 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisease Progression Modeling Workbench 360
Jun 24, 2021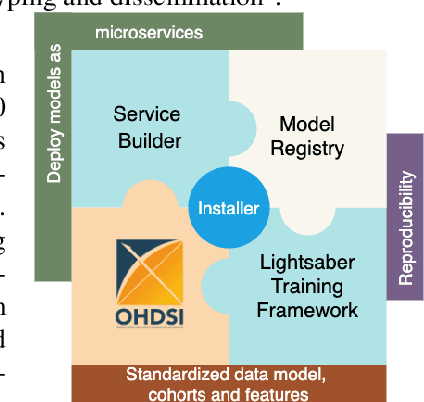
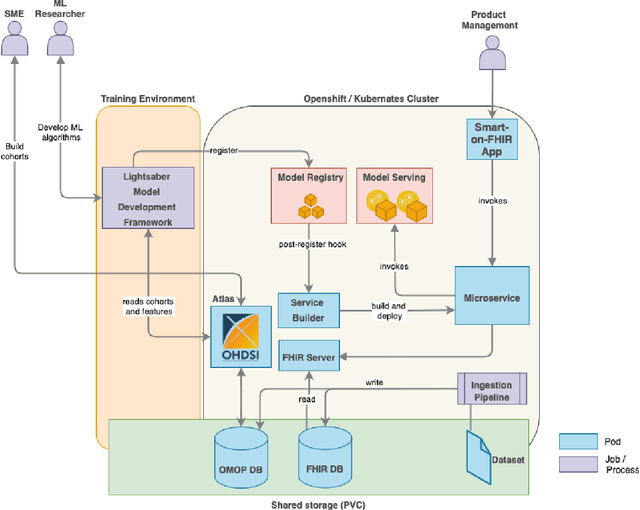
In this work we introduce Disease Progression Modeling workbench 360 (DPM360) opensource clinical informatics framework for collaborative research and delivery of healthcare AI. DPM360, when fully developed, will manage the entire modeling life cycle, from data analysis (e.g., cohort identification) to machine learning algorithm development and prototyping. DPM360 augments the advantages of data model standardization and tooling (OMOP-CDM, Athena, ATLAS) provided by the widely-adopted OHDSI initiative with a powerful machine learning training framework, and a mechanism for rapid prototyping through automatic deployment of models as containerized services to a cloud environment.
Blending Knowledge in Deep Recurrent Networks for Adverse Event Prediction at Hospital Discharge
Apr 09, 2021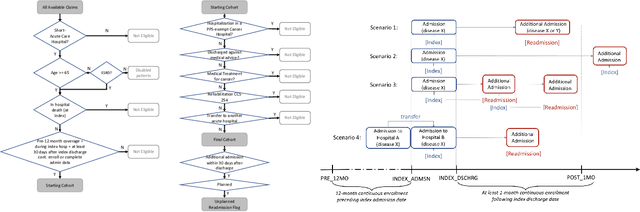
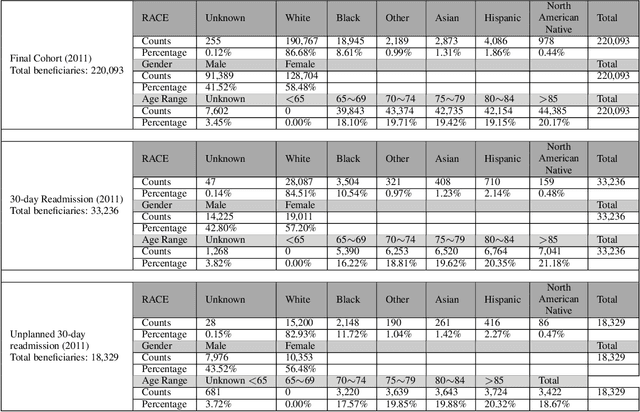
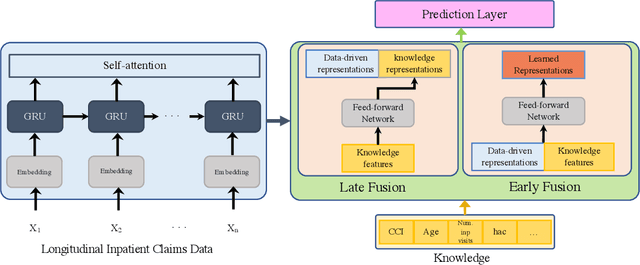

Deep learning architectures have an extremely high-capacity for modeling complex data in a wide variety of domains. However, these architectures have been limited in their ability to support complex prediction problems using insurance claims data, such as readmission at 30 days, mainly due to data sparsity issue. Consequently, classical machine learning methods, especially those that embed domain knowledge in handcrafted features, are often on par with, and sometimes outperform, deep learning approaches. In this paper, we illustrate how the potential of deep learning can be achieved by blending domain knowledge within deep learning architectures to predict adverse events at hospital discharge, including readmissions. More specifically, we introduce a learning architecture that fuses a representation of patient data computed by a self-attention based recurrent neural network, with clinically relevant features. We conduct extensive experiments on a large claims dataset and show that the blended method outperforms the standard machine learning approaches.
