 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
A discriminative approach for finding and characterizing positivity violations using decision trees
Jul 18, 2019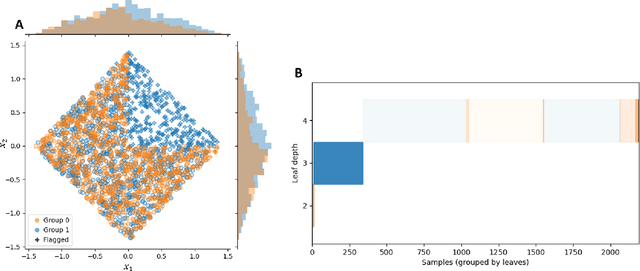
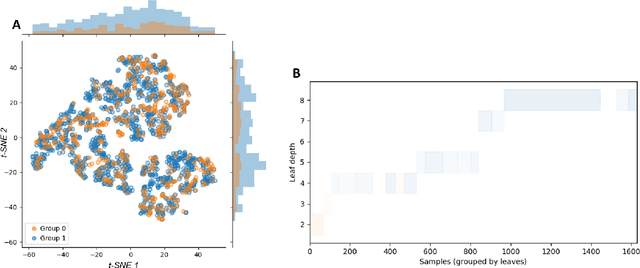
The assumption of positivity in causal inference (also known as common support and co-variate overlap) is necessary to obtain valid causal estimates. Therefore, confirming it holds in a given dataset is an important first step of any causal analysis. Most common methods to date are insufficient for discovering non-positivity, as they do not scale for modern high-dimensional covariate spaces, or they cannot pinpoint the subpopulation violating positivity. To overcome these issues, we suggest to harness decision trees for detecting violations. By dividing the covariate space into mutually exclusive regions, each with maximized homogeneity of treatment groups, decision trees can be used to automatically detect subspaces violating positivity. By augmenting the method with an additional random forest model, we can quantify the robustness of the violation within each subspace. This solution is scalable and provides an interpretable characterization of the subspaces in which violations occur. We provide a visualization of the stratification rules that define each subpopulation, combined with the severity of positivity violation within it. We also provide an interactive version of the visualization that allows a deeper dive into the properties of each subspace.
An Evaluation Toolkit to Guide Model Selection and Cohort Definition in Causal Inference
Jun 02, 2019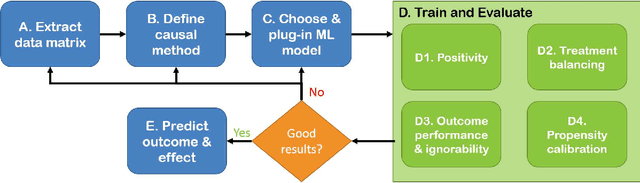

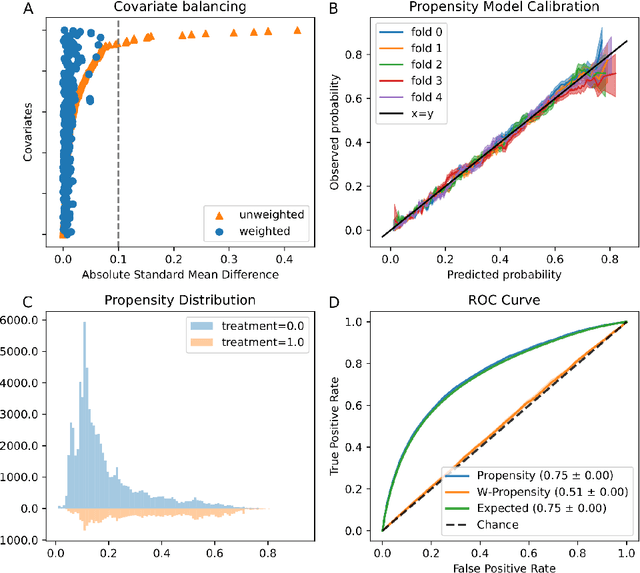
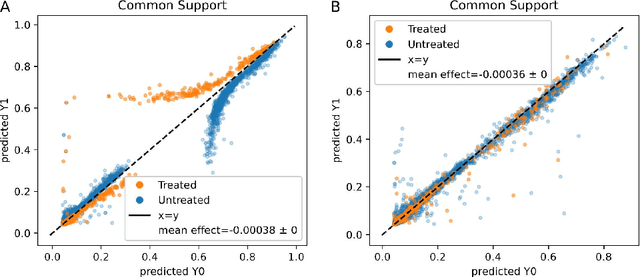
Real world observational data, together with causal inference, allow the estimation of causal effects when randomized controlled trials are not available. To be accepted into practice, such predictive models must be validated for the dataset at hand, and thus require a comprehensive evaluation toolkit, as introduced here. Since effect estimation cannot be evaluated directly, we turn to evaluating the various observable properties of causal inference, namely the observed outcome and treatment assignment. We developed a toolkit that expands established machine learning evaluation methods and adds several causal-specific ones. Evaluations can be applied in cross-validation, in a train-test scheme, or on the training data. Multiple causal inference methods are implemented within the toolkit in a way that allows modular use of the underlying machine learning models. Thus, the toolkit is agnostic to the machine learning model that is used. We showcase our approach using a rheumatoid arthritis cohort (consisting of about 120K patients) extracted from the IBM MarketScan(R) Research Database. We introduce an iterative pipeline of data definition, model definition, and model evaluation. Using this pipeline, we demonstrate how each of the evaluation components helps drive model selection and refinement of data extraction criteria in a way that provides more reproducible results and ensures that the causal question is answerable with available data. Furthermore, we show how the evaluation toolkit can be used to ensure that performance is maintained when applied to subsets of the data, thus allowing exploration of questions that move towards personalized medicine.