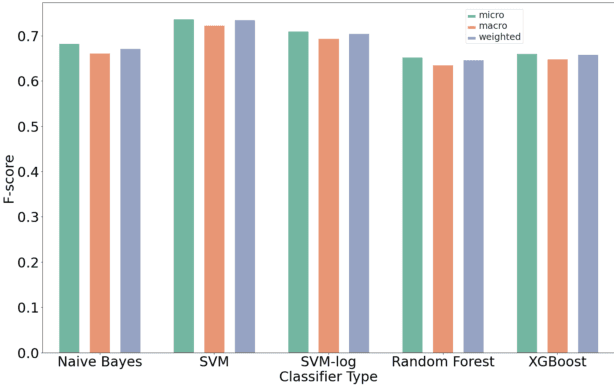

Organizations struggle to handle sheer number of vulnerabilities in their cloud environments. The de facto methodology used for prioritizing vulnerabilities is to use Common Vulnerability Scoring System (CVSS). However, CVSS has inherent limitations that makes it not ideal for prioritization. In this work, we propose a new way of prioritizing vulnerabilities. Our approach is inspired by how offensive security practitioners perform penetration testing. We evaluate our approach with a real world case study for a large client, and the accuracy of machine learning to automate the process end to end.
Attack Techniques and Threat Identification for Vulnerabilities
Jun 22, 2022
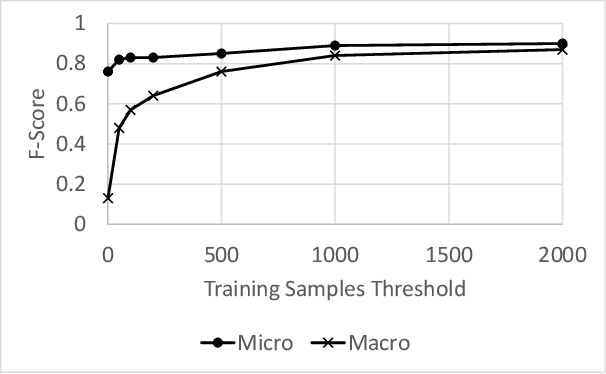
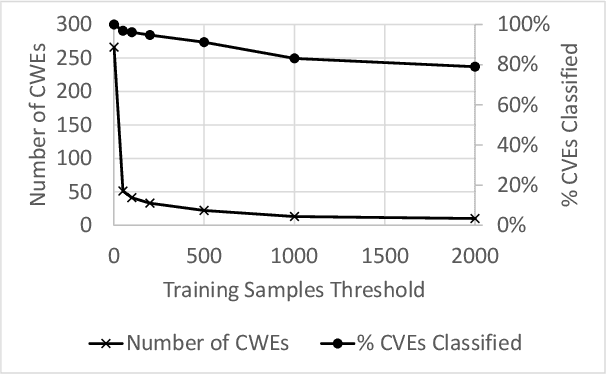
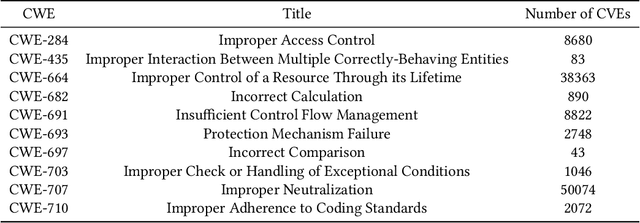
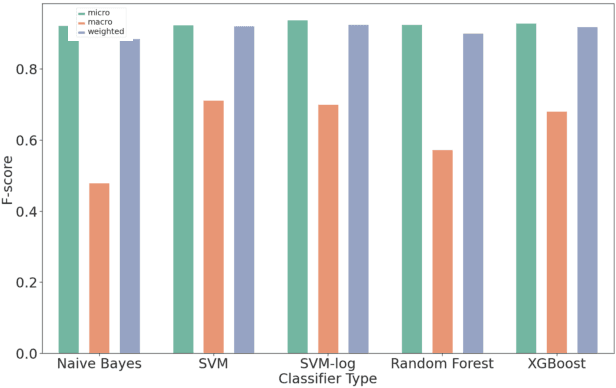
Modern organizations struggle with insurmountable number of vulnerabilities that are discovered and reported by their network and application vulnerability scanners. Therefore, prioritization and focus become critical, to spend their limited time on the highest risk vulnerabilities. In doing this, it is important for these organizations not only to understand the technical descriptions of the vulnerabilities, but also to gain insights into attackers' perspectives. In this work, we use machine learning and natural language processing techniques, as well as several publicly available data sets to provide an explainable mapping of vulnerabilities to attack techniques and threat actors. This work provides new security intelligence, by predicting which attack techniques are most likely to be used to exploit a given vulnerability and which threat actors are most likely to conduct the exploitation. Lack of labeled data and different vocabularies make mapping vulnerabilities to attack techniques at scale a challenging problem that cannot be addressed easily using supervised or