 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
Phi-3 Safety Post-Training: Aligning Language Models with a "Break-Fix" Cycle
Jul 18, 2024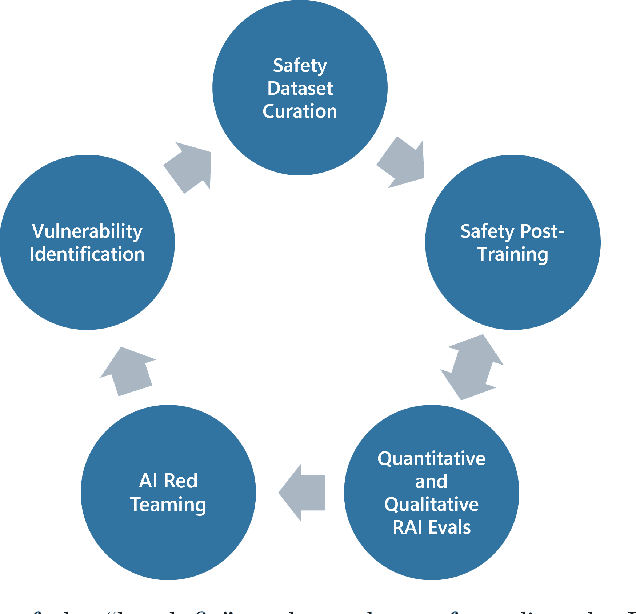


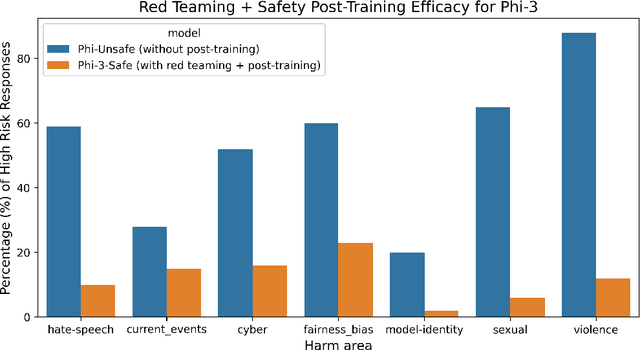
Recent innovations in language model training have demonstrated that it is possible to create highly performant models that are small enough to run on a smartphone. As these models are deployed in an increasing number of domains, it is critical to ensure that they are aligned with human preferences and safety considerations. In this report, we present our methodology for safety aligning the Phi-3 series of language models. We utilized a "break-fix" cycle, performing multiple rounds of dataset curation, safety post-training, benchmarking, red teaming, and vulnerability identification to cover a variety of harm areas in both single and multi-turn scenarios. Our results indicate that this approach iteratively improved the performance of the Phi-3 models across a wide range of responsible AI benchmarks.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
Disease Progression Modeling Workbench 360
Jun 24, 2021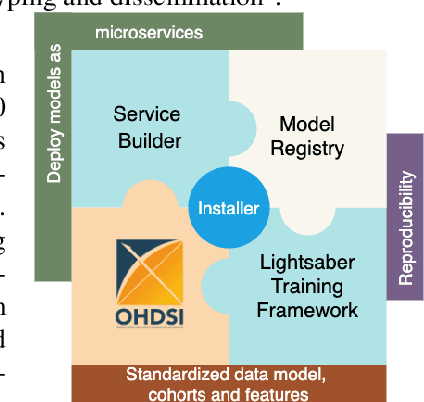
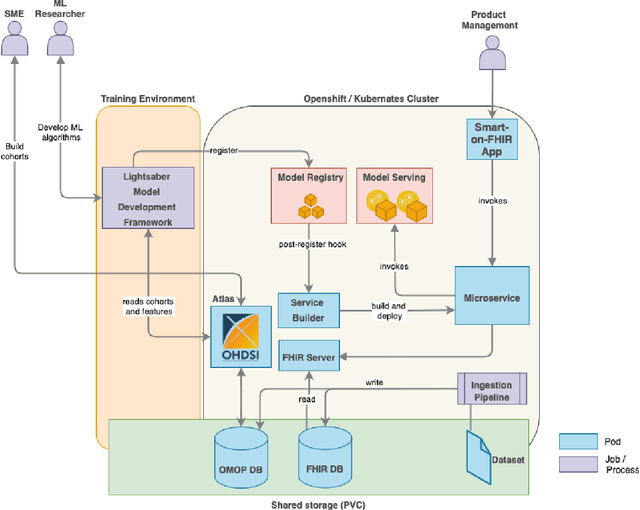
In this work we introduce Disease Progression Modeling workbench 360 (DPM360) opensource clinical informatics framework for collaborative research and delivery of healthcare AI. DPM360, when fully developed, will manage the entire modeling life cycle, from data analysis (e.g., cohort identification) to machine learning algorithm development and prototyping. DPM360 augments the advantages of data model standardization and tooling (OMOP-CDM, Athena, ATLAS) provided by the widely-adopted OHDSI initiative with a powerful machine learning training framework, and a mechanism for rapid prototyping through automatic deployment of models as containerized services to a cloud environment.