A Canonical Architecture For Predictive Analytics on Longitudinal Patient Records
Jul 24, 2020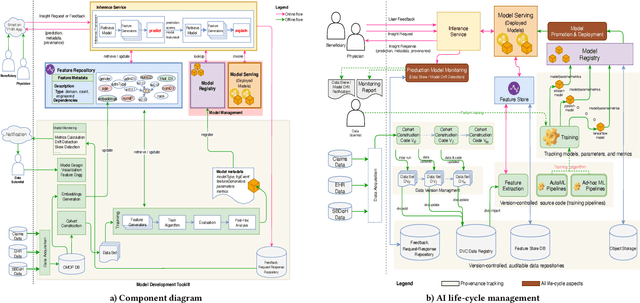
Many institutions within the healthcare ecosystem are making significant investments in AI technologies to optimize their business operations at lower cost with improved patient outcomes. Despite the hype with AI, the full realization of this potential is seriously hindered by several systemic problems, including data privacy, security, bias, fairness, and explainability. In this paper, we propose a novel canonical architecture for the development of AI models in healthcare that addresses these challenges. This system enables the creation and management of AI predictive models throughout all the phases of their life cycle, including data ingestion, model building, and model promotion in production environments. This paper describes this architecture in detail, along with a qualitative evaluation of our experience of using it on real world problems.
Effect of secular trend in drug effectiveness study in real world data
Aug 18, 2018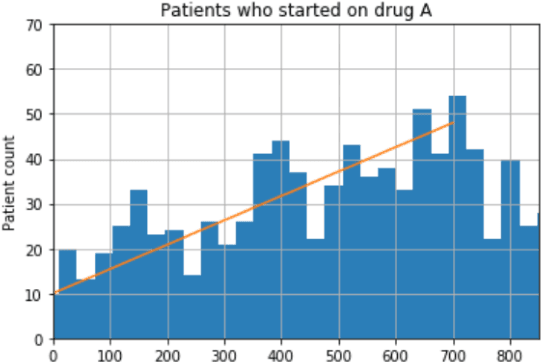
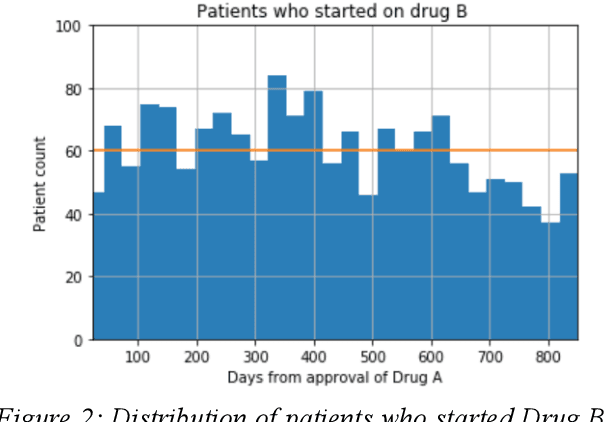
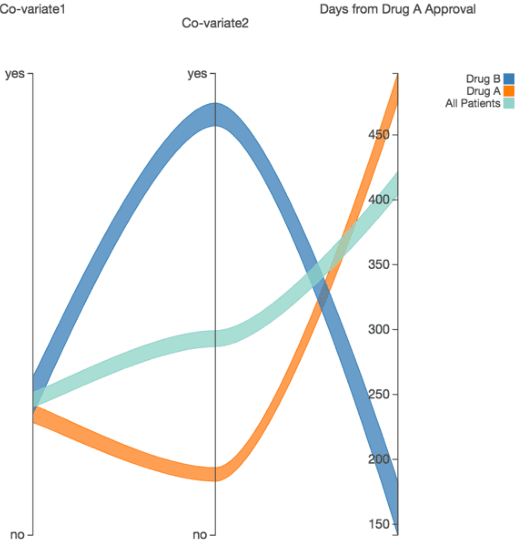
We discovered secular trend bias in a drug effectiveness study for a recently approved drug. We compared treatment outcomes between patients who received the newly approved drug and patients exposed to the standard treatment. All patients diagnosed after the new drug's approval date were considered. We built a machine learning causal inference model to determine patient subpopulations likely to respond better to the newly approved drug. After identifying the presence of secular trend bias in our data, we attempted to adjust for the bias in two different ways. First, we matched patients on the number of days from the new drug's approval date that the patient's treatment (new or standard) began. Second, we included a covariate in the model for the number of days between the date of approval of the new drug and the treatment (new or standard) start date. Neither approach completely mitigated the bias. Residual bias we attribute to differences in patient disease severity or other unmeasured patient characteristics. Had we not identified the secular trend bias in our data, the causal inference model would have been interpreted without consideration for this underlying bias. Being aware of, testing for, and handling potential bias in the data is essential to diminish the uncertainty in AI modeling.