unsupervised (similarity search) learning techniques. To solve this problem, we first map the vulnerabilities to a standard set of common weaknesses, and then common weaknesses to the attack techniques. This approach yields a Mean Reciprocal Rank (MRR) of 0.95, an accuracy comparable with those reported for state-of-the-art systems. Our solution has been deployed to IBM Security X-Force Red Vulnerability Management Services, and in production since 2021. The solution helps security practitioners to assist customers to manage and prioritize their vulnerabilities, providing them with an explainable mapping of vulnerabilities to attack techniques and threat actors
Blending Knowledge in Deep Recurrent Networks for Adverse Event Prediction at Hospital Discharge
Apr 09, 2021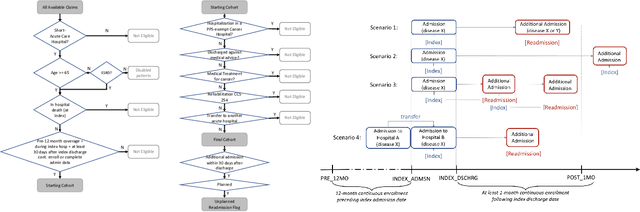
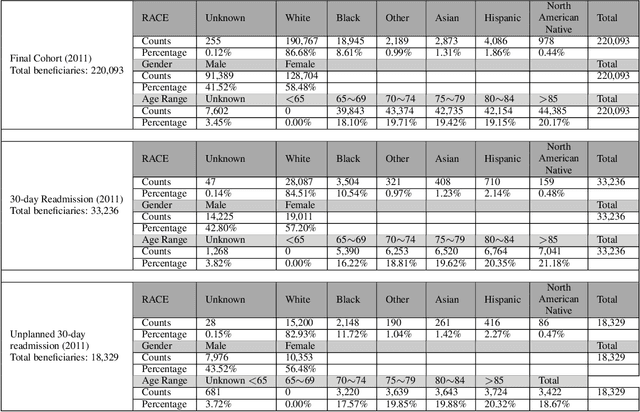
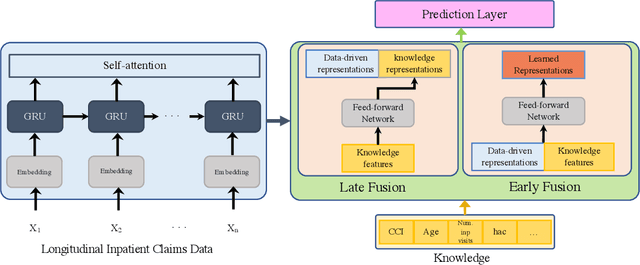

Deep learning architectures have an extremely high-capacity for modeling complex data in a wide variety of domains. However, these architectures have been limited in their ability to support complex prediction problems using insurance claims data, such as readmission at 30 days, mainly due to data sparsity issue. Consequently, classical machine learning methods, especially those that embed domain knowledge in handcrafted features, are often on par with, and sometimes outperform, deep learning approaches. In this paper, we illustrate how the potential of deep learning can be achieved by blending domain knowledge within deep learning architectures to predict adverse events at hospital discharge, including readmissions. More specifically, we introduce a learning architecture that fuses a representation of patient data computed by a self-attention based recurrent neural network, with clinically relevant features. We conduct extensive experiments on a large claims dataset and show that the blended method outperforms the standard machine learning approaches.