Blending Knowledge in Deep Recurrent Networks for Adverse Event Prediction at Hospital Discharge
Apr 09, 2021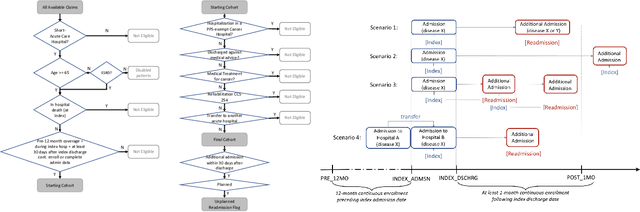
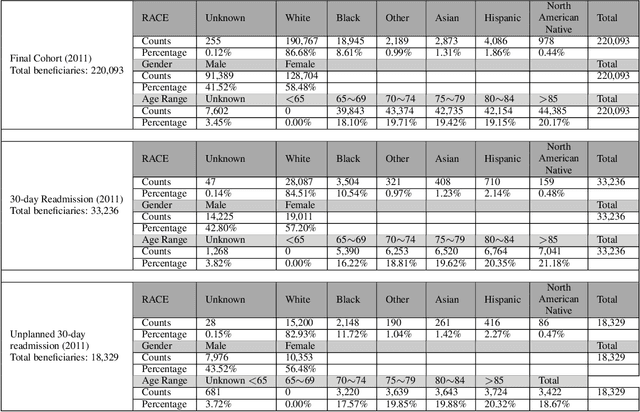
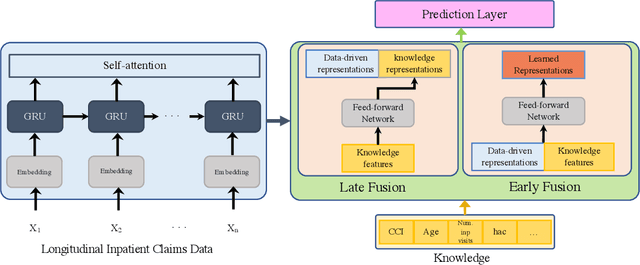

Deep learning architectures have an extremely high-capacity for modeling complex data in a wide variety of domains. However, these architectures have been limited in their ability to support complex prediction problems using insurance claims data, such as readmission at 30 days, mainly due to data sparsity issue. Consequently, classical machine learning methods, especially those that embed domain knowledge in handcrafted features, are often on par with, and sometimes outperform, deep learning approaches. In this paper, we illustrate how the potential of deep learning can be achieved by blending domain knowledge within deep learning architectures to predict adverse events at hospital discharge, including readmissions. More specifically, we introduce a learning architecture that fuses a representation of patient data computed by a self-attention based recurrent neural network, with clinically relevant features. We conduct extensive experiments on a large claims dataset and show that the blended method outperforms the standard machine learning approaches.
WNTRAC: Artificial Intelligence Assisted Tracking of Non-pharmaceutical Interventions Implemented Worldwide for COVID-19
Sep 16, 2020



The Coronavirus disease 2019 (COVID-19) global pandemic has transformed almost every facet of human society throughout the world. Against an emerging, highly transmissible disease with no definitive treatment or vaccine, governments worldwide have implemented non-pharmaceutical intervention (NPI) to slow the spread of the virus. Examples of such interventions include community actions (e.g. school closures, restrictions on mass gatherings), individual actions (e.g. mask wearing, self-quarantine), and environmental actions (e.g. public facility cleaning). We present the Worldwide Non-pharmaceutical Interventions Tracker for COVID-19 (WNTRAC), a comprehensive dataset consisting of over 6,000 NPIs implemented worldwide since the start of the pandemic. WNTRAC covers NPIs implemented across 261 countries and territories, and classifies NPI measures into a taxonomy of sixteen NPI types. NPI measures are automatically extracted daily from Wikipedia articles using natural language processing techniques and manually validated to ensure accuracy and veracity. We hope that the dataset is valuable for policymakers, public health leaders, and researchers in modeling and analysis efforts for controlling the spread of COVID-19.
