 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Evaluation Toolkit to Guide Model Selection and Cohort Definition in Causal Inference
Jun 02, 2019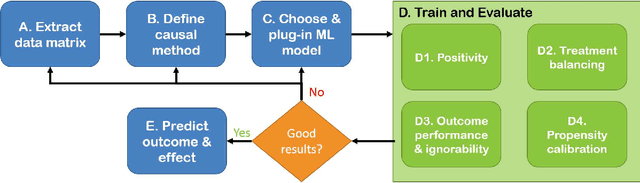

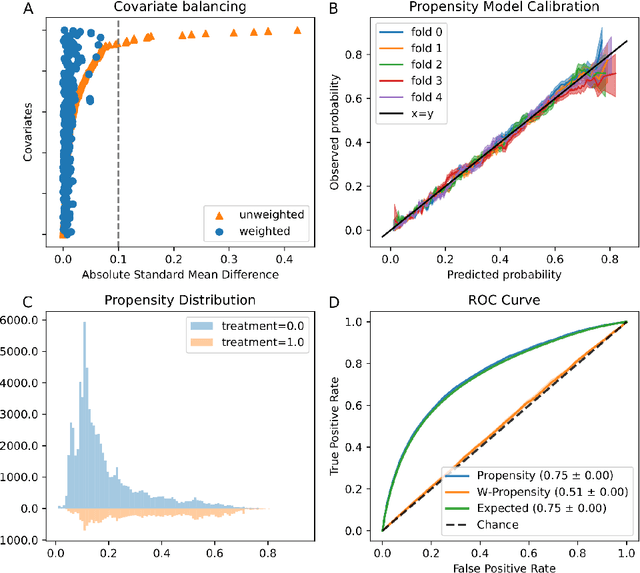
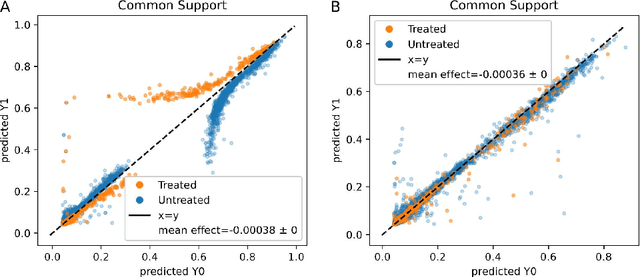
Real world observational data, together with causal inference, allow the estimation of causal effects when randomized controlled trials are not available. To be accepted into practice, such predictive models must be validated for the dataset at hand, and thus require a comprehensive evaluation toolkit, as introduced here. Since effect estimation cannot be evaluated directly, we turn to evaluating the various observable properties of causal inference, namely the observed outcome and treatment assignment. We developed a toolkit that expands established machine learning evaluation methods and adds several causal-specific ones. Evaluations can be applied in cross-validation, in a train-test scheme, or on the training data. Multiple causal inference methods are implemented within the toolkit in a way that allows modular use of the underlying machine learning models. Thus, the toolkit is agnostic to the machine learning model that is used. We showcase our approach using a rheumatoid arthritis cohort (consisting of about 120K patients) extracted from the IBM MarketScan(R) Research Database. We introduce an iterative pipeline of data definition, model definition, and model evaluation. Using this pipeline, we demonstrate how each of the evaluation components helps drive model selection and refinement of data extraction criteria in a way that provides more reproducible results and ensures that the causal question is answerable with available data. Furthermore, we show how the evaluation toolkit can be used to ensure that performance is maintained when applied to subsets of the data, thus allowing exploration of questions that move towards personalized medicine.
Effect of secular trend in drug effectiveness study in real world data
Aug 18, 2018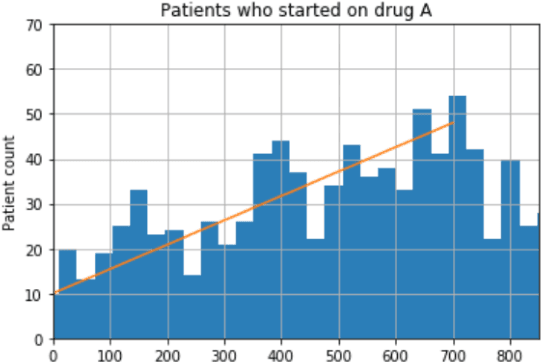
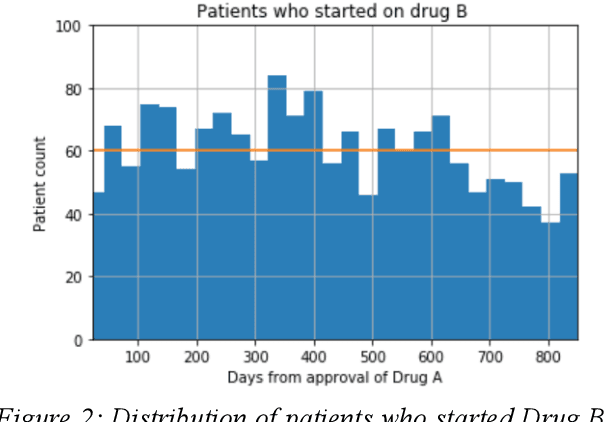
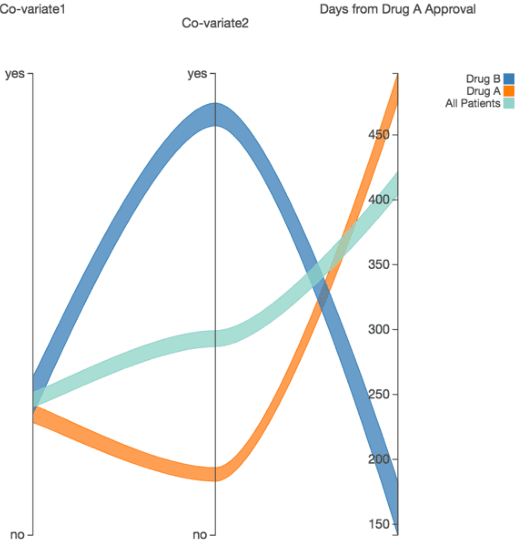
We discovered secular trend bias in a drug effectiveness study for a recently approved drug. We compared treatment outcomes between patients who received the newly approved drug and patients exposed to the standard treatment. All patients diagnosed after the new drug's approval date were considered. We built a machine learning causal inference model to determine patient subpopulations likely to respond better to the newly approved drug. After identifying the presence of secular trend bias in our data, we attempted to adjust for the bias in two different ways. First, we matched patients on the number of days from the new drug's approval date that the patient's treatment (new or standard) began. Second, we included a covariate in the model for the number of days between the date of approval of the new drug and the treatment (new or standard) start date. Neither approach completely mitigated the bias. Residual bias we attribute to differences in patient disease severity or other unmeasured patient characteristics. Had we not identified the secular trend bias in our data, the causal inference model would have been interpreted without consideration for this underlying bias. Being aware of, testing for, and handling potential bias in the data is essential to diminish the uncertainty in AI modeling.