Question-Driven Design Process for Explainable AI User Experiences
Apr 08, 2021
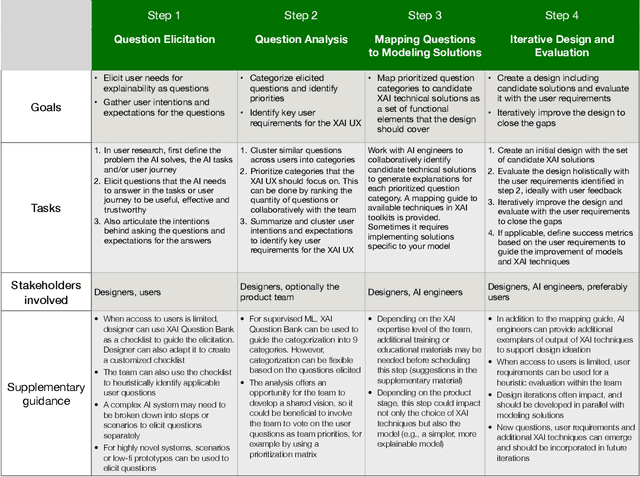
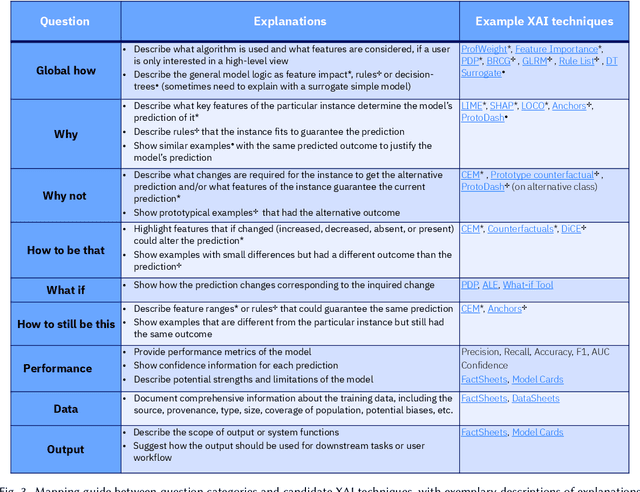
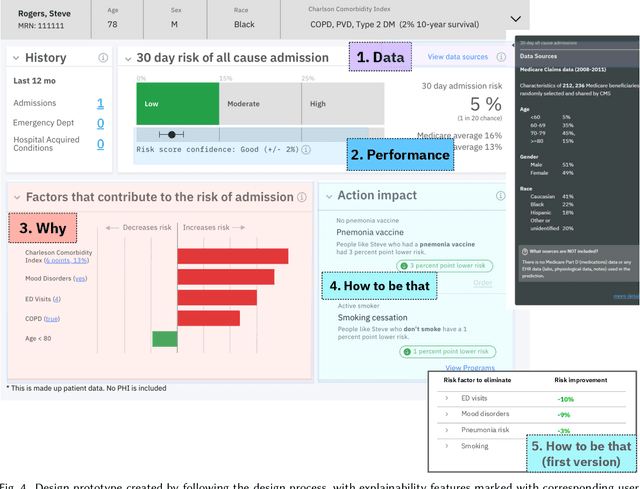
A pervasive design issue of AI systems is their explainability--how to provide appropriate information to help users understand the AI. The technical field of explainable AI (XAI) has produced a rich toolbox of techniques. Designers are now tasked with the challenges of how to select the most suitable XAI techniques and translate them into UX solutions. Informed by our previous work studying design challenges around XAI UX, this work proposes a design process to tackle these challenges. We review our and related prior work to identify requirements that the process should fulfill, and accordingly, propose a Question-Driven Design Process that grounds the user needs, choices of XAI techniques, design, and evaluation of XAI UX all in the user questions. We provide a mapping guide between prototypical user questions and exemplars of XAI techniques, serving as boundary objects to support collaboration between designers and AI engineers. We demonstrate it with a use case of designing XAI for healthcare adverse events prediction, and discuss lessons learned for tackling design challenges of AI systems.