A Canonical Architecture For Predictive Analytics on Longitudinal Patient Records
Jul 24, 2020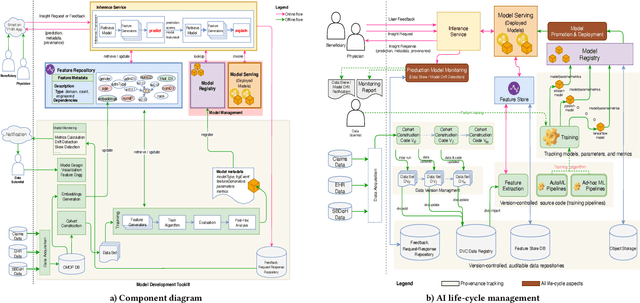
Many institutions within the healthcare ecosystem are making significant investments in AI technologies to optimize their business operations at lower cost with improved patient outcomes. Despite the hype with AI, the full realization of this potential is seriously hindered by several systemic problems, including data privacy, security, bias, fairness, and explainability. In this paper, we propose a novel canonical architecture for the development of AI models in healthcare that addresses these challenges. This system enables the creation and management of AI predictive models throughout all the phases of their life cycle, including data ingestion, model building, and model promotion in production environments. This paper describes this architecture in detail, along with a qualitative evaluation of our experience of using it on real world problems.
Interpretable Multi-Objective Reinforcement Learning through Policy Orchestration
Sep 21, 2018
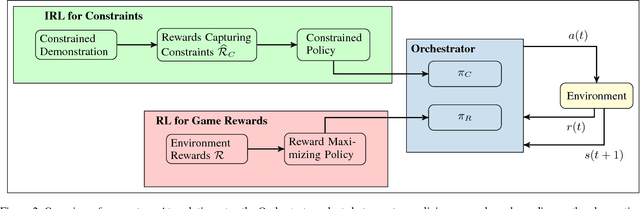
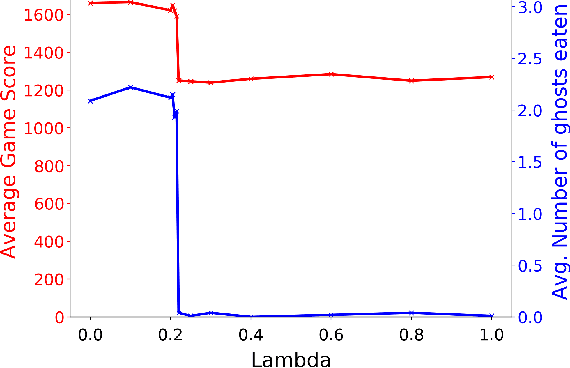
Autonomous cyber-physical agents and systems play an increasingly large role in our lives. To ensure that agents behave in ways aligned with the values of the societies in which they operate, we must develop techniques that allow these agents to not only maximize their reward in an environment, but also to learn and follow the implicit constraints of society. These constraints and norms can come from any number of sources including regulations, business process guidelines, laws, ethical principles, social norms, and moral values. We detail a novel approach that uses inverse reinforcement learning to learn a set of unspecified constraints from demonstrations of the task, and reinforcement learning to learn to maximize the environment rewards. More precisely, we assume that an agent can observe traces of behavior of members of the society but has no access to the explicit set of constraints that give rise to the observed behavior. Inverse reinforcement learning is used to learn such constraints, that are then combined with a possibly orthogonal value function through the use of a contextual bandit-based orchestrator that picks a contextually-appropriate choice between the two policies (constraint-based and environment reward-based) when taking actions. The contextual bandit orchestrator allows the agent to mix policies in novel ways, taking the best actions from either a reward maximizing or constrained policy. In addition, the orchestrator is transparent on which policy is being employed at each time step. We test our algorithms using a Pac-Man domain and show that the agent is able to learn to act optimally, act within the demonstrated constraints, and mix these two functions in complex ways.