Phenotypical Ontology Driven Framework for Multi-Task Learning
Sep 04, 2020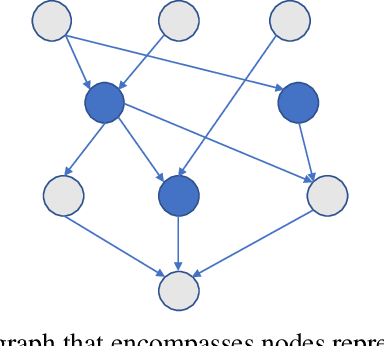
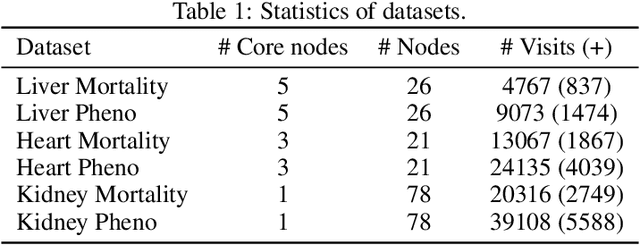
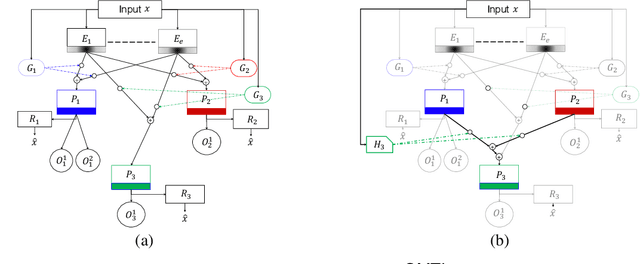
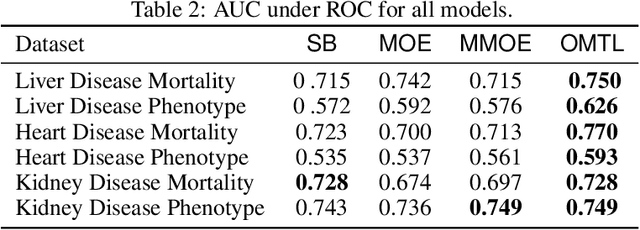
Despite the large number of patients in Electronic Health Records (EHRs), the subset of usable data for modeling outcomes of specific phenotypes are often imbalanced and of modest size. This can be attributed to the uneven coverage of medical concepts in EHRs. In this paper, we propose OMTL, an Ontology-driven Multi-Task Learning framework, that is designed to overcome such data limitations. The key contribution of our work is the effective use of knowledge from a predefined well-established medical relationship graph (ontology) to construct a novel deep learning network architecture that mirrors this ontology. It can effectively leverage knowledge from a well-established medical relationship graph (ontology) by constructing a deep learning network architecture that mirrors this graph. This enables common representations to be shared across related phenotypes, and was found to improve the learning performance. The proposed OMTL naturally allows for multitask learning of different phenotypes on distinct predictive tasks. These phenotypes are tied together by their semantic distance according to the external medical ontology. Using the publicly available MIMIC-III database, we evaluate OMTL and demonstrate its efficacy on several real patient outcome predictions over state-of-the-art multi-task learning schemes.
A Canonical Architecture For Predictive Analytics on Longitudinal Patient Records
Jul 24, 2020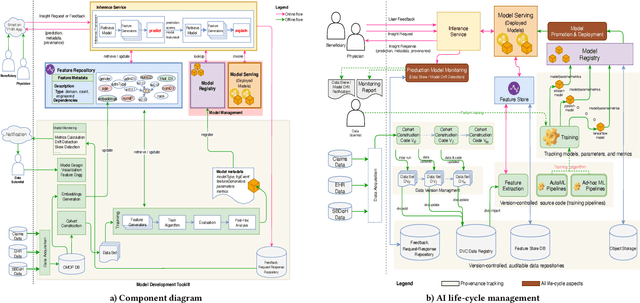
Many institutions within the healthcare ecosystem are making significant investments in AI technologies to optimize their business operations at lower cost with improved patient outcomes. Despite the hype with AI, the full realization of this potential is seriously hindered by several systemic problems, including data privacy, security, bias, fairness, and explainability. In this paper, we propose a novel canonical architecture for the development of AI models in healthcare that addresses these challenges. This system enables the creation and management of AI predictive models throughout all the phases of their life cycle, including data ingestion, model building, and model promotion in production environments. This paper describes this architecture in detail, along with a qualitative evaluation of our experience of using it on real world problems.