Effect of secular trend in drug effectiveness study in real world data
Aug 18, 2018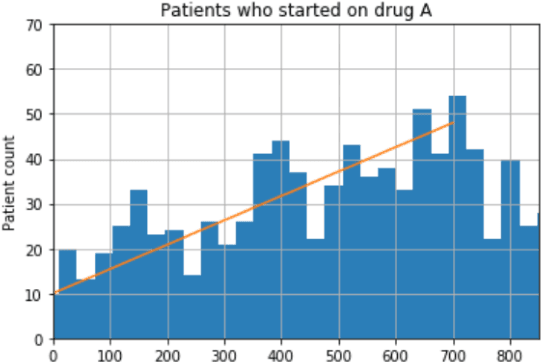
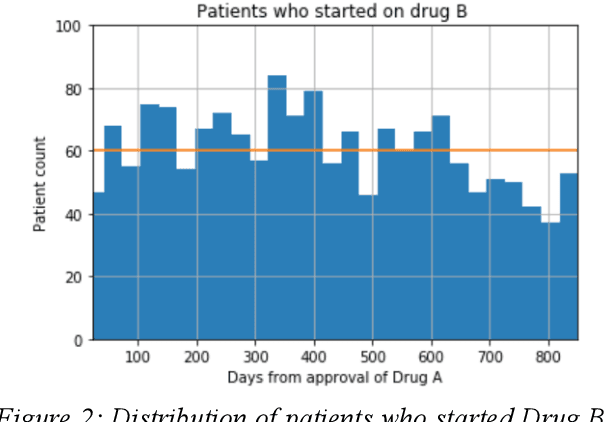
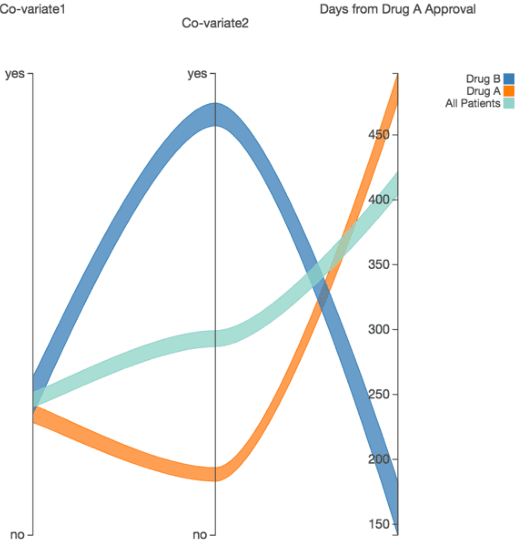
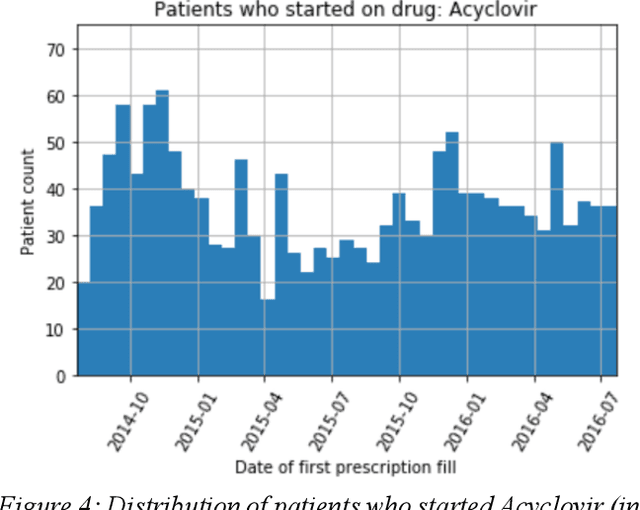
We discovered secular trend bias in a drug effectiveness study for a recently approved drug. We compared treatment outcomes between patients who received the newly approved drug and patients exposed to the standard treatment. All patients diagnosed after the new drug's approval date were considered. We built a machine learning causal inference model to determine patient subpopulations likely to respond better to the newly approved drug. After identifying the presence of secular trend bias in our data, we attempted to adjust for the bias in two different ways. First, we matched patients on the number of days from the new drug's approval date that the patient's treatment (new or standard) began. Second, we included a covariate in the model for the number of days between the date of approval of the new drug and the treatment (new or standard) start date. Neither approach completely mitigated the bias. Residual bias we attribute to differences in patient disease severity or other unmeasured patient characteristics. Had we not identified the secular trend bias in our data, the causal inference model would have been interpreted without consideration for this underlying bias. Being aware of, testing for, and handling potential bias in the data is essential to diminish the uncertainty in AI modeling.